Здравствуйте, Дорогие друзья! В данной статье мы с Вами поговорим о Си-подобных языках программирования. Не будем "тянуть резину", начнем с типов данных.
Под типами данных понимается способ представления информации. То есть числа, буквы, строки. Самый, наверное, простой тип данных – это Boolean. Легче всего его представить в виде односложного ответа на поставленный вопрос. Переменная данного типа может принимать только два возможных значения: «истина» и «ложь». Где применяется тип Boolean, если его алфавит настолько ограничен? В основном при построении циклов и ветвлений. Например, если говорить о циклах:
Выполнять циклически (пока переменная Х является истиной)
{Тело цикла}
Или же для ветвлений:
Если переменная = истина, то выполнить действие 1,
Иначе – выполнить действие 2
Итак, тип Boolean имеет только два значения: true и false. В памяти переменная Boolean занимает 1 байт:
- true = B00000001,
- false = B00000000.
Буква В означает, что запись выполнена в двоичном виде. Можно также писать в десятичном без каких либо пометок: просто 1 или просто 0. Компилятор сам «поймет» что к чему.
Сразу оговорюсь, раз уж затронул тему двоичной записи. При записи числа в двоичном виде его можно начинать как с заглавной буквы В, так и с 0b.
Идем дальше: десятичное натуральное целое знаковое число. Ну или, если для Вас выговаривать это название раз за разом слишком долго, то просто integer или еще проще int. В памяти тип int занимает 2 байта. Думаете это много? Ни в коем разе: 2 байта – это 8*2 = 16 бит, то есть всего:
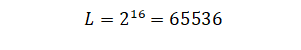
Не забываем, что данный тип еще и знаковый, то есть половина чисел будет отрицательной. Вот и получается, что диапазон значений int может быть представлен от -32768 до 32767. Почему положительное число по модулю (применяя к числу модуль мы перестаем учитывать знак минус этого числа, если он есть, то есть отрицательное число становится положительным; решил сделать пояснение, вдруг кто-то плохо знаком с модулями) меньше отрицательного? Потому что мы учли ноль. Он относится именно к положительной части диапазона. То есть от -32768 до 0 всего 32768 чисел, также и от 0 до 32767 всего 32768 чисел, отсюда получаем всего 65536 возможных чисел.
Однако, int может быть по умолчанию представлен и в виде 4 байт (в зависимости от того, какое «железо» мы используем). То есть это уже 32 бита:
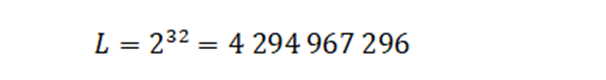
Не поверите, но это, в некотором роде, тоже мало. Потому как диапазон отрицательных чисел будет занимать интервал от -2 147 483 648 до 0, а положительных – от 0 до 2 147 483 647.
Но что делать, если у Вас спросят, «так какой конкретно диапазон возможных значений у типа int без отсылок к архитектуре процессора, для которого пишется программа»? Давайте разбираться. Согласитесь, нелепо бы выглядело, если бы один программист говорил другому что-то вроде «в данной программе применен тип данных int для такого-то микропроцессора, а в той программе для такого-то», подразумевая, что один тип данных двухбайтовый, а другой четырехбайтовый. Конечно же такого Вы никогда и нигде не услышите. Зато, можете услышать, про разрядность этих самых микропроцессоров (16-битные, 8-битные, 32-битные и т.д.). Проще, конечно же выполнить классификацию несколько по-другому. «Инты» принято различать как длинные и короткие. Под длинными понимаются четырехбайтовые числа, к названию типа данных int, в этом случае, делается приставка «long», то есть записывается не просто int, а long int. При употреблении коротких «интов» понимается, что применяются двухбайтовые числа, а к названию делается приставка «short». Таким образом, для short int диапазон возможных значений находится в интервале от -32 768 до 32 767, а для long int – от -2 147 483 648 до 2 147 483 647.
Однако, на этом наше знакомство с типом integer не заканчивается, так как наличие представить число можно не только в знаковом виде, но и в беззнаковом (проще говоря только положительные значения). Для того, чтобы указать компилятору, что мы используем беззнаковый тип, необходимо добавить к кодовому слову intприставку «unsigned». Как уже говорилось, у двухбайтовой версии типа int может быть 65 536 значений. А это значит, что переменная типа unsigned short int может принимать значения от 0 до 65 535. Для unsigned long int переменные могут принимать значения в диапазоне от 0 до 4 294 967 295. Запись unsigned short int можно заменить на эквивалентную «uint16_t», а запись unsigned long int– записью «uint32_t» (также можно заменить short int на просто short или на int16_t, а long intна long или на int32_t). Но и это еще не всё: существует тип integer, значение которого может занимать в памяти целых 8 байт! Он называется long long int (диапазон возможных значений от -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807). Данный тип также может быть беззнаковым, то есть unsigned long long int (от 0 до 18 446 744 073 709 551 615). Записать имена для данных типов можно как int64_t и uint64_t соответственно. Вот теперь, с «интом», пожалуй, закончили.
Переходим к следующему типу данных, без которого разработка программы будет проблематичной. А именно, к типу данных char. Char – символьный тип данных (про таблицу «АСКИ» слыхали? Вот это как раз из той серии). Если мы приравняем переменной типа char десятичное или двоичное число, то при компиляции программы, данному числу в соответствие будет поставлен символ из таблицы ASCII, порядковый номер которого соответствует указанному числу. В памяти тип char занимает 1 байт. При этом может быть как знаковым, так и беззнаковым. И в такой интерпретации данный тип становится уже не символьным, а числовым, то есть может быть использован для записи числа и оно не будет при компиляции конвертировано в символ. Знаковый тип char соответствует записи имени типа с приставкой «signed», то есть signed char(можно также использовать запись int8_t). Переменная данного типа может принимать значения от -128 до 128. Беззнаковый тип или unsigned char (имя может быть записано как uint8_t) может быть представлен в виде значения от 0 до 255.
Вы заметили, что если тип данных (любой) – знаковый, то количество отрицательных и положительных значений одинаково, а их общее количество равно количеству значений в том же самом типе данных, но беззнаковом? Почему так? Возьмем для примера типы данных int8_t и uint8_t. Запишем два числа int8_t, а именно: -128 и 127.
-128 = 0b11111111;
127 = 0b01111111;
Всё чем отличаются эти два числа – содержимое старшего бита. При отрицательном значении он содержит единицу, при положительном – ноль. То есть для записи числа по факту используется 7 бит. Если же мы будем использовать uint8_t, то старший бит не будет занят знаком, и мы сможем записать в него число, состоящее из 8 бит.
Но мы отвлеклись от типа данных char. При присвоении значения переменной данного типа, его необходимо поместить в апострофы, или в одинарные кавычки, чтобы оно воспринималось компилятором как записываемый символ, а не порядковый номер символа в таблице ASCII. Массив char – не что иное как слово или строка (то есть совокупность символов).
Рассмотрим теперь способы записи в память чисел с запятой. Для этого существует два типа данных: double и float. Способы представления записи числа в обоих типах данных похожи. Значение float состоит из мантиссы и экспоненты (порядка). В памяти переменная типа float занимает 4 байта (то есть 32 бита). Старший бит (31) будет отвечать за знак порядка. Следующие 8 бит (с 30 по 23) – порядок. Остальная часть – мантисса (биты 22 - 0).
Такой способ записи называется нормализованным (Обратите внимание: выше 22 разряда мы записали значащую 1. Она неявная (значение мантиссы находится между 1 и 2), то есть находится там постоянно, поэтому не запоминается, но при вычислениях учитывается). При этом, старший бит мантиссы – значащий, то есть он располагается слева от запятой. Диапазон значений переменной типа float включает в себя числа от 3.4Е-38 до 3.4Е+38. Само число будет иметь вид:
Я записал под степенью число 2, а не 10, как пишут во многих учебниках (причем не поясняя при этом сути формулы!), но всё не так просто. Точнее, всё наоборот очень просто: 10 - это двойка в двоичном виде. Предположим, что число у нас имеет вот такой вид:
Переведем значения из двоичной системы в десятичную:
Рассмотрим еще один пример, причем более информативный.
Предположим, что все разряды в числе заняты единицами:
Отлично! Мы нашли верхнюю границу возможных значений float. Цифр, конечно после запятой побольше будет, но я, как и другие, решил "немного" округлить ответ. А теперь, поясню в чем информативность данного примера. Посмотрите на экспоненту. Там у нас число 11111110. Почему не 11111111? Ха! А вот и еще одна особенность числа с плавающей запятой: в его экспоненте хранится не только степень, но и ее знак. Посмотрите внимательно на решение: перед тем как возводить двойку в степень, мы эту степень сначала находим, вычитая из экспоненты 127. 127 здесь - это эквивалент границы положительных и отрицательных степеней. То есть 127 условно - это степень 0. Ниже 127 - отрицательные степени, выше - положительные. Ничего сложного.
Получается, что алгоритм работы с float (имеется ввиду перевод из двоичной системы счисления в десятичную) такой:
1. Конвертировали мантиссу из двоичной СС в десятичную;
2. Конвертируем экспоненту из двоичной СС в десятичную;
3. Находим порядок (степень), путем вычитания числа 127 из экспоненты;
4. Возводим двойку в найденную степень;
5. Умножаем мантиссу на двойку в степени.
Тип данных double очень похож на float, но при этом переменная типа double занимает в памяти 8 байт. Мантисса занимает 52 бита, экспонента – 11 бит (то есть двойка может быть возведена в 1022 степень!).
Существует также long double, переменная которого занимает в памяти 10 байт, из которых 64 приходится на мантиссу и 15 на экспоненту.
Чем же тогда отличаются float, double и long double друг от друга? Они отличаются количеством значащих цифр. Для float оно составляет 7, для double 15, а для long double и вовсе 19!
Существуют также такие типы данных с плавающей запятой, которые называют денормализованными. То есть главный разряд мантиссы в них – не единица. Операции с такими числами выполняются также как и с нормализованными, но при этом учитывается, что слева от запятой находится не единица, а ноль (ничего сложного: просто умножаем дробь на двойку в степени и всё!). Применение денормализованных чисел позволяет увеличить диапазон возможных наименьших значений, однако точность их при этом уменьшается.
На этом, пожалуй, закончим статью. В ней мы рассмотрели основные типы данных. Если что-то показалось Вам непонятным – перечитайте эти моменты еще раз, так как я старался изложить всё как можно проще, но сам материал простым к пониманию вряд ли можно назвать, я имею ввиду ту часть статьи, в которой рассказывается о типах с плавающей запятой.
Надеюсь, написав эту статью, я смог Вам чем-нибудь помочь. Спасибо, что читаете. Удачи в учебе и труде!