Большие языковые модели, так называемые LLM, становятся все ближе к человеку в плане развития мышления и логики. В качестве ориентира служит популярный, но противоречивый тест Тьюринга. В тесте языковые модели должны успешно обмануть участников эксперимента, заставив их думать, что они люди.
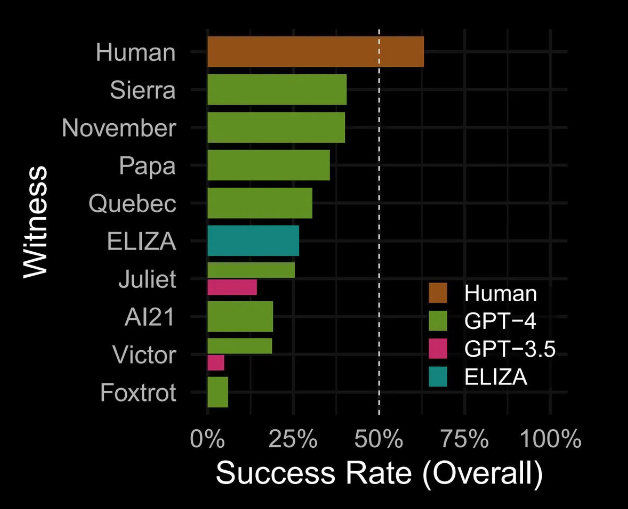
Исследователи противопоставили модель языка ИИ GPT-4 участникам-людям, GPT-3.5 и Элизе. Люди все равно победили, но новый языковой ИИ OpenAI все равно смог обмануть многих людей.
Однако очень удивил другой результат: чат-бот Элиза, разработанный в 1966 году, сумел убедить в том, что он человек больше людей, чем GPT 3.5.
Используя тест Тьюринга, исследователи хотели выяснить, насколько человечными выглядят чат-боты. Тест назван в честь его изобретателя Алана Тьюринга, у которого в 1950 году возникла идея, как определить, обладает ли компьютер такой же способностью мыслить, как человек. Первоначально Тьюринг назвал этот тест «игрой в имитацию».
В версии, которую использовали исследователи, испытуемым отводилось две роли: либо они должны были выяснить, с кем они общаются — с ИИ или человеком, либо — убедить собеседника в человечность.
Помимо участников-людей, было 25 участников LLM, которые различались не только моделью, но и разными подсказками. Всего 652 участника выполнили в общей сложности 1810 «имитационных игр».
Удивительно, но Элиза, языковая модель 1960-х годов, показала себя в исследовании относительно хорошо, достигнув более высокого результата, чем GPT-3.5, независимо от подсказки. По словам профессора информатики Принстона Арвинда Нараянана, результаты не имеют большого значения. По его мнению, исследованию не хватает контекста.
В конечном счете, GPT-4 не соответствует критериям теста Тьюринга из-за вероятности успеха менее 50%. Исследователи полагают, что при правильном проектировании GPT-4 или подобные модели в итоге сумеют пройти тест Тьюринга. Некоторые эксперты ожидают, что начиная с GPT-5 может появиться так называемый общий искусственный интеллект (AGI), который будет очень похож на человеческий мозг.