Ландшафт данных стремительно развивается, и объем ежедневно создаваемых и распространяемых данных просто поражает воображение. Согласно отчету Statista, в настоящее время существует около 120 зеттабайт данных (по состоянию на 2023 год), и, по прогнозам, к 2025 году это число достигнет 181 зеттабайта.
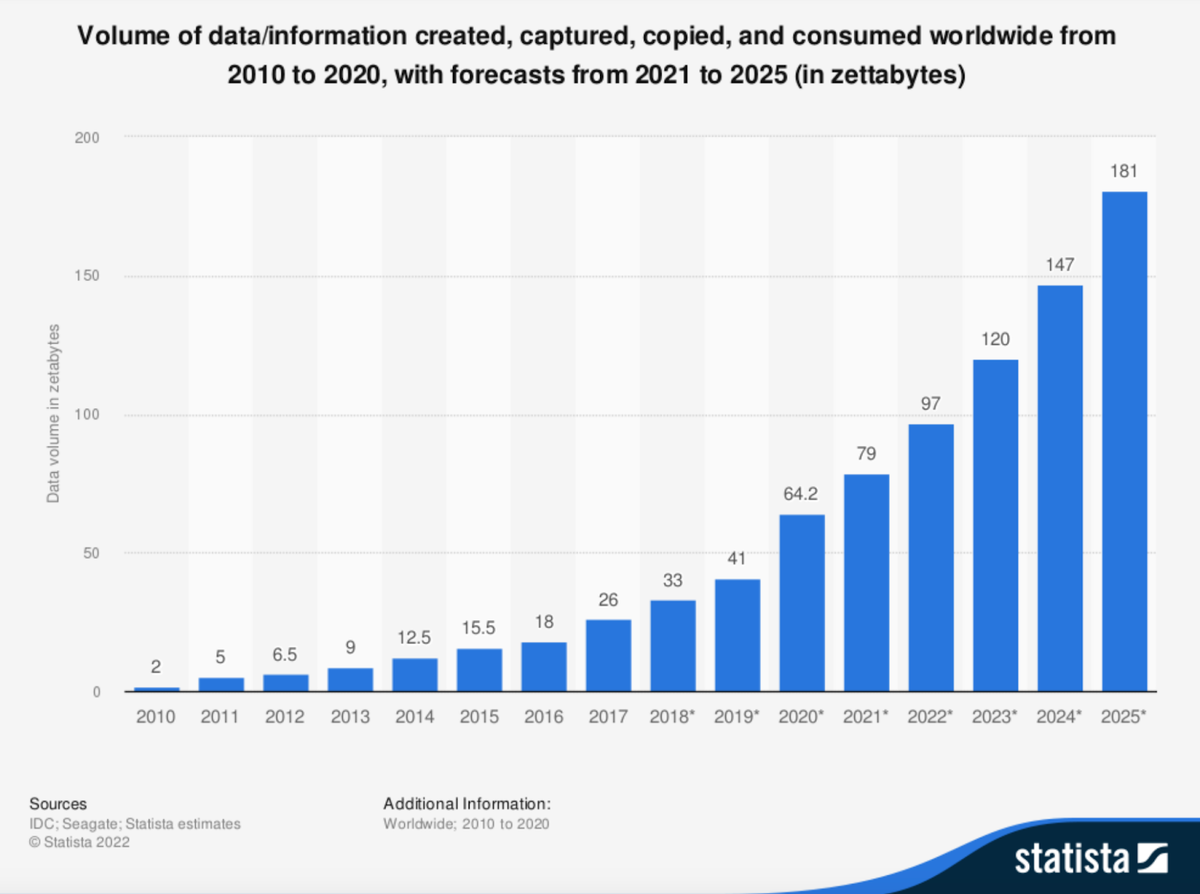
Объем данных, созданных и потребленных во всем мире с 2010 по 2020 год, с прогнозами на 2021-2025 годы (в зеттабайтах). (Источник: statista.com)
По мере того как объем данных продолжает стремительно расти, растет и спрос на эффективные решения и инструменты для управления данными и обеспечения их наблюдаемости. Действительная ценность данных заключается в том, как они используются.
Одного сбора и хранения данных недостаточно; их необходимо правильно использовать, чтобы получить ценные сведения. Эти данные могут варьироваться от демографических показателей до поведения потребителей и даже прогнозов будущих продаж, предоставляя беспрецедентный ресурс для процессов принятия решений в бизнесе. Кроме того, благодаря данным, получаемым в режиме реального времени, компании могут быстро принимать обоснованные решения, адаптироваться к рынку и использовать новые возможности. Однако это возможно только в том случае, если данные качественные, устаревшие, недостоверные или труднодоступные.
Именно здесь на помощь приходит DataOps , который играет решающую роль в оптимизации и рационализации процессов управления данными, включая использование инструментов DataOps.
Распаковка сущности DataOps
DataOps — это набор лучших практик и инструментов, направленных на улучшение взаимодействия, интеграции и автоматизации операций и задач по управлению данными. DataOps стремится улучшить качество, скорость и взаимодействие при управлении данными с помощью интегрированного и процессно-ориентированного подхода, используя автоматизацию и гибкие методы разработки программного обеспечения, аналогичные DevOps, для ускорения и оптимизации процесса предоставления точных данных [1].
Он призван помочь предприятиям и организациям лучше управлять своими конвейерами данных, снизить нагрузку и время, необходимые для разработки и развертывания новых приложений, основанных на данных, и повысить качество используемых данных.
Теперь, когда у нас есть четкое понимание того, что означает DataOps, давайте углубимся в его ключевые компоненты, включая основные инструменты DataOps для интеграции данных, управления качеством данных и их измерения, управления данными, оркестровки данных и DataOps Observability.
Интеграция данных
Интеграция данных включает в себя интеграцию и тестирование изменений кода и их оперативное развертывание в производственных средах, обеспечивая точность и согласованность данных по мере их интеграции и доставки соответствующим командам.
Управление качеством данных
Управление качеством данных включает в себя выявление, исправление и предотвращение ошибок и несоответствий в данных, обеспечивая высокую надежность и точность используемых данных.
Управление данными
Управление данными обеспечивает последовательный сбор, хранение и использование данных, соблюдение этических норм и соответствие нормативным требованиям.
Оркестровка данных
Оркестровка данных помогает управлять и координировать обработку данных в конвейере, определять и планировать задачи и устранять ошибки, чтобы автоматизировать и оптимизировать поток данных в конвейере данных. Это очень важно для обеспечения бесперебойной работы и производительности данных в конвейере данных.

Наблюдаемость DataOps
Наблюдаемость DataOps — это способность контролировать и понимать различные процессы и системы, участвующие в управлении данными, с главной целью обеспечить надежность, достоверность и ценность данных для бизнеса. Это включает в себя все: от мониторинга и анализа конвейеров данных до поддержания качества данных и подтверждения их ценности для бизнеса с помощью показателей финансовой и операционной эффективности.
Наблюдаемость DataOps позволяет предприятиям и организациям повысить эффективность процессов управления данными и более эффективно использовать свои информационные активы. Она помогает обеспечить постоянную корректность, надежность и доступность данных, что, в свою очередь, помогает предприятиям и организациям принимать решения на основе данных, оптимизировать расходы/затраты, связанные с данными, и получать от них больше пользы.
Лучшие инструменты DataOps для упрощения процессов управления данными, затрат и совместной работы
Одним из самых сложных аспектов DataOps является интеграция данных из различных источников и обеспечение качества данных, оркестровки, наблюдаемости, управления стоимостью данных и управления. DataOps нацелена на рационализацию этих процессов и улучшение взаимодействия между командами, что позволяет компаниям принимать более эффективные решения на основе данных и добиваться повышения производительности и результатов [2].
В этой статье мы сосредоточимся на наблюдаемости DataOps и основных инструментах DataOps, которые компании могут использовать для оптимизации процессов управления данными, расходами и совместной работы.
На рынке представлено множество инструментов DataOps, и выбор подходящего может оказаться очень сложной задачей. Чтобы помочь компаниям принять взвешенное решение, в этой статье мы составили список лучших инструментов DataOps, которые можно использовать для управления процессами, основанными на данных.
Инструменты интеграции данных
1) Fivetran
Fivetran — это очень популярная и широко распространенная платформа интеграции данных, которая упрощает процесс подключения различных источников данных к централизованному хранилищу данных [3]. Это позволяет пользователям или компаниям легко анализировать и визуализировать свои данные в одном месте, устраняя необходимость вручную извлекать, преобразовывать и загружать (ETL) данные из множества различных источников.
Fivetran предоставляет наборы готовых коннекторов для широкого спектра источников данных, включая популярные базы данных, облачные приложения, приложения SaaS и даже плоские файлы. Эти коннекторы автоматизируют процесс извлечения данных, гарантируя, что данные всегда будут актуальными, свежими и точными. Как только данные попадают в центральное хранилище данных, Fivetran выполняет обнаружение схемы и проверку данных, автоматически создавая таблицы и столбцы в хранилище данных на основе структуры источника данных, что позволяет легко настраивать и поддерживать конвейеры данных без необходимости вручную писать пользовательский код.
Fivetran также предлагает такие функции, как дедупликация данных, инкрементное обновление данных и репликация данных в режиме реального времени. Эти функции позволяют гарантировать, что данные всегда будут полными, свежими и точными.
Как функции Fivetran управляют данными. (Источник: fivetran.com) — Оптимизация затрат на Snowflake
2) Talend Data Fabric
РешениеTalend Data Fabric призвано помочь предприятиям и организациям обеспечить здоровые данные, чтобы сохранить контроль над ними, снизить риски и получить огромную прибыль. Платформа объединяет интеграцию, целостность и управление данными, обеспечивая надежные данные, на которые предприятия и организации могут полагаться в процессе принятия решений. Talend помогает компаниям повышать лояльность клиентов, улучшать операционную эффективность и модернизировать ИТ-инфраструктуру.
Уникальный подход Talend к интеграции данных позволяет предприятиям и организациям легко объединять данные из различных источников и принимать все необходимые бизнес-решения. Она позволяет интегрировать практически любые типы данных из любого источника в любой пункт назначения данных (локальный или облачный). Платформа отличается гибкостью, что позволяет предприятиям и организациям создавать конвейеры данных один раз и запускать их в любом месте, без привязки к поставщику или платформе. Кроме того, решение представляет собой «все в одном» (унифицированное решение), объединяющее интеграцию данных, качество данных и обмен данными на простой в использовании платформе.
Data Fabric от Talend предлагает множество лучших в своем классе возможностей интеграции данных, таких как интеграция данных, конструктор конвейеров, инвентаризация данных, подготовка данных, сбор данных об изменениях и сшивание данных. Эти инструменты делают интеграцию данных, обнаружение/поиск данных и обмен данными более управляемыми, позволяя пользователям быстро подготавливать и интегрировать данные, визуализировать их, сохранять их свежесть и безопасно перемещать.
Talend (Источник: talend.com) — оптимизация затрат на Snowflake
3) StreamSets
StreamSets — это мощная платформа интеграции данных, которая позволяет компаниям контролировать и управлять потоком данных из различных пакетных и потоковых источников в современные аналитические платформы. Вы можете развертывать и масштабировать потоки данных на границе, в помещениях или в облаке, используя совместную визуальную схему конвейера, а также отображать и контролировать их для обеспечения сквозной видимости[4]. Платформа также позволяет применять соглашения об уровне обслуживания данных для обеспечения высокой доступности, качества и конфиденциальности. StreamSets позволяет предприятиям и организациям быстро запускать проекты, устраняя необходимость в специальных навыках кодирования благодаря визуальным функциям проектирования, тестирования и развертывания трубопроводов, доступным через интуитивно понятный графический интерфейс пользователя. С StreamSets хрупкие трубопроводы и потерянные данные больше не будут проблемой, поскольку платформа может автоматически справляться с неожиданными изменениями. Платформа также включает в себя живую карту с метриками, оповещениями и функцией углубления, позволяя предприятиям эффективно интегрировать данные.
StreamSets (Источник: streamsets.com) — оптимизация затрат на снежинки
4) K2View
K2View предоставляет инструменты DataOps корпоративного уровня. Она предлагает платформу data fabric для интеграции данных в режиме реального времени, что позволяет предприятиям и организациям предоставлять персонализированный опыт [6]. Средства интеграции данных корпоративного уровня K2View интегрируют данные из любых источников и делают их доступными для любого потребителя с помощью различных методов, таких как массовый ETL, обратный ETL, потоковая передача данных, виртуализация данных, CDC на основе журналов, интеграция на основе сообщений, SQL и API.
K2View может получать данные из различных источников и систем, улучшать их в режиме реального времени, преобразовывать их в запатентованную микробазу данных, обеспечивать производительность, масштабируемость и безопасность путем сжатия и шифрования микробазы данных по отдельности. Затем она применяет инструменты маскировки, трансформации, обогащения и оркестровки данных»на лету», чтобы сделать данные доступными для авторизованных потребителей в любом формате, соблюдая при этом правила конфиденциальности и безопасности данных.
K2VIEW (Источник: k2view.com) — оптимизация затрат на снежинки
5) Alteryx
Alteryx — это очень мощная платформа интеграции данных, которая позволяет пользователям легко получать доступ, манипулировать, анализировать и выводить данные. Платформа использует интерфейс drag-and-drop (интерфейс с низким содержанием кода/без кода) и включает в себя множество инструментов и коннекторов(80) для смешивания данных, предиктивной аналитики и визуализации данных[7]. Его можно использовать разово или, что более распространено, как повторяющийся процесс, называемый «рабочим процессом» То, как Alteryx строит рабочие процессы, также служит формой документации процесса, позволяя пользователям просматривать, сотрудничать, поддерживать и улучшать процесс. Платформа может читать и записывать данные в файлы, базы данных и API, а также включает в себя функции прогнозной аналитики и геопространственного анализа. В настоящее время Alteryx используется в различных отраслях промышленности и функциональных областях и может применяться для более быстрой и эффективной автоматизации процессов интеграции данных. Среди распространенных вариантов использования — объединение и манипулирование данными в электронных таблицах, дополнение к разработке SQL, API, облачный или гибридный доступ, наука о данных, геопространственный анализ, а также создание отчетов и информационных панелей.
Примечание: Alteryx часто сравнивают с инструментами ETL, но важно помнить, что его основная аудитория — это аналитики данных. Цель Alteryx — расширить возможности бизнес-пользователей, предоставив им свободу доступа, манипулирования и анализа данных, не прибегая к помощи ИТ.
Alteryx (Источник: alteryx.com) — Оптимизация затрат на снежинки
Инструменты тестирования и мониторинга качества данных
1) Monte Carlo
Monte Carlo — ведущая платформа для мониторинга и наблюдения за корпоративными данными. Она предоставляет комплексное решение для мониторинга и оповещения о проблемах с данными в хранилищах данных, озерах данных, ETL и платформах бизнес-аналитики. Она использует машинное обучение и искусственный интеллект для изучения данных и проактивного выявления проблем, связанных с данными, оценки их влияния и оповещения тех, кто должен знать об этом. Автоматическое и немедленное выявление первопричины проблем позволяет командам быстрее сотрудничать и решать проблемы, а также обеспечивает автоматическую привязку к полям, обнаружение данных и централизованную каталогизацию данных, что позволяет командам лучше понимать доступность, местоположение, состояние и принадлежность своих информационных активов. Платформа разработана с учетом требований безопасности, соответствующим образом масштабируется с предоставляемым стеком и включает в себя возможность внедрения без кода или с низким кодом (code-free) для простого внедрения с существующим стеком данных.
Monte Carlo (Источник: montecarlodata.com) — оптимизация затрат на снежинки
2) Databand
Databand — это платформа мониторинга и наблюдения за данными, недавно приобретенная IBM, которая помогает организациям обнаруживать и устранять проблемы с данными до того, как они повлияют на бизнес. Платформа обеспечивает комплексный сквозной обзор конвейеров данных, начиная с исходных данных, что позволяет предприятиям и организациям обнаруживать и устранять проблемы на ранней стадии, сокращая среднее время обнаружения (MTTD) и среднее время решения (MTTR) с дней и недель до минут.
Одной из ключевых особенностей Databand является способность автоматически собирать метаданные из современных стеков данных, таких как Airflow, Spark, Databricks, Redshift, dbt и Snowflake. Эти метаданные используются для построения исторических базовых показателей общего поведения конвейера данных, что позволяет организациям получить представление о каждом потоке данных от источника до места назначения.
Оптимизация затрат на Snowflake
Databand также обеспечивает управление инцидентами, сквозной трассировкой, мониторинг надежности данных, метрики качества данных, обнаружение аномалий, а также возможности оповещения и маршрутизации DataOps. Благодаря этому предприятия и организации могут повысить надежность и качество данных и визуализировать, как инциденты с данными влияют на компоненты стека данных, расположенные выше и ниже по течению. Совокупность возможностей Databand обеспечивает единое решение для всех инцидентов с данными, позволяя инженерам сосредоточиться на создании современного стека данных, а не на его исправлении.
3) Data Fold
Datafold — это платформа для обеспечения надежности данных, ориентированная на проактивное управление качеством данных, которая помогает компаниям предотвратить катастрофы с данными. Она обладает уникальной способностью обнаруживать, оценивать и исследовать проблемы качества данных до того, как они повлияют на производительность. Платформа предлагает мониторинг в режиме реального времени, что позволяет быстро выявлять проблемы и предотвращать их превращение в катастрофы данных.
Приборная панель Datafold. (Источник: datafold.com) — Оптимизация затрат на снежинки
Datafold использует возможности машинного обучения и искусственного интеллекта для обеспечения аналитиков информацией в режиме реального времени, позволяя инженерам по обработке данных делать высококачественные прогнозы на основе больших объемов данных.
Некоторые из ключевых особенностей Datafold включают:
- Видимость потока данных во всех конвейерах и BI-отчетах
Datafold предлагает простой, но интуитивно понятный пользовательский интерфейс (UI) и навигацию с мощными функциями. Платформа позволяет глубоко изучить взаимосвязь между таблицами и массивами данных. Визуализации действительно очень просты для понимания. Мониторинг качества данных также очень гибкий. Однако количество поддерживаемых интеграций данных относительно ограничено.
4) Query Surge
QuerySurge — это очень мощный/универсальный инструмент для автоматизации тестирования и мониторинга качества данных, особенно для больших данных, хранилищ данных, BI-отчетов и приложений корпоративного уровня. Он разработан специально для бесшовной интеграции, позволяющей непрерывно тестировать и проверять данные по мере их поступления.
Query Surge также предоставляет возможность создавать и запускать тесты без необходимости написания SQL с помощью интеллектуальных мастеров запросов. Это позволяет проводить сравнения на уровне столбцов, таблиц и строк, а также автоматически сопоставлять столбцы. Кроме того, пользователи могут создавать пользовательские тесты, которые можно модулировать с помощью многократно используемых «фрагментов» кода, устанавливать пороговые значения, проверять типы данных и выполнять другие расширенные проверки. QuerySurge также имеет надежные возможности планирования, позволяющие пользователям запускать тесты немедленно, в указанную дату и время. Кроме того, QuerySurge поддерживает 200 поддерживаемых поставщиков и технологических стеков, что позволяет тестировать самые разные платформы, включая большие озера данных, хранилища данных, традиционные базы данных, хранилища документов NoSQL, отчеты BI, плоские файлы, файлы JSON и многое другое.
Query Surge (Источник: querysurge.com) — оптимизация затрат на Snowflake
Одним из ключевых преимуществ QuerySurge является его способность интегрироваться с другими решениями в конвейере DataOps, такими как решения по интеграции данных/ETL, решения по сборке/конфигурации, решения по управлению QA и тестированием. Инструмент также включает панель Data Analytics Dashboard, которая позволяет пользователям отслеживать ход выполнения тестов в режиме реального времени, углубляться в данные для изучения результатов и просматривать статистику выполненных тестов. Кроме того, инструмент имеет встроенную интеграцию с множеством сервисов и любыми другими решениями, имеющими доступ к API.
QuerySurge доступен как в локальной, так и в облачной среде, поддерживает 256-битное шифрование AES, LDAP/LDAPS, TLS, HTTPS/SSL, автоотключение и другие функции безопасности. Одним словом, QuerySurge — это очень мощное и комплексное решение для автоматизации мониторинга и тестирования данных, позволяющее предприятиям и организациям быстро повысить качество данных и снизить риск возникновения проблем с данными на этапе доставки.
5) Right Data
RDT от Right Data — это мощная платформа для тестирования и мониторинга данных, которая помогает предприятиям и организациям повысить надежность и доверие к своим данным, предоставляя простой в использовании интерфейс для тестирования, согласования и проверки данных. Она позволяет пользователям быстро выявлять проблемы, связанные с согласованностью, качеством и полнотой данных. Кроме того, это эффективный способ анализа, проектирования, создания, выполнения и автоматизации сценариев сверки и проверки данных, практически не требующий кодирования, что позволяет экономить время и ресурсы.
Right Data (Источник: getrightdata.com/RDt-product) — оптимизация затрат на Snowflake
Ключевые особенности RDT:
- Возможность анализа БД: предоставляет полный набор приложений для анализа исходных и целевых наборов данных. Его первоклассные функции Query Builder и Data Profiling помогают пользователям понять и проанализировать данные, прежде чем использовать соответствующие наборы данных в различных сценариях.
- Поддержка широкого спектра источников данных: RDT поддерживает широкий спектр источников данных, таких как ODBC или JDBC, плоские файлы, облачные технологии, SAP, большие данные, отчеты BI и различные другие источники. Это позволяет предприятиям и организациям легко подключаться к существующим источникам данных и работать с ними.
- Согласование данных: В RDT есть такие функции, как «Сравнение количества строк», которые позволяют пользователям сравнивать количество строк в исходном и целевом наборе данных и находить таблицы, в которых количество строк не совпадает. Также имеется функция «Сравнение данных на уровне строк», которая сравнивает наборы данных между источником и целью и выявляет строки, которые не совпадают друг с другом.
- Валидация данных: RDT предоставляет удобный интерфейс для создания сценариев проверки, что позволяет пользователям устанавливать одно или несколько правил проверки для целевых наборов данных, выявлять исключения, анализировать результаты и создавать отчеты.
- Администратор и CMS: RDT имеет консоль администратора, которая позволяет администратору управлять и настраивать функции инструмента. Консоль предоставляет возможность создавать пользователей, управлять ролями и сопоставлять роли с конкретными пользователями. Администраторы также могут создавать, управлять и тестировать профили соединений, которые используются для создания запросов. Инструмент также предоставляет студию управления контентом (CMS), которая позволяет экспортировать запросы, сценарии и профили соединений из одного экземпляра RightData в другой. Эта функция полезна для копирования внутри одного экземпляра из одной папки в другую, а также для переключения профиля подключения запросов.
Наблюдаемость DataOps и расширенный FinOps
1) Chaos Genius
Chaos Genius — это мощный инструмент DataOps Observability, который использует ML и AI для обеспечения точных прогнозов затрат и расширенных показателей для мониторинга и анализа данных и бизнес-показателей. Одной из основных причин создания этого инструмента было стремление принести пользу бизнесу, предложив мощный, первый в своем классе инструмент наблюдения DataOps, который поможет контролировать и анализировать данные, снизить расходы и улучшить бизнес-показатели. Инструмент использует машинное обучение и искусственный интеллект (ML/AI), чтобы просеивать данные и предоставлять более точную оценку затрат и улучшенные метрики.
Chaos Genius (Источник: chaosgenius.io)
В настоящее время Chaos Genius предлагает услугу под названием «Наблюдение за снежинками» в качестве одной из своих основных услуг.
Chaos Genius Snowflake Observability (Источник: chaosgenius.io)
Ключевые особенности Chaos Genius (Snowflake Observability) включают:
- Оптимизация и мониторинг расходов: Chaos Genius призван помочь предприятиям и организациям оптимизировать и контролировать расходы на Снежинку. Это включает в себя поиск мест, где можно сократить расходы на Snowflake, и подготовку предложений о том, как это сделать, тем самым повышая рентабельность инвестиций в Snowflake.
- Повышение производительности запросов: Chaos Genius может анализировать шаблоны запросов для выявления неэффективных запросов и давать разумные рекомендации по улучшению их производительности, что может привести к более быстрому и эффективному получению данных и повышению общей производительности хранилища данных.
- Сокращение расходов: Chaos Genius позволяет предприятиям повысить эффективность своих систем и сократить общие расходы примерно на ~10-30 %.
- Доступность: Chaos Genius предлагает доступную модель ценообразования с тремя уровнями. Первый уровень полностью бесплатный, а два других — это бизнес-ориентированные планы для компаний, которые хотят отслеживать больше показателей. Это делает его доступным для предприятий любого размера и бюджета.
2) Unravel
Unravel — это платформа наблюдаемости DataOps, которая обеспечивает предприятиям и организациям тщательный обзор всего стека данных и помогает им оптимизировать производительность, автоматизировать устранение неполадок, а также управлять и контролировать стоимость всех конвейеров данных. Платформа также предназначена для работы с различными поставщиками облачных услуг, например, Azure, Amazon EMR, GCP, Cloudera и даже с локальными средами, обеспечивая предприятиям гибкость в управлении конвейером данных независимо от места их размещения.
Unravel Data (Источник: unraveldata.com)
Unravel использует возможности машинного обучения и искусственного интеллекта для моделирования конвейеров данных от конца до конца, обеспечивая предприятиям детальное понимание того, как данные проходят через их системы. Это позволяет предприятиям/организациям выявлять «узкие места», оптимизировать распределение ресурсов и повышать общую производительность своих конвейеров данных.
Модель данных платформы позволяет компаниям исследовать, коррелировать и анализировать данные по всей среде, обеспечивая глубокое понимание того, как используются приложения, сервисы и ресурсы, что работает, а что нет, что позволяет компаниям быстро выявлять потенциальные проблемы и принимать немедленные меры по их устранению. Кроме того, Unravel обладает функциями автоматического устранения неполадок, которые помогают предприятиям быстро найти причину проблемы и принять меры по ее устранению, что позволяет сэкономить огромные средства и сделать конвейеры данных более надежными и эффективными.
Инструменты оркестровки данных
1) Apache Airflow
Apache Airflow — это инструмент для оркестровки рабочих процессов DataOps с открытым исходным кодом, позволяющий программно создавать, планировать и контролировать рабочие процессы. Сначала его разработала компания Airbnb, а теперь он находится в собственности Apache Software Foundation [8]. Это инструмент для выражения и управления конвейерами данных, который часто используется в инженерии данных. Он позволяет пользователям определять, планировать и контролировать рабочие процессы в виде направленных ациклических графов (DAG) задач. Airflow предоставляет простой и мощный способ управления конвейерами данных, он прост в использовании, что позволяет пользователям быстро создавать и управлять сложными рабочими процессами; кроме того, он имеет большое и активное сообщество, которое предоставляет множество плагинов, коннекторов и интеграций с другими инструментами, что делает его очень универсальным.
Apache Airflow (Источник: airflow.apache.org)
Ключевые особенности Airflow включают:
- Динамическая генерация трубопроводов: Динамическая генерация трубопроводов — одна из ключевых особенностей Airflow. Airflow позволяет определять и генерировать трубопроводы программно, а не создавать и управлять ими вручную. Это облегчает создание и модификацию сложных рабочих процессов.
- Расширяемость: Airflow позволяет использовать пользовательские плагины, операторы и исполнители, что означает, что вы можете добавлять в платформу новые функции в соответствии с вашими конкретными потребностями и требованиями; это делает Airflow очень расширяемым и отличным выбором для предприятий и организаций с уникальными требованиями или работающих со сложными конвейерами данных.
- Масштабируемость: Airflow имеет встроенную поддержку масштабирования тысяч задач, что делает ее очень подходящей для крупных организаций или выполнения масштабных задач по обработке данных.
2) Shipyard
Shipyard — это мощный инструмент оркестровки данных, призванный помочь командам, работающим с данными, оптимизировать и упростить рабочие процессы и предоставлять данные с очень высокой скоростью. Инструмент не зависит от кода, что позволяет командам развертывать код на любом языке, который они предпочитают, и не требует сложного обучения. Он готов к работе в облаке, а значит, избавляет команды от необходимости тратить часы на настройку и управление серверами. Вместо этого они могут организовывать свои рабочие процессы в облаке, что позволяет им сосредоточиться на том, что они умеют делать лучше всего — работать с данными. Shipyard также может выполнять тысячи заданий одновременно, что делает его идеальным для масштабирования задач по обработке данных. Инструмент может динамически масштабироваться в зависимости от потребностей, обеспечивая бесперебойную и эффективную работу рабочих процессов даже при работе с большими объемами данных.
Shipyard (Источник: shipyardapp.com)
Shipyard имеет очень интуитивно понятный визуальный интерфейс, позволяющий пользователям создавать рабочие процессы прямо из интерфейса и вносить необходимые изменения путем перетаскивания. Расширенное планирование, веб-крючки и триггеры по требованию позволяют легко автоматизировать рабочие процессы по любому расписанию. Кроме того, Shipyard позволяет создавать кросс-функциональные рабочие процессы, что означает, что весь процесс обработки данных может быть взаимосвязан на протяжении всего жизненного цикла данных, помогая командам отслеживать весь путь данных, от сбора и обработки данных до визуализации и анализа.
Shipyard также предоставляет мгновенные уведомления, которые помогают командам обнаружить и устранить критические сбои еще до того, как кто-то их заметит. Кроме того, в нем предусмотрены автоматические повторные попытки и прерывания, которые обеспечивают устойчивость рабочих процессов, так что командам не нужно и пальцем шевелить. Кроме того, он позволяет выявить и устранить первопричину в режиме реального времени, так что команды могут восстановить работоспособность в считанные секунды. Кроме того, это решение позволяет командам подключить весь стек данных за считанные минуты, беспрепятственно перемещая данные между существующими инструментами в стеке данных, независимо от поставщика облачных услуг. Благодаря более чем 20 интеграциям и 60 шаблонам с низким содержанием кода на выбор команды, работающие с данными, могут подключить свои существующие инструменты в рекордно короткие сроки!!!
3) Dagster
Dagster — это платформа для оркестровки данных нового поколения с открытым исходным кодом для разработки, производства и наблюдения за активами данных в режиме реального времени. Ее основная цель — предоставить инженерам, специалистам по исследованию данных и разработчикам единый опыт управления всем жизненным циклом активов данных, от разработки и тестирования до производства и мониторинга. Используя Dagster, пользователи могут управлять своими активами данных с помощью кода и отслеживать «прогоны» всех заданий в одном месте с помощью представления временной шкалы прогонов. С другой стороны, представление подробностей выполнения позволяет пользователям увеличить масштаб выполнения и выявить проблемы с хирургической точностью.
Dagster также позволяет пользователям видеть контекст каждого актива и обновлять его в одном месте, включая материализации, линейку, схему, расписание, разделы и многое другое. Кроме того, в нем можно запускать и отслеживать обратные заполнения для каждого раздела данных. Dagster — это платформа оркестровки корпоративного уровня, в которой приоритет отдается опыту разработчиков (DX) благодаря полностью бессерверным гибридным развертываниям, нативным ветвлениям и готовой конфигурации CI/CD.
Dagster (Источник: dagster.io)
4) AWS glue
AWS Glue — это инструмент оркестровки данных, который позволяет легко обнаруживать, подготавливать и объединять данные для аналитики и процессов машинного обучения. С помощью Glue вы можете просматривать источники данных, извлекать, преобразовывать и загружать данные (ETL), а также создавать/планировать конвейеры данных, используя простой визуальный интерфейс UI. Glue также может использоваться для аналитики и включает инструменты для создания, выполнения заданий и реализации рабочих процессов. AWS Glue предлагает обнаружение данных, ETL, очистку и централизованную каталогизацию и позволяет подключаться к более чем 70 различным источникам данных [9]. Вы можете создавать, запускать и контролировать ETL-конвейеры для загрузки данных в озера данных и запрашивать каталогизированные данные с помощью Amazon Athena, Amazon EMR и Redshift Spectrum. Это бессерверное решение, то есть нет инфраструктуры, которой нужно управлять, и оно поддерживает все виды рабочих нагрузок, таких как ETL, ELT и потоковая обработка данных, собранные в одном сервисе. AWS Glue очень удобен в использовании и подходит для всех типов пользователей, включая разработчиков и бизнес-пользователей. Его способность масштабироваться по требованию позволяет пользователям сосредоточиться на важных видах деятельности, которые извлекают максимальную ценность из данных; он может работать с данными любого объема и поддерживать все типы данных и вариации схем.
AWS Glue (Источник: aws.amazon.com/glue)
AWS Glue предоставляет массу замечательных функций, которые можно использовать в рабочем процессе DataOps, например:
- Каталог данных: Центральное хранилище для хранения структурных и операционных метаданных для всех активов данных.
- Задания ETL: Возможность определять, планировать и запускать задания ETL для подготовки данных к аналитике.
- Data Crawlers: Автоматизированное обнаружение и классификация данных, позволяющие подключаться к источникам данных, извлекать метаданные и создавать определения таблиц в каталоге данных.
- Классификаторы данных: Способность распознавать и классифицировать конкретные типы данных, такие как JSON, CSV и Parquet.
- Data Wrangler: Визуальный инструмент преобразования данных, позволяющий легко очищать и подготавливать данные для аналитики.
- Безопасность: Интеграция с AWS Identity and Access Management (IAM) и Amazon Virtual Private Cloud (VPC) для обеспечения безопасности данных в пути и в состоянии покоя.
- Масштабируемость: Возможность работы с данными петабайтного масштаба и тысячами одновременных заданий ETL.
Инструменты управления данными
1) Collibra
Collibra — это ориентированный на предприятия инструмент управления данными, который помогает компаниям и организациям понимать и управлять своими активами данных. Он позволяет предприятиям и организациям создавать инвентаризацию активов данных, собирать метаданные о них и управлять этими активами для обеспечения соответствия нормативным требованиям. Инструмент в основном используется ИТ-специалистами, владельцами данных и администраторами, отвечающими за защиту данных и соответствие нормативным требованиям, для инвентаризации и отслеживания использования данных. Основная цель Collibra — защитить данные, обеспечить их надлежащее управление и использование, а также устранить потенциальные штрафы и риски, связанные с несоблюдением нормативных требований.
Collibra (Источник: collibra.com)
Collibra предлагает шесть ключевых функциональных областей для помощи в управлении данными:
- Collibra Data Quality & Observability: Мониторинг качества данных и надежности трубопроводов для устранения аномалий.
- Collibra Data Catalog: Единое решение для поиска и понимания данных из различных источников.
- Управление данными: Место для поиска, понимания и создания общего языка данных для всех сотрудников организации.
- Data Lineage: Автоматическое отображение взаимосвязей между системами, приложениями и отчетами для обеспечения комплексного представления данных в масштабах предприятия.
- Конфиденциальность данных: Централизует, автоматизирует и направляет рабочие процессы, способствуя сотрудничеству и выполняя глобальные нормативные требования к конфиденциальности данных.
2) Alation
Alation — это инструмент каталога данных корпоративного уровня, который служит единой точкой отсчета для всех данных организации. Он автоматически просматривает и индексирует более 60 различных источников данных, включая локальные базы данных, облачные хранилища, файловые системы и инструменты BI. Используя журнал запросов, Alation анализирует запросы, чтобы определить наиболее часто используемые данные и лиц, которые чаще всего их используют, что составляет основу каталога. Пользователи могут сотрудничать и предоставлять контекст для данных. С помощью каталога аналитики и ученые могут быстро и легко находить, изучать, проверять и повторно использовать данные, что повышает их производительность. Alation также может использоваться для управления данными, позволяя аналитикам эффективно управлять и применять политики для потребителей данных.
Alation (Источник: Alation)
Основные преимущества использования Alation:
- Повышение производительности аналитиков
- Улучшение понимания данных
- Содействие сотрудничеству
- Минимизация риска неправомерного использования данных
- Устранение узких мест в ИТ
- Легко раскрывать и интерпретировать политики данных
Alation предлагает различные решения для повышения производительности, точности и принятия решений на основе данных. К ним относятся:
- Alation Data Catalog: Повышает эффективность работы аналитиков и точность аналитики, позволяя всем членам организации эффективно находить, понимать и управлять данными.
- Alation Connectors: Широкий спектр собственных источников данных, которые ускоряют процесс получения информации и позволяют анализировать данные в масштабах всего предприятия. (Дополнительные источники данных также можно подключить с помощью Open Connector Framework SDK)
- Платформа Alation: Открытое и интеллектуальное решение для различных приложений управления метаданными, включая поиск и обнаружение, управление данными и цифровую трансформацию.
- Alation Data Governance App: Упрощает безопасный доступ к лучшим данным в гибридных и мультиоблачных средах.
- Облачный сервис Alation: Предоставляет предприятиям и организациям возможность самостоятельно управлять каталогом данных или получить его в облаке.
Облако данных и платформы для озер данных
1). Databricks
Databricks — это облачная платформа для создания озер, основанная в 2013 году создателями Apache Spark, Delta Lake и MlFlow [10]. Она объединяет хранилища данных и озера данных, предоставляя открытую и единую платформу для данных и искусственного интеллекта. Архитектура Databricks Lakehouse предназначена для управления всеми типами данных и не зависит от облака, что позволяет управлять данными, где бы они ни хранились. Команды могут сотрудничать и получать доступ ко всем данным, необходимым для инноваций и улучшений. Платформа включает в себя надежность и производительность Delta Lake в качестве основы для озера данных, тонкое управление и поддержку сценариев использования на основе персон. Она также обеспечивает мгновенные и бессерверные вычисления, управляемые Databricks. Платформа Lakehouse устраняет проблемы, связанные с традиционными средами данных, такими как изолированные данные и сложные структуры данных. Она простая, открытая, мультиоблачная и поддерживает различные рабочие нагрузки на группы данных. Платформа обеспечивает гибкость при использовании существующей инфраструктуры, проектов с открытым исходным кодом и партнерской сети Databricks.
Databricks (Источник: databricks.com)
2) Snowflake
Snowflake — это облачная платформа данных, предлагающая модель «программное обеспечение как услуга» для хранения и анализа больших объемов данных. Она разработана для поддержки высокого уровня параллелизма, масштабируемости и производительности. Она позволяет клиентам сосредоточиться на извлечении пользы из своих данных, а не на управлении инфраструктурой, в которой они хранятся. Компания была основана в 2012 году тремя специалистами — Бенуа Дашвилем, Тьерри Круанесом и Марцином Зуковски [11]. Snowflake работает поверх облачной инфраструктуры, такой как AWS, Microsoft Azure и облачные платформы Google. Она позволяет клиентам хранить и анализировать свои данные, используя эластичность облака, обеспечивая скорость, простоту использования, экономическую эффективность и масштабируемость. Она широко используется для хранилищ данных, озер данных и инженерии данных. Она разработана с учетом всех сложностей современных процессов управления данными. Кроме того, она поддерживает различные приложения для анализа данных, такие как BI-инструменты, ML/AI и наука о данных. Snowflake также произвела революцию в модели ценообразования, используя «модель использования», которая ориентирована на потребление пользователя в зависимости от того, вычисляет он данные или хранит их, что делает все более гибким и эластичным.
Snowflake (Источник: snowflake.com)
Ключевые особенности Snowflake включают:
- Облако-агностичность: Snowflake доступен у всех основных облачных провайдеров (AWS, GCP, AZURE), сохраняя при этом одинаковый пользовательский интерфейс, что позволяет легко интегрировать его в текущую облачную архитектуру.
- Автоматическое масштабирование Auto-Suspend: Snowflake автоматически запускает и останавливает кластеры во время ресурсоемкой обработки и останавливает виртуальные хранилища, когда они простаивают, для оптимизации затрат и производительности.
- Конкуренция и разделение рабочих нагрузок: Многокластерная архитектура Snowflake разделяет рабочие нагрузки для устранения проблем параллелизма и гарантирует, что запросы из одного виртуального хранилища не повлияют на другое.
- Нулевая конфигурация аппаратного и программного обеспечения: Snowflake не требует установки программного обеспечения, настройки или ввода в эксплуатацию оборудования, что упрощает его настройку и управление.
- Безопасность: Snowflake предлагает широкий спектр функций безопасности, включая сетевые политики, методы аутентификации и контроль доступа, для обеспечения безопасного доступа к данным и их хранения.
4) Google Bigquery
Google BigQuery — это полностью управляемое и бессерверное хранилище данных, предоставляемое Google Cloud, которое помогает организациям управлять и анализировать большие объемы данных с помощью встроенных функций, таких как машинное обучение, геопространственный анализ и бизнес-аналитика[12]. Оно позволяет предприятиям и организациям легко хранить, получать, накапливать, анализировать и визуализировать большие объемы данных. Bigquery рассчитана на работу с данными масштаба до петабайта и поддерживает SQL-запросы для анализа данных. Платформа также включает BigQuery ML, которая позволяет компаниям или пользователям обучать и выполнять модели машинного обучения на основе корпоративных данных без необходимости их перемещения.
BigQuery (Источник: cloud.google.com/bigquery)
BigQuery интегрируется с различными инструментами бизнес-аналитики и может быть легко доступен через облачную консоль, инструмент командной строки и даже API. Кроме того, он напрямую интегрирован со службой управления идентификацией и доступом Google Cloud, что позволяет безопасно обмениваться данными и аналитическими выкладками в разных организациях. С BigQuery компаниям приходится платить только за хранение данных, запросы и потоковую вставку. Загрузка и экспорт данных абсолютно бесплатны.
3) Amazon Redshift
Amazon Redshift — это облачный сервис хранения данных, позволяющий хранить и анализировать большие массивы данных. Он также полезен для миграции БОЛЬШИХ баз данных. Сервис полностью управляем и обеспечивает масштабируемость и экономическую эффективность при хранении и анализе больших объемов данных. В нем используется SQL для анализа структурированных и полуструктурированных данных из различных источников, включая хранилища данных, оперативные базы данных и озера данных, что обеспечивается аппаратными средствами, разработанными AWS, и поддержкой искусственного интеллекта и машинного обучения; благодаря этому он способен обеспечить оптимальную экономическую эффективность в любом масштабе. Сервис также обеспечивает высокую скорость работы и эффективные запросы для принятия бизнес-решений.
Amazon Redshift (Источник: Amazon Redshift)
Ключевые особенности Amazon Redshift включают:
- Высокая масштабируемость: Redshift позволяет пользователям начать с очень небольшого объема данных и масштабировать их до петабайта и более по мере постепенного увеличения объема данных.
- Производительность выполнения запросов: Redshift использует столбцовое хранение, расширенное сжатие и параллельное выполнение запросов для обеспечения высокой производительности запросов к большим наборам данных.
- Модель ценообразования с оплатой по факту: Redshift использует модель ценообразования с оплатой по факту использования и позволяет пользователям выбирать из нескольких типов и размеров узлов для оптимизации стоимости и производительности.
- Надежная безопасность: Redshift интегрируется с такими службами безопасности AWS, как AWS Identity and Access Management (IAM) и Amazon Virtual Private Cloud (VPC), и многое другое (подробнее здесь), чтобы обеспечить безопасность данных.
- Интеграция: Redshift легко интегрируется с различными другими сервисами, такими как Datacoral, Etleap, Fivetran, SnapLogic, Stitch, Upsolver, Matillion идругими.
- Инструменты управления мониторингом: Redshift имеет различные инструменты управления и мониторинга, включая Redshift Management Console и Redshift Query Performance Insights, которые помогают пользователям управлять и контролировать кластеры в хранилище данных.
Заключение
Поскольку объем данных продолжает расти беспрецедентными темпами, потребность в эффективных решениях для управления данными и наблюдения за ними как никогда высока. Но просто собирать и хранить данные не получится — важны те знания и ценности, которые они могут дать. Однако этого можно добиться, только если данные качественные, актуальные и легкодоступные. Именно здесь на помощь приходит DataOps — мощный набор лучших практик и инструментов DataOps для улучшения взаимодействия, интеграции и автоматизации, позволяющий компаниям оптимизировать конвейеры данных, снизить затраты и рабочую нагрузку, а также повысить качество данных. Таким образом, используя вышеупомянутые инструменты, предприятия могут минимизировать расходы, связанные с данными, и извлекать из них максимальную ценность.
Не позволяйте своим данным пропадать зря — используйте их мощь с помощью DataOps.
Вопросы и ответы
Каковы ключевые компоненты DataOps?
Основные компоненты DataOps включают интеграцию данных, управление качеством данных, управление данными, оркестровку данных и наблюдаемость DataOps.
Что такое наблюдаемость DataOps?
Наблюдаемость DataOps — это способность контролировать и понимать различные процессы и системы, участвующие в управлении данными, с главной целью обеспечить надежность, достоверность и ценность данных для бизнеса.
Что такое платформа DataOps?
Платформа DataOps — это инструмент или набор инструментов, позволяющий предприятиям внедрять практику DataOps и оптимизировать процессы управления данными.
Что такое методология DataOps?
Методология DataOps — это структурированный подход, который позволяет организациям создавать и развертывать аналитические системы и конвейеры данных, используя повторяющийся процесс. Она обеспечивает основу для эффективной и последовательной разработки и развертывания решений, основанных на данных.
Каковы преимущества DataOps?
- Улучшение взаимодействия
- Оптимизация процессов управления данными
- Повышенное качество данных
- Ускоренное принятие решений
- Оптимизация использования ресурсов
- Повышение операционной эффективности
Каковы недостатки DataOps?
- Первоначальные затраты на внедрение и настройку
- Необходимость наличия специальных навыков и опыта работы с определенными инструментами/платформами
- Применимость ограничена конкретными организациями и сценариями управления данными
Переведено с сайта Chaosgenius
Ссылки
[1]. A. Dyck, R. Penners and H. Lichter, «Towards Definitions for Release Engineering and DevOps,» 2015 IEEE/ACM 3rd International Workshop on Release Engineering, Florence, Italy, 2015, pp. 3-3, doi: 10.1109/RELENG.2015.10.
[2] Doyle, Kerry. “DataOps vs. MLOps: Streamline your data operations.” TechTarget, 15 February 2022, https://www.techtarget.com/searchitoperations/tip/DataOps-vs-MLOps-Streamline-your-data-operations. Accessed 12 January 2023.
[3] Danise, Amy, and Bruce Rogers. “Fivetran Innovates Data Integration Tools Market.” Forbes, 11 January 2022, https://www.forbes.com/sites/brucerogers/2022/01/11/fivetran-innovates-data-integration-tools-market/. Accessed 13 January 2023.
[4] Basu, Kirit. “What Is StreamSets? Data Engineering for DataOps.” StreamSets, 5 October 2015, https://streamsets.com/blog/what-is-streamsets/. Accessed 13 January 2023.
[5] Chand, Swatee. “What is Talend | Introduction to Talend ETL Tool.” Edureka, 29 November 2021, https://www.edureka.co/blog/what-is-talend-tool/#WhatIsTalend. Accessed 12 January 2023.
[6] “Delivering real-time data products to accelerate digital business [white paper].” K2View, https://www.k2view.com/hubfs/K2View%20Overview%202022.pdf. Accessed 13 January 2023.
[7] “Complete introduction to Alteryx.” GeeksforGeeks, 3 June 2022, https://www.geeksforgeeks.org/complete-introduction-to-alteryx/. Accessed 13 January 2023.
[8] “Apache Airflow: Use Cases, Architecture, and Best Practices.” Run:AI, https://www.run.ai/guides/machine-learning-operations/apache-airflow. Accessed 12 January 2023.
[9] “What is AWS Glue? — AWS Glue.” AWS Documentation, https://docs.aws.amazon.com/glue/latest/dg/what-is-glue.html. Accessed 13 January 2023.
[10] “About Databricks, founded by the original creators of Apache Spark™.” Databricks, https://www.databricks.com/company/about-us. Accessed 18 January 2023.
[11] “You’re never too old to excel: How Snowflake thrives with ‘dinosaur’ cofounders and a 60-year-old CEO.” LinkedIn, 4 September 2019, https://www.linkedin.com/pulse/youre-never-too-old-excel-how-snowflake-thrives-dinosaur-anders/. Accessed 18 January 2023.
[12] “What is BigQuery?” Google Cloud, https://cloud.google.com/bigquery/docs/introduction. Accessed 18 January 2023.