Это статья об основах программирования на Go. На канале я рассказываю об опыте перехода в IT с нуля, структурирую информацию и делюсь мнением.
Хой, джедаи и амазонки!
Когда мы регистрируемся на сайтах, нам предлагают ввести пароль и сообщают о надёжности вводимого пароля. В публикации поделюсь идеей реализации подобного простенького алгоритма с применением стандартного пакета Go regexp.
1. Задача
Сама задача взята с курса stepik "Программирование на Golang", подраздел "Строки".
Условия:
Ваша задача сделать проверку подходит ли пароль вводимый пользователем под заданные требования. Длина пароля должна быть не менее 5 символов, он должен содержать только арабские цифры и/или буквы латинского алфавита.
На вход подаётся строка-пароль.
Если пароль соответствует требованиям - вывести "Ok", иначе вывести "Wrong password"
Мой вариант решения выглядит так:
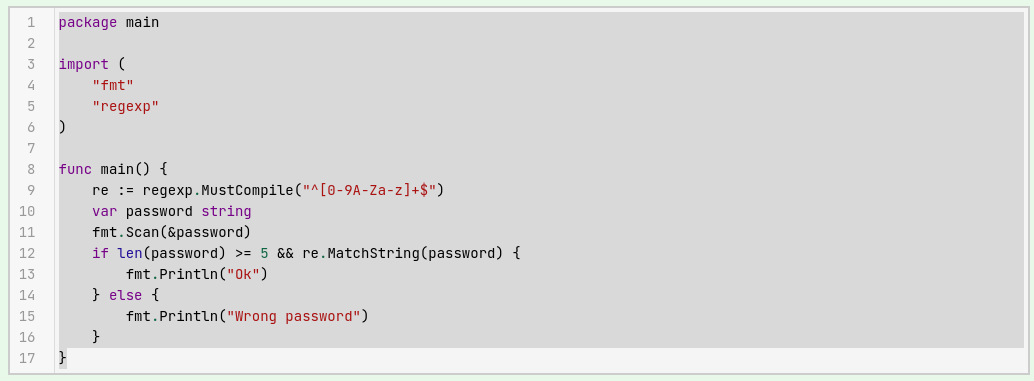
Разберём что здесь что. Привычных вещей вроде операторов if или считывания с консоли - касаться не будем. Поделюсь только тем, что считаю интересным.
2. Функция len
Начнём с простого. Функция len в строке кода 12 вернёт нам длину строки (password) в байтах. Т.е. не количество символов (рун), а именно количество байт, которые хранят в себе содержимое строки password. Напоминаю, под собой строка содержит срез байтов. Подробнее об этом можно почитать здесь <<<
Если кратко, то символ - это какой либо символ, в т.ч. смайлик или иероглиф из таблицы символов Unicode, или, например, символ точки или буква N из таблицы символов ASCII - которая также входит в состав таблицы Unicode.
Руна - это целое число, которое соответствует коду символа в таблице Unicode. Руна может занимать от 1 до 4 байт.
Соответственно, пароль состоящий из пяти символов Unicode может требовать для хранения от 5 до 20 байт.
Конкретно для заданных условий, функции len будет достаточно, т.к. мы проверяем по сути наличие в получаемом на входе пароле наличие только символов, входящих в ASCII-таблицу. А они в свою очередь требуют 1 байт для хранения каждый. Поэтому мы просто проверяем длину пароля более 5 байт.
Другое дело, если были бы условия, что в пароле могут быть символы из кириллицы. А то и прочие символы таблицы Unicode. В этом случае проверка на количество символов была бы сложнее. Как это сделать?
2.1. Вариант первый
Вместо len(password) нужно было бы записать:
utf8.RuneCountInString(password)
А в импортируемые пакеты к fmt добавить:
"unicode/utf8"
Функция utf8.RuneCountInString() является частью пакета utf8 в стандартной библиотеке Go и используется для определения количества рун в заданной строке. Эта функция обрабатывает строку, учитывая кодировку Unicode, чтобы правильно подсчитывать количество рун.
2.2. Вариант второй
Вместо len(password) нужно записать:
len([]rune(str))
И всё - никаких внешних пакетов импортировать не нужно.
Преобразование строки в руны может быть выполнено с использованием функции []rune().
Если мы захотим вывести на печать строку, например "АБВ", преобразованную в руну, то получим [1040 1041 1042].
Собственно, этот вариант лаконичнее подгружения пакета unicode/utf8, поэтому предпочтительнее.
3. Пакет regexp
Пакет regexp (сокращение от англ. Regular Expression - регулярное выражение) - это пакет в стандартной библиотеке Go, который предоставляет функционал для работы с регулярными выражениями.
Рассмотрим строку 9 кода на иллюстрации (см. раздел 1):
re := regexp.MustCompile("^[0-9A-Za-z]+$")
Здесь применяется пакет regexp. Официальная документация на пакет здесь <<<
3.1. О пакете
Регулярное выражение - это строка (набор символов), которая содержит шаблон для поиска или замены текста. Оно используется для поиска подстрок в тексте, проверки соответствия формату данных и других задач.
Когда конкретная строка входит в набор, описываемый регулярным выражением, принято говорить, что регулярное выражение соответствует строке.
Пакет regexp в Go позволит создавать, компилировать и использовать регулярные выражения для обработки текста.
Некоторые основные функции и методы пакета regexp включают:
- Функция regexp.Compile() или метод Compile() - для компиляции регулярного выражения и умеет возвращать ошибку.
- Методы MatchString(), Match(), FindString(), FindStringIndex() и другие - для проверки соответствия регулярному выражению и поиска соответствующих совпадений в строке.
- Методы FindAllString(), FindAllStringSubmatch(), FindAll() и другие - для поиска всех совпадений регулярного выражения в строке.
- Функция regexp.MustCompile() - для компиляции регулярного выражения без необходимости явной обработки ошибок. Отличается от regexp.Compile() тем, что при ошибке компиляции регулярного выражения вызывает панику.
- Методы ReplaceAllString(), ReplaceAllStringFunc(), ReplaceAll() и другие - для замены совпадений регулярного выражения в строке на другие значения.
- Методы Split(), SplitN() и другие - для разделения строки на подстроки на основе регулярного выражения.
Функцию regexp.MustCompile() удобно использовать, когда мы уверены в правильности написания регулярного выражения, и не хотим обрабатывать ошибки компиляции. Однако, если мы не уверены в правильности написания регулярного выражения, лучше использовать regexp.Compile() и обработать возможную ошибку.
3.2. Порядок работы с пакетом
1. В моём примере кода я использовал пакет regexp для создания регулярного выражения с помощью regexp.MustCompile(). Напомню эту строчку:
re := regexp.MustCompile("^[0-9A-Za-z]+$")
Данное регулярное выражение будет соответствовать строкам, которые состоят только из арабских цифр и букв латинского алфавита верхнего и нижнего регистров.
Символ "^" обозначает начало строки, символ "$" - конец строки, а "+" - одно или более вхождений предшествующего символа или группы символов.
2. Функция re.MatchString(password) возвращает true, если в исходной строке (password) присутствуют символы, скомпилированные в строке re. Иначе - false.
Что здесь можно добавить. Когда используют regexp, то обычно используют один паттерн (шаблон - если хотите - здесь он [0-9A-Za-z]) много раз - а это почти всегда так, то полезно его скомпилировать и потом пользоваться им. В моём коде так и сделано.
Дело в том, что компиляция шаблона занимает довольно много время. Можете задать вопрос - а как плохо? Вот так делать не нужно:
Здесь компиляция регулярного выражения происходит постоянно при подаче на проверку нового пароля. Это не есть хорошо.
Циклы по 100 раз я добавил для эксперимента - посмотреть что и как.
В среднем, в "плохом" коде длительность компиляции регулярное выражение (строка 63 кода) составляет 487.302µs (микросекунд) за сто циклов. А проверка в строках кода 47-53 - 513.95µs.
В первом же примере эти значения в диапазоне 100-300 микросекунд на сто циклов. Но вот какая штука - если скомпилировать строку, то при проверке, скажем, сотни или ста тысяч паролей - не придётся компилировать регулярное выражение снова и снова, если использовать код из первого примера.
4. Выводы
Познакомились с ещё одним пакетом в Go - regexp (легко запомнить - regular expression). Пополняем нашу инженерную насмотренность :)
Предлагаю самостоятельно улучшить предложенный алгоритм:
- Обеспечить, чтобы программа выдавала "Ок" - в случае, если есть комбинация и цифр и букв (сейчас можно ввести только цифры, и будет "Ок").
- Сделать проверку на пароль "Простой", "Средний" и "Сложный". Например, по количеству символов: 5 - простой, 6-10 - средний, более 11 - сложный.
- Добавить функционал ввода символов из Unicode (в плане подсчёта количества символов и наличия символа не только из ASCII).
Бро, ты уже здесь? 👉 Подпишись на канал для новичков «Войти в IT» в Telegram, будем изучать IT вместе 👨💻👩💻👨💻