Всем привет!
Сегодня решал задачу из сборника «30 days of Pandas». Там в списке осталось меньше трети, поэтому собираюсь закончить с ним в ближайшее время.
Конечно эти задачи не самые интересные, но говорят, что Pandas очень полезная библиотека.
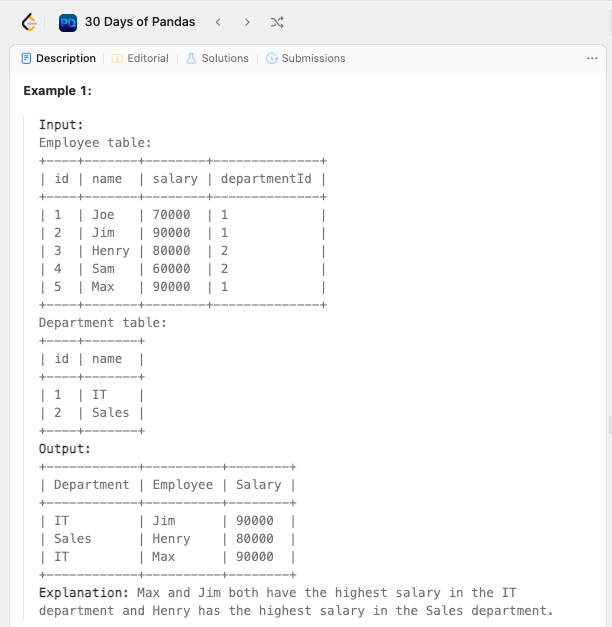
Задача опять про зарплату. Нужно было найти кто и в каком департаменте получает больше всего. Сложность в задаче составляли:
- необходимость совместить две таблицы с необходимыми данными (это я уже умею);
- найти максимальные зарплаты (с этим тоже без проблем справился);
- не выкидывать из таблицы одинаковые значения, если они равны максимальным (вот с этим было сложно).

Как я и сказал, найти максимальные зарплаты просто. Нужно применить метод .groupby() к необходимой колонке (номер департамента) и функцию .max(). Это позволит получить таблицу, в которой останется только по одной строке для каждого департамента. Проблема в том, что в задаче в одном из департаментов у двух сотрудников такая зарплата.
Поэтому приходится делать дополнительны действия. Мне тут пришлось попотеть и даже подсмотреть подход в ролике одного индуса (заодно попрактиковался в аудировании этого акцента)
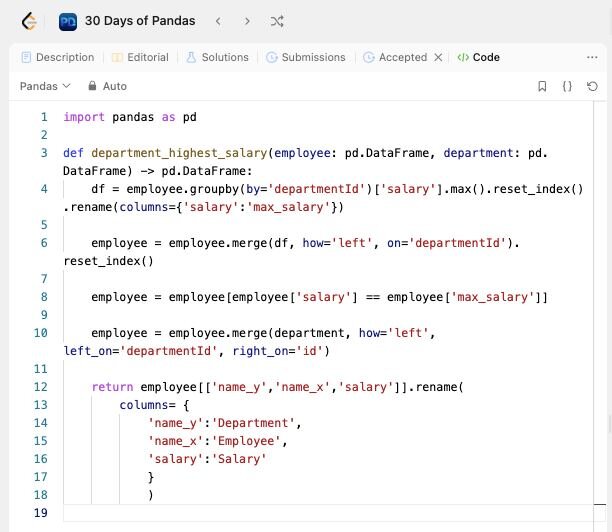
Подход такой: добавляем в общую таблицу колонку с максимальной зарплатой для каждого департамента (метод .merge()). С помощью этой информации фильтруем полученную таблицу.
Затем опять же с помощью .merge() добавляем в таблицу данные о названии департаментов и выдаем результат (в нужном формате)
Тоже самое можно сделать с помощью метода apply() и lambda функции. Логика там такая же, просто нужно разбираться в синтаксисе lambda.
Это я уже скопировал у индуса.
Оба решения получаются примерно одинаково эффективными.
На сегодня все…
До скорого



















