Приветствую тебя, мой уважаемый читатель!
Последние пару дней изучаю возможности проекта NLLB (анг. No Language Left Behind, что пафосно переводится как: ни один язык не остался позади), изучаю я его потому как мне нужно в рамках одного небольшо прототипа проекта RAG-системы интегрировать модуль перевода текста.

Ну и по ходу пьесы набралось некоторое количество заметок про NLLB, которыми я хотел бы поделиться.
Краткий обзор
Изучение этой темы начал тривиально, с прочтения постов на HuggingFace про NLLB и NLLB-MoE, затем прочёл работу No Language Left Behind: Scaling Human-Centered Machine Translation (2207.04672) на arXiv и после этого полез изучать документацию к репозиторию на GitHub.
Если коротко, то модель NLLB создана инженерами из F**k, представляет из себя мультиязыковую модель для выполнения задачи машинного перевода типа: sequence-to-sequence, то есть предложение в предложение.
Есть два основных варианта реализации модели:
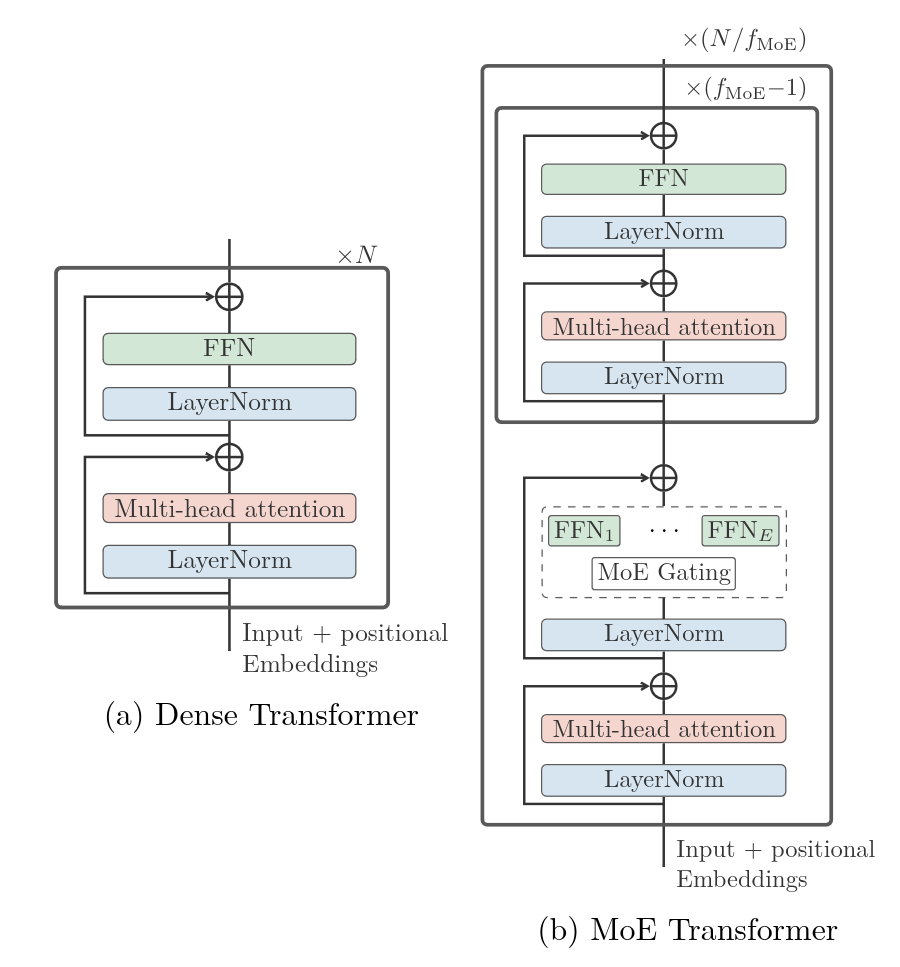
- Dense (можно перевести как: компактный) - похожа на обычную трансформерную GPT модель, навроде LLaMA или ruGPT, ей передаётся какой-то текст на входе и какой-то текст ожидается на выходе. Указание языка на который осуществлять перевод происходит при помощи токена следующего сразу за bos_token_id, в данном случае модель работать как эдакая всезнайка, она компактнее и быстрее чем MoE версия, но имеет чуть меньшую точность;
- Dense Distilled - Тоже что и предыдущая, только из неё убраны слои и веса которые не сильно влияют на качество перевода, при этом дистилированные модели весят намного меньше.
- MoE (Mixture of Expert, то бишь: смесь экспертов) - указанная версия несколько сложнее чем Dense вариант, одна из особенностей в том, что в ней при помощи шлюзов (MoE Gating) реализована маршрутизация нескольких внутренних моделей работающих с разными группами языков. Этот подход в разы увеличивает размер модели, однако, увеличивается и качество перевода, скорость само-собой у MoE модели тоже чуть ниже чем у Dense, но если важна точность то эти недостатки не критичны.
На HuggingFace можно найти следующие вариации модели:
А вот тут можно изучить все их метрики.
Пример использования
Принцип работы модели NLLB плюс-минус похож на обычные трансформерные GPT'шки и, как говаривал классик, суть такова:
- сначала мы инициализируем токенизатор, явно указав с какого языка происходит перевод (если не указать то будет выбран eng_Latn), скажем мы хотим перевести с русского (тогда пишем rus_Cyr), передаём на вход токенизатора некий текст, после чего получаем массив из токенов;
- далее на вход модели передаются указанные токены, но самое любопытное, что сразу после токена bos_token_id (анг. Begin of String, то есть: начало строки) под капотом передаётся токен идентификатора языка, на который необходимо выполнить перевод;
- модель шебуршит шестерёнками и возвращает токены перевода на нужный язык, после чего выполняется обратная токенизация, которая восстанавливает переведённый текст.
Ну то есть грубо говоря данный проект работает по принципу схожему с тем как реализованы генеративные instruct модели, способные выполнять некую полезную работу, но в случае перевода им даётся только одна задача: переведи с одного языка на другой.
А вот пример кода, который позволяет выполнить перевод с русского на английский:
Исходники тут.
Дальше мне захотелось сделать из этого кода класс и реализовать в нём пару методов, первый будет выполнять определение языка по переданному тексту (эту часть реализовал через langdetect), а второй метод будет выполнять перевод.
Исходный код указанного класса можно посмотреть тут.
В методе detect взывается функция get_language_long из локального пакета nllb_languages, давайте рассмотрим код этого пакета:
Дальше идёт несколько десятков строк с перечислением языков.
Исходный код пакета находится тут.
В массиве LANGUAGES перечислены не совсем все языки, полный список можно найти в тексте публикации No Language Left Behind: Scaling Human-Centered Machine Translation (2207.04672) в главе №3 на 12й странице.
Как видно из исходного кода пакет nllb_languages при импорте класса происходит подготовка переменных SHORT_TO_LONG и LONG_TO_SHORT для ускорения процесса поиска нужного языка. Далее имеется два метода для получения короткого названия языка по длинной версии и обратная функция.
А вот так можно данным классом пользоваться:
Завершение
И вот мы подошли к концу нашего путешествия по просторам возможностей проекта NLLB, надеюсь, что мои наблюдения и заметки окажутся полезными для вас, будь то для академических исследований или просто из любопытства к новым технологиям в области машинного перевода.
Не забывайте следить за обновлениями, ведь в мире технологий всегда происходит что-то новое и удивительное. И, конечно же, если вам понравилась эта публикация, не забудьте подписаться на мой Telegram-канал, где я делюсь своими мыслями, новостями и экспериментами. Ваша поддержка и интерес вдохновляют меня на новые исследования и публикации!
К тому же, если вы хотите поддержать мои усилия то можете сделать пожертвование на CloudTips. Ваша поддержка поможет мне продолжать свою работу и делиться новыми открытиями с вами.
Спасибо за ваше внимание и до новых встреч!