Этот пост посвящен созданию единой системы на базе DST Platform, для выполнения всех рабочих нагрузок по анализу данных, связанных с клиентами, поставщиками, аналитиками и руководством для высоко нагруженного маркетплейса.
Рассмотрим пример - Маркетплейс клиента пытается создать хранилище данных, которое сможет выполнять все рабочие нагрузки по анализу больших данных, связанные с клиентами, поставщиками, аналитиками и руководством. К основным задачам относятся:
- Запрос по импорту и экспорту номенклатуры: множество поставщиков маркетплейса хотят проверить множество деталей своих позиций. Они также должны поддерживать такие фильтры, как атрибуты, типы доставки, геолокацию и вложенность категорий.
- Многомерный анализ. Аналитики и в автоматическом режиме сама система DST Platform, составляют свои отчеты на основе различных измерений данных по мере необходимости, чтобы они могли извлекать информацию для облегчения инноваций в продуктах.
- Информационная панель DST Platform: предназначена для создания визуального обзора тенденций продаж и горизонтального и вертикального сравнения различных показателей.
Архитектура данных с большим количеством компонентов
Маркетплейс клиента начал с архитектуры Lambda, разделив свой конвейер данных на канал пакетной обработки и канал потоковой обработки. Для потоковой передачи данных в реальном времени они применяют Flink CDC; для пакетного импорта они используют Sqoop, Python и DataX для создания собственного инструмента интеграции данных под названием Hisen.
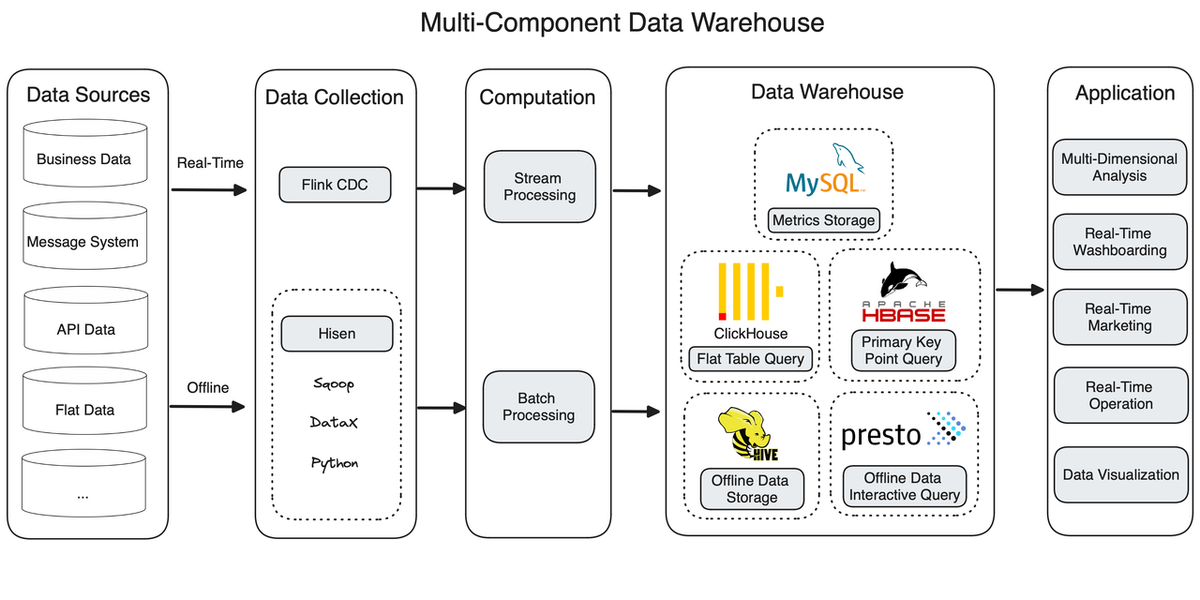
Затем данные реального времени и офлайн-данные встречаются на уровне хранилища данных, который состоит из пяти компонентов.
ClickHouse
Хранилище данных имеет плоскую табличную структуру, и ClickHouse превосходно справляется с чтением плоских таблиц. Но по мере развития бизнеса ситуация становится сложной по двум причинам:
Для поддержки межтабличных соединений и точечных запросов пользователю требуется звездообразная схема, но ее сложно реализовать в ClickHouse.
Изменения в договорах страхования необходимо обновлять в хранилище данных в режиме реального времени. В ClickHouse это делается путем воссоздания плоской таблицы с перезаписью старой, что происходит недостаточно быстро.
MySQL
После расчета метрики данных сохраняются в MySQL, но по мере роста размера данных MySQL начинает испытывать проблемы, связанные с такими проблемами, как длительное время выполнения и возникновение ошибок.
Apache Hive + Presto
Hive является основным исполнителем в канале пакетной обработки. Он может преобразовывать, агрегировать и запрашивать офлайн-данные. Presto — это дополнение к Hive для интерактивного анализа.
Apache HBase
HBase выполняет запросы по первичному ключу. Он считывает статус клиента из MySQL и Hive, включая кредиты клиента, период покрытия и страховую сумму. Однако, поскольку HBase не поддерживает вторичные индексы, его возможности чтения столбцов, не являющихся первичными ключами, ограничены. Кроме того, как база данных NoSQL, HBase не поддерживает операторы SQL.
Компоненты должны работать вместе, чтобы удовлетворить все потребности, в результате чего хранилище данных становится слишком большим, чтобы о нем можно было заботиться. Начать работу непросто, поскольку инженеры должны пройти обучение работе со всеми этими компонентами. Кроме того, сложность архитектуры увеличивает риски задержек.
Итак, маркетплейс клиента совместно с разработчиками компании DST Global попытались найти инструмент, который отвечает их требованиям. Первое, что им нужно, — это возможности работы в реальном времени, включая запись в реальном времени, обновление в реальном времени и ответ в реальном времени на запросы данных. Во-вторых, им нужна большая гибкость в анализе данных для поддержки запросов самообслуживания, ориентированных на клиентов, таких как многомерный анализ, запросы на объединение больших таблиц, индексы первичных ключей, свертывание и детализация. Затем, для пакетной обработки, им также нужна высокая пропускная способность при записи данных.
В конце концов клиент остановил свой выбор на Apache Doris.
Замена четырех компонентов на Apache Doris
Apache Doris способен выполнять анализ данных как в режиме реального времени, так и в автономном режиме, а также поддерживает как высокопроизводительный интерактивный анализ, так и точечные запросы с высоким уровнем параллелизма. Вот почему он может заменить ClickHouse, MySQL, Presto и Apache HBase и работать как единый шлюз запросов для всей системы данных.
Улучшенный конвейер данных представляет собой гораздо более чистую архитектуру Lambda.
Apache Doris предоставляет широкий спектр методов приема данных. Запись данных выполняется быстро. Кроме того, он также реализует слияние при записи для повышения производительности при одновременных точечных запросах.
Сниженная стоимость
Новая архитектура снизила затраты пользователя на человеческие усилия. Во-первых, гораздо более простая архитектура данных значительно упрощает обслуживание; с другой стороны, разработчикам больше не нужно объединять данные реального времени и офлайн-данные в API обслуживания данных.
Маркетплейс теперь также может сэкономить деньги с помощью Doris, поскольку он поддерживает многоуровневое хранилище. Это позволяет пользователю помещать огромное количество редко используемых исторических данных в объектное хранилище, что намного дешевле хранить данные.
Более высокая эффективность
Apache Doris может достигать количества запросов в секунду, равного 10 000, и отвечать на миллиарды точечных запросов в течение миллисекунд, поэтому ему легко обрабатывать запросы, обращенные к клиентам. Многоуровневое хранилище, которое отделяет «горячие» данные от «холодных», также повышает эффективность их запросов.
Доступность услуги
Являясь унифицированным хранилищем данных для хранения, вычислений и сервисов обработки данных, Apache Doris обеспечивает простое аварийное восстановление. Благодаря меньшему количеству компонентов им не придется беспокоиться о потере или дублировании данных.
Важной гарантией доступности сервиса для пользователя является возможность межкластерной репликации (CCR) Apache Doris. Он может синхронизировать данные от кластера к кластеру в течение нескольких минут или даже секунд и реализует два механизма для обеспечения надежности данных:
- Binlog : этот механизм может автоматически регистрировать изменения данных и генерировать LogID для каждой операции изменения данных. Дополнительные идентификаторы LogID гарантируют, что изменения данных будут отслеживаемыми и упорядоченными.
- Сохранение данных : в случае сбоя системы или возникновения чрезвычайной ситуации данные будут помещены на диски.
Более глубокий взгляд на Apache Doris
Apache Doris может заменить ClickHouse, MySQL, Presto и HBase, поскольку он обладает обширным набором возможностей на протяжении всего конвейера обработки данных. При приеме данных он обеспечивает запись в реальном времени с малой задержкой благодаря поддержке Flink CDC и Merge-on-Write. Он гарантирует однократную запись с помощью механизма меток и транзакционной загрузки. В запросах данных он поддерживает как звездообразную схему, так и агрегацию плоских таблиц, что позволяет обеспечить высокую производительность как при объединении нескольких таблиц, так и при больших запросах к одной таблице. Он также предоставляет различные способы ускорения различных запросов, такие как инвертированный индекс для полнотекстового поиска и запросов по диапазону, сокращенный план и подготовленные операторы для точечных запросов.
#dst #dstglobal #дст #дстглобал #clickhouse #дстплатформ #dstplatform #mysql #apache #хранилищеданных #doris #presto #lambda #базаданных #маркетплейс