В материалах, опубликованных ранее:
можно познакомиться с теоретической информацией и практическими работами, связанными с программированием на языке программирования Function Block Diagram в среде программирования PC WorX.
В текущем материале приведём варианты лабораторных работ для работы с текстовой строкой:
Определение. Последовательность символов алфавита, заключенная в кавычки, представляет собой символьную (текстовую) строку.
Замечание: Кавычки в текстовую строку не входят. Например, 'Это строка символов'. Первая кавычка указывает на начало строки, последняя – на ее окончание.
Функции для операций с символьными строками на языке Function Block Diagram представлены элементами CONCAT, DELETE, EQ_STRING NE_STRING GE_STRING, GT_STRING, LE_STRING, LT_STRING, FIND, INSERT, MID, REPLACE, LEFT, RIGHT и LEN, вид которых изображен на рисунке ниже:
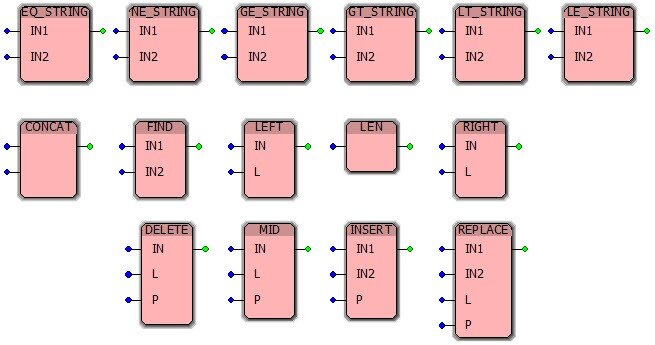
Функция CONCAT объединяет на выходе OUT (тип данных STRING) две символьные строки путем добавления символьной строки на входе IN2 (тип данных STRING) в конец символьной строки на входе IN1 (тип данных STRING).
Функция DELETE. Эта функция удаляет из символьной строки IN (тип данных STRING) фрагмент с числом символов L (тип данных ANY_INT) начиная с позиции P (тип данных ANY_INT). Тип данных на выходе OUT – STRING. В случае неверного ввода данных результирующая переменная возвращает пустую строку, и программируемый логический контроллер выдает ошибку.
Функция EQ_STRING сравнивает символьную строку с входа IN1 (тип данных STRING) с символьной строкой с входа IN2 (тип данных STRING) и устанавливает на выходе OUT (тип данных BOOL) значение TRUE, если строки IN1 и IN2 равны, и значение FALSE, если не равны.
Функция NE_STRING сравнивает символьную строку с входа IN1 (тип данных STRING) с символьной строкой с входа IN2 (тип данных STRING) и устанавливает на выходе OUT (тип данных BOOL) значение TRUE, если строки IN1 и IN2 не равны, и значение FALSE, если они равны.
Функция GE_STRING сравнивает символьную строку с входа IN1 (тип данных STRING) с символьной строкой с входа IN2 (тип данных STRING) и устанавливает на выходе OUT (тип данных BOOL) значение TRUE, если строка IN1 больше или равна строке IN2, в противном случае устанавливается значение FALSE.
Функция GT_STRING сравнивает символьную строку с входа IN1 (тип данных STRING) с символьной строкой с входа IN2 (тип данных STRING) и устанавливает на выходе OUT (тип данных BOOL) значение TRUE, если строка IN1 больше строки IN2, в противном случае устанавливается значение FALSE.
Функция LE_STRING сравнивает символьную строку с входа IN1 (тип данных STRING) с символьной строкой с входа IN2 (тип данных STRING) и устанавливает на выходе OUT (тип данных BOOL) значение TRUE, если строка IN1 меньше или равна строке IN2, в противном случае устанавливается значение FALSE.
Функция LT_STRING сравнивает символьную строку с входа IN1 (тип данных STRING) с символьной строкой с входа IN2 (тип данных STRING) и устанавливает на выходе OUT (тип данных BOOL) значение TRUE, если строка IN1 меньше строки IN2, в противном случае устанавливается значение FALSE.
Для функций GE_STRING, GT_STRING, LE_STRINGи LT_STRING необходимо помнить, что сравнение осуществляется слева направо. Символ 'Z' больше, чем символ 'A', поэтому строка 'Z' больше, чем строка 'AZ' и 'AZ' больше строки 'ABC'. При сравнении двух строк разной длины, более короткая строка должна быть продлена справа до величины более длинной строки символами с нулевым значением. Выход OUT можно инвертировать.
Функция FIND определяет положение строки на входе IN2 (тип данных STRING) в строке на входе IN1. Позиция символа первого вхождения строки на входе IN2 в строку IN1 передается на выход OUT (тип данных INT). Если совпадений не найдено, то выход OUT = 0.
Функция INSERT. Эта функция символьной строки вставляет строку с входа IN2 (тип данных STRING) в строку на входе IN1 (тип данных STRING) после символа на позиции P (тип данных INT).
Функция MID извлекает фрагмент символьной строки, поданной на вход IN (тип данных STRING), начиная с позиции P (тип данных ANY_INT). Число извлекаемых символов определяется переменной L (тип данных ANY_INT).
Функция REPLACE заменяет фрагмент символьной строки с входа IN1 на строку с входа IN2, начиная с позиции P (тип данных ANY_INT). Число символов, которые будут заменены, определяется переменной L (тип данных ANY_INT).
Необходимо понимать, что для функций INSERT, MID и REPLACE значение переменной на входе Р не может быть равно 0. Первая позиция в строке представляет собой всегда 1. Также невозможно использовать одну и ту же строку в качестве входной и выходной строки. В этом случае следует использовать промежуточную переменную на выходе, которой затем назначается значение входной переменной. Если требуется вставить строку одну перед другой, следует использовать не функцию INSERT, а функцию CONCAT.
Функция LEFT извлекает L левых символов строки с входа IN. Тип данных для входа IN и выхода OUT – STRING, для входа L - ANY_INT.
Функция RIGHT извлекает справа L символов строки с входа IN. Тип данных для входа IN и выхода OUT – STRING, для входа L - ANY_INT.
Функция LEN определяет длину символьной строки. Тип данных для входа IN – STRING, для выхода OUT - INT.
Лабораторная работа 1 «Проверка текстовых (символьных) строк на логическое условие».
Проверьте символьную строку на условие, заданное в таблице 1 (см. ниже). Результат проверки представьте в виде логически обоснованной символьной строки.

Пример выполнения лабораторной работы 1.
Рассмотрим пример решения для варианта № 30. По условию задачи текстовая строка проверяется на наличие латинских символов 'A', 'B' и 'C'.
Для проверки каждого условия воспользуемся функцией FIND, для которой по первому входу будем вводить исследуемую текстовую строку, а по второму – условия совпадения. При совпадении символов на выходе функции FIND появляется число символов в формате ANY_INT. Для организации перехода по условию воспользуемся блоком SEL, как показано на рисунке ниже. Для согласования типов данных применим функцию преобразования типов INT_TO_BOOL, выдающую значение TRUE при любом INT, не равном нулю.
Лабораторная работа 2 «Сложные условия для символьных строк».
Для текстовой строки, состоящей из полного имени, отчества и фамилии, необходимо получить текстовую строку, которая должна быть в виде Фамилия И.О. (например, символьная строка 'Виктор Николаевич Семенов' должна преобразоваться в символьную строку 'Семенов В.Н.').
Пример выполнения лабораторной работы 2.
Рассмотрим пример выполнения лабораторной работы 2. Согласно заданию, последовательность написания имени, отчества и фамилии жёстко задана, и по умолчанию они разделены пустой строкой (пробелом). Поэтому логика преобразований строится следующим образом:
1. Для преобразования «Имя Отчество Фамилия» в «И.Отчество Фамилия» находим первую пустую строку, что дает возможность подсчитать число букв в имени (Функция FIND в линии с маркером 1). Удалим лишние буквы, заменив их одной точкой (Функция REPLACE в линии с маркером 1, см. рис. ниже).
2. Аналогичным образом преобразуем полученный результат в «И.О.Фамилия» (элементы в линии, отмеченной маркером 2).
3. Далее по заданию требуется поменять местами строки «И.О.» и «Фамилия» и отделить их пробелом. Для этого предварительно определяем число символов в фамилии (число символов в строке «И.О.» известно), затем функциями LEFT и RIGHT разделяем символьную строку на две.
4. Функцией CONCAT сливаем строки в обратном порядке и дополняем пробелом при помощи функции INSERT (линия маркера 3).
Реализация программы на языке программирования Function Block Diagram в среде программирования PC WorX показана на рисунке ниже.
В качестве дополнительного Упражнения предлагается написать программу в среде программирования PC WorX, которая для текстовой строки (если не указано условие на символьную строку, то она считается произвольной, состоящей из латинских букв с допущением пробелов) воспроизводит текстовую строку, удовлетворяющую одному из условий, представленных ниже. Результат в режиме отладки в виде скрина приведите в виде комментария. Также укажите, какое именно условие выбрано для реализации программы.
Перечень вариантов условий для Упражнения:
1) в конце текстовой строки стоит символ a;
2) в начале текстовой строки стоит символ a;
3) в текстовой строке замените все символосочетания «qu» на «ququrequ»;
4) в текстовой строке каждое слово имеет нечётное число символов;
5) в текстовой строке каждое слово имеет чётное число символов;
6) в текстовой строке слова располагаются по возрастанию числа символов в словах;
7) все символы a и b заменяются на c и dсоответственно;
8) запрещено символосочетание let;
9) запрещено символосочетание at;
10) из текстовой строки удалите все символы, которые являются; одной из четырёх первых букв латинского алфавита;
11) из текстовой строки удалите первый символ каждого слова;
12) из текстовой строки удалите среднюю букву, если длина слова нечетная;
13) из текстовой строки удалите все пробелы;
14) каждый гласный символ удваивается;
15) каждый согласный символ от b до m удваивается;
16) каждый согласный символ от n до z удваивается;
17) между символами a стоит блок из четырёх символов;
18) на 2 месте в текстовой строке стоит символ a;
19) не больше одной пары одинаковых символов стоят рядом;
20) не встречается символосочетание ab;
21) одинаковые символы не идут друг за другом;
22) производится подсчёт гласных символов;
23) производится подсчёт случаев, когда символ слева меньше символа, стоящего справа;
24) производится подсчёт случаев, когда символ справа меньше символа, стоящего слева;
25) производится подсчёт согласных символов от b до m;
26) производится подсчёт согласных символов от n до z;
27) символ dидёт непосредственно перед a;
28) символы a и b не стоят рядом и разделяются символами out;
29) символы oo не стоят рядом;
30) слова символьной строки, начинающиеся с гласного символа, размещаются в лексикографическом порядке.