Прежде чем перейти к основному содержанию этой части книги (о персистентности), мы сначала введем концепцию устройства ввода-вывода (I/O) и покажем, как операционная система может взаимодействовать с таким объектом. Конечно, ввод-вывод весьма важен для компьютерных систем; представьте себе программу без каких-либо входных данных (каждый раз она выдает один и тот же результат); теперь представьте программу без выходных данных (с какой целью она запускалась?). Очевидно, что для того, чтобы компьютерные системы были интересны, требуются как входные, так и выходные данные. И, таким образом, наша общая проблема:
КАК ИНТЕГРИРОВАТЬ ВВОД-ВЫВОД В СИСТЕМЫ
Как следует интегрировать ввод-вывод в системы? Каковы общие механизмы? Как мы можем сделать их эффективными?
36.1 Архитектура Системы
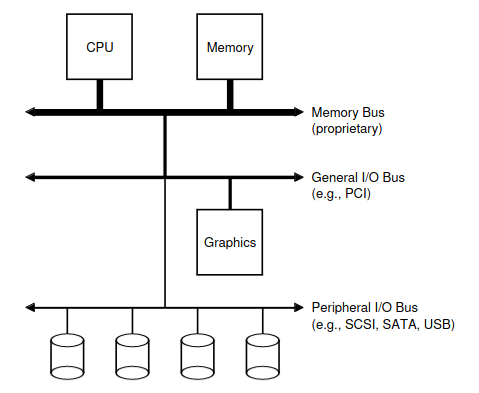
Чтобы начать наше обсуждение, давайте взглянем на “классическую” схему типичной системы (рис. 36.1). На рисунке показан один центральный процессор, подключенный к основной памяти системы через какую-либо memory bus или interconnect. Некоторые устройства подключены к системе через общую шину ввода-вывода (IO bus), которой во многих современных системах является PCI (или одна из ее многочисленных производных); графические и некоторые другие высокопроизводительные устройства ввода-вывода можно найти здесь. Наконец, еще ниже может находиться другая шина (или несколько таких шин), которую мы называем периферийной шиной (peripheral bus), такие как SCSI, SATA или USB. Они подключают к системе медленные устройства, включая диски, мыши и клавиатуры.
Один из вопросов, который вы могли бы задать, таков: зачем нам нужна подобная иерархическая структура? Ответ прост: физика и цена. Чем быстрее шина, тем она должна быть короче; таким образом, в высокопроизводительной шине памяти не так много места для подключения устройств и тому подобного. Кроме того, разработка шины для обеспечения высокой производительности обходится довольно дорого. Таким образом, разработчики систем приняли этот иерархический подход, при котором компоненты, требующие высокой производительности (такие как видеокарта), находятся ближе к центральному процессору. Компоненты с более низкой производительностью находятся дальше. Преимущества размещения дисков и других медленных устройств на периферийной шине многообразны; в частности, вы можете разместить на ней большое количество устройств.
Конечно, современные системы все чаще используют специализированные наборы микросхем и более быстрые point-2-point соединения для повышения производительности. На рисунке 36.2 показана приблизительная схема набора микросхем Intel Z270 [H17]. В верхней части процессор наиболее тесно подключен к системе оперативной памяти, но также имеет высокопроизводительное подключение к видеокарте (и, следовательно, к дисплею) для обеспечения работы игр (о, ужас!) и других приложений с интенсивной графикой.
Центральный процессор подключается к чипу ввода-вывода через фирменный интерфейс Intel DMI (Direct Media Interface), а остальные устройства подключаются к этому чипу через ряд различных соединений между собой. Справа один или несколько жестких дисков подключаются к системе через интерфейс eSATA; ATA (приставка AT, обозначающая подключение к IBM PC AT), SATA (для Serial ATA), а теперь и eSATA (для внешнего (external) SATA) представляют собой эволюцию интерфейсов хранения данных произошедшую за последние десятилетия. С каждым шагом вперед производительность повышается, чтобы идти в ногу с современными устройствами хранения данных.
Под микросхемой ввода-вывода находится ряд соединений USB (Universal Serial Bus), которые на данном рисунке позволяют подключать клавиатуру и мышь к компьютеру. Во многих современных системах USB используется для таких устройств с низкой производительностью, как эти.
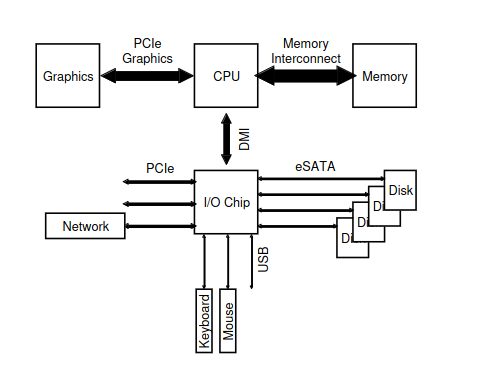
Наконец, слева другие устройства с более высокой производительностью могут быть подключены к системе через PCIe (Peripheral Component Interconnect Express). На этой схеме к системе здесь подключен сетевой интерфейс; сюда часто подключаются устройства хранения данных с более высокой производительностью (такие как устройства постоянной памяти NVMe).
36.2 A Canonical Device
Давайте теперь рассмотрим каноническое устройство (canonical device) (не реальное) и воспользуемся этим устройством, чтобы углубить наше понимание некоторых механизмов, необходимых для повышения эффективности взаимодействия с устройствами. Из рисунка 36.3 мы можем видеть, что устройство состоит из двух важных компонентов. Первый - это аппаратный интерфейс, который он представляет для остальной части системы. Точно так же, как часть программного обеспечения, аппаратное обеспечение также должно иметь какой-то интерфейс, позволяющий системному программному обеспечению управлять его работой. Таким образом, все устройства имеют некоторый определенный интерфейс и протокол для типичного взаимодействия.
Вторая часть любого устройства - это его внутренняя структура (internal structure). Эта часть устройства зависит от конкретной реализации и отвечает за реализацию абстракции, которую устройство представляет системе. Очень простые устройства будут иметь один или несколько аппаратных чипов для реализации своей функциональности; более сложные устройства, для выполнения своей работы, будут включать в себя простой процессор, некоторую память общего назначения и другие чипы, специфичные для устройства. Например, современные RAID-контроллеры могут состоять из сотен тысяч строк встроенного ПО (firmware) (т.е. программного обеспечения внутри аппаратного устройства) для реализации его функциональности.
36.3 The Canonical Protocol
На рисунке выше (упрощенный) интерфейс устройства состоит из трех регистров: регистра состояния (status), который можно считывать, чтобы увидеть текущее состояние устройства; регистра команд (command), чтобы сообщить устройству о выполнении определенной задачи; и регистра данных (data) для передачи данных устройству или получения данных с устройства. Считывая и записывая эти регистры, операционная система может управлять поведением устройства.
Давайте теперь опишем типичное взаимодействие, которое операционная система может осуществлять с устройством, чтобы заставить устройство что-то делать от его имени. Протокол заключается в следующем:
Протокол состоит из четырех этапов. На первом этапе ОС ожидает, пока устройство не будет готово к приему команды, путем многократного считывания регистра состояния; мы называем это опросом (polling) устройства (по сути, просто спрашиваем его, что происходит). На втором этапе, ОС отправляет некоторые данные в регистр данных; можно представить, что если бы это был, например, диск, то для передачи дискового блока (скажем, 4 КБ) на устройство потребовалось бы выполнить несколько операций записи. Когда основной процессор участвует в перемещении данных (как в этом примере протокола), мы называем это запрограммированным вводом-выводом (programmed I/O - PIO). На третьем этапе, операционная система записывает команду в регистр команд; это неявно сообщает устройству, что данные присутствуют и что оно должно начать выполнять команду. Наконец, ОС ожидает завершения работы устройства, снова запуская его в цикле, ожидая, завершено ли оно (затем может появиться код ошибки, указывающий на успех или неудачу).
Этот базовый протокол имеет тот положительный аспект, что он прост и работает. Однако это сопряжено с некоторой неэффективностью и неудобствами. Первая проблема, которую вы можете заметить в протоколе, заключается в том, что опрос кажется неэффективным; в частности, он тратит много процессорного времени, просто ожидая, пока (потенциально медленное) устройство завершит свою работу, вместо того, чтобы переключиться на другой готовый процесс и, таким образом, лучше использовать процессор.
СУТЬ: КАК ИЗБЕЖАТЬ ЗАТРАТ НА POLLING
Как ОС может проверять состояние устройства без частого опроса и, таким образом, снизить нагрузку на процессор, необходимую для управления устройством?
36.4 Снижение нагрузки на процессор с помощью прерываний
Изобретение, к которому многие инженеры пришли много лет назад, чтобы улучшить это взаимодействие, - это то, что мы уже видели: прерывание (interrupt). Вместо повторного опроса устройства ОС может инициировать запрос, перевести вызывающий процесс в спящий режим и переключить контекст на другую задачу. Когда устройство, наконец, завершит операцию, оно вызовет аппаратное прерывание, в результате чего центральный процессор переключится в операционную систему с заданной процедурой обслуживания прерываний (ISR - interrupt service routine) или, проще говоря, обработчиком прерываний (interrupt handler). Обработчик - это всего лишь фрагмент кода операционной системы, который завершит запрос (например, путем считывания данных и, возможно, кода ошибки с устройства) и запустит процесс, ожидающий ввода-вывода, который затем может выполняться по желанию. Таким образом, прерывания позволяют операциям вычисления и ввода-вывода перекрывать (overlap) друг друга, что является ключевым фактором для увеличения утилизации ресурсов. Эта временная шкала показывает проблему:
На диаграмме Процесс 1 выполняется на центральном процессоре в течение некоторого времени (обозначается повторяющейся цифрой 1 в строке центрального процессора), а затем выдает запрос ввода-вывода на диск для считывания некоторых данных. Без прерываний система работает, повторно опрашивая состояние устройства до тех пор, пока ввод-вывод не будет завершен (обозначается буквой p). Диск обслуживает запрос, и, наконец, Процесс 1 может быть запущен снова. Если вместо этого мы используем прерывания и допускаем перекрытие, операционная система может делать что-то еще в ожидании диска:
В этом примере операционная система запускает Процесс 2 на центральном процессоре, в то время как дисковые службы обрабатывают запрос Процесса 1. Когда запрос диска завершен, происходит прерывание, и операционная система пробуждает Процесс 1 и запускает его снова. Таким образом, и центральный процессор, и диск используются должным образом в течение среднего промежутка времени.
Обратите внимание, что использование прерываний не всегда является лучшим решением. Например, представьте себе устройство, которое выполняет свои задачи очень быстро: при первом опросе обычно обнаруживается, что устройство завершило выполнение задачи. Использование прерывания в этом случае фактически замедлит работу системы: переключение на другой процесс, обработка прерывания и возвращение к процессу обходятся дорого. Таким образом, если устройство работает быстро, возможно, лучше всего использовать polling; если оно работает медленно, лучше всего использовать прерывания, которые дают лучшую утилизацию ресурсов.
СОВЕТ: ПРЕРЫВАНИЯ НЕ ВСЕГДА ЛУЧШЕ, ЧЕМ PIO
Хотя прерывания допускают перекрытие вычислений и ввода-вывода, на самом деле они имеют смысл только для медленных устройств. В противном случае затраты на обработку прерываний и переключение контекста могут перевесить преимущества, которые предоставляют прерывания. Также бывают случаи, когда поток прерываний может перегрузить систему и привести ее к livelock [MR96]; в таких случаях polling предоставляет ОС больше контроля над ее планированием и, таким образом, полезен.
Если скорость устройства неизвестна или иногда быстрая, а иногда медленная, возможно, лучше всего использовать гибрид, который некоторое время проводит опрос, а затем, если устройство еще не завершило работу, использует прерывания. Этот двух этапный подход может обеспечить лучшее из обоих миров.
Еще одна причина не использовать прерывания возникает в сетях [MR96]. Когда каждый из огромного потока входящих пакетов генерирует прерывание, ОС может перейти в режим активной блокировки (livelock), то есть обнаружить, что она обрабатывает только прерывания и никогда не позволяет процессу пользовательского уровня запускаться и фактически обслуживать запросы. Например, представьте себе веб-сервер, который испытывает скачок нагрузки из-за того, что он занял первое место в hacker news [H18]. В этом случае лучше время от времени использовать опрос, чтобы лучше контролировать происходящее в системе и позволить веб-серверу обработать некоторые запросы, прежде чем возвращаться к устройству для проверки поступления новых пакетов.
Другой оптимизаций, основанной на прерываниях, является объединение (coalescing). При такой настройке устройство, которому необходимо вызвать прерывание, ожидает некоторое время, прежде чем передать прерывание центральному процессору. Во время ожидания другие запросы могут вскоре завершиться, и, таким образом, несколько прерываний могут быть объединены в единую доставку прерываний, что снижает накладные расходы на обработку прерываний. Конечно, слишком долгое ожидание увеличит задержку запроса, что является распространенным компромиссом в системах. См. отличное резюме Ahmad и др. [A+11].
36.5 Более эффективное перемещение данных с помощью DMA
К сожалению, есть еще один аспект нашего канонического протокола, который требует нашего внимания. В частности, при использовании программируемого ввода-вывода (PIO) для передачи большого объема данных на устройство центральный процессор снова перегружается довольно тривиальной задачей и, таким образом, тратит много времени и усилий, которые лучше было бы потратить на выполнение других процессов. Эта временная шкала иллюстрирует проблему:
На временной шкале запущен процесс 1, который затем хочет записать некоторые данные на диск. Затем он инициирует ввод-вывод, который должен явно скопировать данные из памяти на устройство, по одному слову за раз (обозначено c на диаграмме). Когда копирование завершено, на диске начинается ввод-вывод, и центральный процессор, наконец, можно использовать для чего-то другого.
ЗАДАЧА: КАК СНИЗИТЬ НАКЛАДНЫЕ РАСХОДЫ НА PIO
При использовании PIO центральный процессор тратит слишком много времени на ручное перемещение данных на устройства и обратно. Как мы можем разгрузить эту работу и, таким образом, позволить процессору использоваться более эффективно?
Решением этой проблемы является то, что мы называем прямым доступом к памяти (DMA - Direct Memory Access). Механизм DMA - это, по сути, очень специфическое устройство в системе, которое может организовывать передачу данных между устройствами и основной памятью без особого вмешательства центрального процессора.
DMA работает следующим образом. Например, чтобы передать данные на устройство, операционная система запрограммировала бы механизм DMA, сообщив ему, где данные хранятся в памяти, сколько данных нужно скопировать и на какое устройство их отправить. На этом этапе операционная система завершает перенос и может приступать к другой работе и в работу включается DMA. Когда DMA завершает работу, контроллер DMA вызывает прерывание, и, таким образом, операционная система знает, что передача завершена. Пересмотренная временная шкала:
На временной шкале вы можете видеть, что копирование данных теперь обрабатывается контроллером DMA. Поскольку в течение этого времени центральный процессор свободен, ОС может сделать что-то еще, выбрав здесь запуск процесса 2. Таким образом, процесс 2 получает возможность использовать больше ЦП, прежде чем процесс 1 запустится снова.
36.6 Способы Взаимодействия Устройств
Теперь, когда у нас есть некоторое представление о проблемах эффективности, связанных с выполнением ввода-вывода, есть еще несколько проблем, с которыми нам необходимо справиться, чтобы интегрировать устройства в современные системы. Одна проблема, которую вы, возможно, заметили к этому моменту: мы на пока ничего не сказали о том, как ОС на самом деле взаимодействует с устройством! Таким образом, проблема:
КАК ВЗАИМОДЕЙСТВОВАТЬ С УСТРОЙСТВАМИ
Как аппаратное обеспечение должно взаимодействовать с устройством? Должны ли быть четкие инструкции? Или есть другие способы сделать это?
Со временем появились два основных метода взаимодействия устройств. Первый, самый старый метод (используемый мэйнфреймами IBM в течение многих лет) заключается в наличии явных инструкций ввода-вывода. Эти инструкции определяют способ отправки данных операционной системой в определенные регистры устройств и, таким образом, позволяют создавать протоколы, описанные выше.
Например, на x86 инструкции in и out могут использоваться для взаимодействия с устройствами. Например, чтобы отправить данные на устройство, вызывающий объект указывает регистр с содержащимися в нем данными и определенный порт, который присваивает устройству имя. Выполнение инструкции приводит к желаемому поведению.
Такие инструкции обычно являются привилегированными (privileged). Операционная система управляет устройствами, и, таким образом, операционная система является единственным объектом, которому разрешено напрямую взаимодействовать с ними. Представьте, если бы какая-либо программа могла прочитать или записать диск, например: полный хаос (как всегда), поскольку любая пользовательская программа могла бы использовать такую лазейку, чтобы получить полный контроль над машиной.
Второй способ взаимодействия с устройствами известен как ввод-вывод с отображением в память (memory-mapped I/O). При таком подходе аппаратное обеспечение делает регистры устройств доступными, как если бы они были ячейками памяти. Чтобы получить доступ к определенному регистру, ОС выдает команду load (для чтения) или store (для записи) адрес; затем аппаратное обеспечение направляет загрузку/сохранение на устройство вместо основной памяти.
В том или ином подходе нет какого-то большого преимущества. Подход с отображением в память хорош тем, что для его поддержки не требуется никаких новых инструкций, но оба подхода все еще используются сегодня.
36.7 Встраивание в Операционную систему: Драйвер устройства
И последняя проблема, которую мы обсудим: как встроить устройства, каждое из которых имеет очень специфические интерфейсы, в операционную систему, которую мы хотели бы сохранить как можно более общей. Например, рассмотрим файловую систему. Мы хотели бы создать файловую систему, которая работала бы поверх SCSI-дисков, IDE-дисков, USB-накопителей keychain и так далее, и мы хотели бы, чтобы файловая система относительно не обращала внимания на все детали того, как отправлять запрос на чтение или запись на эти различные типы дисков. Таким образом, наша проблема:
КАК СОЗДАТЬ ОС, НЕ ЗАВИСЯЩУЮ ОТ УСТРОЙСТВА
Как мы можем сохранить большую часть операционной системы нейтральной к устройствам, скрыв таким образом детали взаимодействия устройств от основных подсистем операционной системы?
Проблема решается с помощью техники абстракции вековой давности. На самом низком уровне часть программного обеспечения в операционной системе должна в деталях знать, как работает устройство. Мы называем эту часть программного обеспечения драйвером устройства, и любые особенности взаимодействия с устройством инкапсулированы в нем.
Давайте посмотрим, как эта абстракция может помочь в разработке и реализации операционной системы, изучив программный стек файловой системы Linux. Рисунок 36.4 представляет собой грубое и приблизительное изображение организации программного обеспечения Linux. Как вы можете видеть из диаграммы, файловая система (и, конечно же, приложение, описанное выше) совершенно не обращает внимания на специфику того, какой класс диска она использует; он просто отправляет запросы на чтение и запись блоков на общий уровень блоков, который направляет их соответствующему драйверу устройства, который обрабатывает детали выдачи конкретного запроса. Несмотря на упрощенность, диаграмма показывает, как такие детали могут быть скрыты от большинства ОС.
На диаграмме также показан raw interface к устройствам, который позволяет специальным приложениям (таким как file-system checker, описанное ниже [AD14], или инструмент дефрагментации диска) напрямую считывать и записывать блоки без использования файловой абстракции. Большинство систем предоставляют такой тип интерфейса для поддержки этих низкоуровневых приложений управления хранилищем.
Обратите внимание, что описанная выше инкапсуляция также может иметь свою обратную сторону. Например, если есть устройство, которое обладает множеством специальных возможностей, но должно предоставлять общий интерфейс для остальной части ядра, эти специальные возможности останутся неиспользованными.Такая ситуация возникает, например, в Linux с устройствами SCSI, которые имеют очень богатые отчеты об ошибках; поскольку другие блочные устройства (например, ATA/IDE) имеют гораздо более простую обработку ошибок, все, что когда-либо получает программное обеспечение более высокого уровня, - это общий код ошибки EIO (generic IO error); любая дополнительная информация, которую, возможно, предоставил SCSI, таким образом, теряется в файловой системе [G08].
Интересно, что поскольку драйверы устройств необходимы для любого устройства, которое вы можете подключить к своей системе, со временем они стали составлять огромный процент кода ядра. Исследования ядра Linux показывают, что более 70% кода операционной системы содержится в драйверах устройств [C01]; для систем на базе Windows этот показатель, вероятно, также довольно высок. Таким образом, когда люди говорят вам, что ОС содержит миллионы строк кода, на самом деле они имеют в виду, что ОС содержит миллионы строк кода драйвера устройства. Конечно, для любой данной установки большая часть этого кода может быть неактивна (т.е. к системе одновременно подключено только несколько устройств). Возможно, что еще более удручающе, поскольку драйверы часто пишутся “любителями” (вместо штатных разработчиков ядра), они, как правило, содержат гораздо больше ошибок и, таким образом, являются основной причиной сбоев ядра [S03].
36.8 Пример из практики: Простой драйвер диска IDE
Чтобы копнуть немного глубже, давайте кратко рассмотрим реальное устройство: дисковод IDE [L94]. Мы кратко описываем протокол, как описано в этой ссылке [W10]; мы также заглянем в исходный код xv6 для простого примера работающего драйвера IDE [CK+08].
IDE-диск представляет собой простой интерфейс к системе, состоящий из четырех типов регистров: контрольный (control), командный блок (command block), статус (status) и ошибка (error). Эти регистры доступны путем считывания или записи на определенные “адреса ввода-вывода” (например, 0x3F6 ниже) с использованием (на x86) инструкций ввода-вывода in и out.
Базовый протокол взаимодействия с устройством выглядит следующим образом, при условии, что оно уже инициализировано.
- Дождитесь, пока привод будет готов. Считывайте регистр состояния (0x1F7) до тех пор, пока диск ни будет готов и не будет занят.
- Запишите параметры в командные регистры. Запишите количество секторов, адрес логического блока (LBA) секторов, к которым требуется доступ, и номер диска (master=0x00 или slave=0x10, поскольку IDE допускает только два диска) в командные регистры (0x1F2-0x1F6).
- Запустите ввод-вывод, выполнив команду чтения/записи в командный регистр. Запишите команду ЧТЕНИЯ—ЗАПИСИ в командный регистр (0x1F7).
- Передача данных (для записи): Дождитесь, пока значение в регистре статуса будет READY, и DRQ (drive request for data); запишите данные в порт передачи данных
- Обработка прерываний. В простейшем случае обработайте прерывание для каждого передаваемого сектора; более сложные подходы допускают пакетное выполнение и, таким образом, одно окончательное прерывание выполняется, когда вся передача завершена.
- Обработка ошибок. После каждой операции считывайте регистр состояния. Если бит ОШИБКИ включен, ознакомьтесь с регистрацией ошибок для получения подробной информации.
Большая часть этого протокола содержится в драйвере IDE xv6 (рис. 36.6), который (после инициализации) работает с помощью четырех основных функций. Первая - ide_rw(), которая ставит запрос в очередь (если есть другие ожидающие выполнения) или отправляет его непосредственно на диск (через ide_start_request()); в любом случае процедура ожидает завершения запроса, и вызывающий процесс переводится в спящий режим. Вторая ide_start_request(), которая используется для отправки запроса (и, возможно, данных, в случае записи) на диск; инструкции in и out x86 вызываются для чтения и записи регистров устройства соответственно. Процедура запроса запуска использует третью функцию, ide_wait_ready(), чтобы убедиться, что диск готов, прежде чем отправлять ему запрос. Наконец, ide_intr() вызывается при возникновении прерывания; он считывает данные с устройства (если запрос предназначен для чтения, а не для записи), запускает процесс, ожидающий завершения ввода-вывода, и (если в очереди ввода-вывода больше запросов) запускает следующий ввод-вывод через ide_start_request().
36.9 Исторические заметки
Прежде чем закончить, мы приведем краткую историческую справку о происхождении некоторых из этих фундаментальных идей. Если вам интересно узнать больше, прочтите превосходное резюме Smotherman [S08].
Прерывания - это древняя идея, существовавшая на самых ранних машинах. Например, UNIVAC в начале 1950-х годов имел некоторую форму векторизации прерываний, хотя неясно, в каком именно году эта функция была доступна [S08]. К сожалению, даже в зачаточном состоянии мы начинаем утрачивать истоки компьютерной истории.
Также ведутся некоторые споры о том, какая машина первой внедрила идею DMA. Например, Кнут и другие указывают на DYSEAC (“мобильную” машину, что в то время означало, что ее можно было перевозить в прицепе), в то время как другие считают, что IBM SAGE, возможно, была первой [S08]. В любом случае, к середине 50-х годов существовали системы с устройствами ввода-вывода, которые напрямую взаимодействовали с памятью и передавали прерывание центральному процессору по завершении работы.
Историю здесь трудно проследить, потому что изобретения связаны с реальными, а иногда и малоизвестными машинами. Например, некоторые думают, что машина Lincoln Labs TX-2 была первой с векторными прерываниями [S08], но это не ясно до конца.
Поскольку идеи относительно очевидны — не требуется никакого эйнштейновского скачка, чтобы прийти к идее позволить процессору делать что—то еще, пока выполняется медленный ввод-вывод, - возможно, наше сосредоточение на вопросе “кто первый?” ошибочно. Что, безусловно, ясно: по мере того, как люди создавали эти ранние машины, стало очевидно, что необходима поддержка ввода-вывода. Прерывания, DMA и связанные с ними идеи - все это прямые следствия природы быстрых процессоров и медленных устройств; если бы вы были там в то время, у вас могли бы возникнуть похожие идеи.
36.10 Резюме
Теперь у вас должно быть очень общее представление о том, как операционная система взаимодействует с устройством. Были представлены два метода, прерывание и DMA, которые помогают повысить эффективность устройства, и описаны два подхода к доступу к регистрам устройства: явные инструкции ввода-вывода и ввод-вывод с отображением в память. Наконец, было представлено понятие драйвера устройства, показывающее, как сама ОС может инкапсулировать низкоуровневые детали и, таким образом, упростить сборку остальной части ОС способом, не зависящим от устройства.
Ccылки
[A+11] “vIC: Interrupt Coalescing for Virtual Machine Storage Device IO” by Irfan Ahmad, Ajay Gulati, Ali Mashtizadeh. USENIX ’11. A terrific survey of interrupt coalescing in traditional and virtualized environments.
[AD14] “Operating Systems: Three Easy Pieces” (Chapters: Crash Consistency: FSCK and Journaling and Log-Structured File Systems) by Remzi Arpaci-Dusseau and Andrea Arpaci-Dusseau. Arpaci-Dusseau Books, 2014. A description of a file-system checker and how it works, which requires low-level access to disk devices not normally provided by the file system directly.
[C01] “An Empirical Study of Operating System Errors” by Andy Chou, Junfeng Yang, Benjamin Chelf, Seth Hallem, Dawson Engler. SOSP ’01. One of the first papers to systematically explore how many bugs are in modern operating systems. Among other neat findings, the authors show that device drivers have something like seven times more bugs than mainline kernel code.
[CK+08] “The xv6 Operating System” by Russ Cox, Frans Kaashoek, Robert Morris, Nickolai Zeldovich. From: http://pdos.csail.mit.edu/6.828/2008/index.html. See ide.c for the IDE device driver, with a few more details therein.
[D07] “What Every Programmer Should Know About Memory” by Ulrich Drepper. November, 2007. Available: http://www.akkadia.org/drepper/cpumemory.pdf. A fantastic read about modern memory systems, starting at DRAM and going all the way up to virtualization and cache-optimized algorithms.
[G08] “EIO: Error-handling is Occasionally Correct” by Haryadi Gunawi, Cindy Rubio-Gonzalez, Andrea Arpaci-Dusseau, Remzi Arpaci-Dusseau, Ben Liblit. FAST ’08, San Jose, CA, February 2008. Our own work on building a tool to find code in Linux file systems that does not handle error return properly. We found hundreds and hundreds of bugs, many of which have now been fixed
[H17] “Intel Core i7-7700K review: Kaby Lake Debuts for Desktop” by Joel Hruska. January 3, 2017. www.extremetech.com/extreme/241950-intels-core-i7-7700k-reviewed-kaby-lake-debuts-desktop. An in-depth review of a recent Intel chipset, including CPUs and the I/O subsystem.
[H18] “Hacker News” by Many contributors. Available: https://news.ycombinator.com. One of the better aggregators for tech-related stuff. Once back in 2014, this book became a highly-ranked entry, leading to 1 million chapter downloads in just one day! Sadly, we have yet to re-experience such a high.
[L94] “AT Attachment Interface for Disk Drives” by Lawrence J. Lamers. Reference number: ANSI X3.221, 1994. Available: ftp // ftp t10.org/t13/project/d0791r4c-ATA-1.pdf. A rather dry document about device interfaces. Read it at your own peril.
[MR96] “Eliminating Receive Livelock in an Interrupt-driven Kernel” by Jeffrey Mogul, K. K. Ramakrishnan. USENIX ’96, San Diego, CA, January 1996. Mogul and colleagues did a great deal of pioneering work on web server network performance. This paper is but one example.
[S08] “Interrupts” by Mark Smotherman. July ’08. Available: http://people.cs.clemson.edu/mark/interrupts.html. A treasure trove of information on the history of interrupts, DMA, and related early ideas in computing.
[S03] “Improving the Reliability of Commodity Operating Systems” by Michael M. Swift, Brian N. Bershad, Henry M. Levy. SOSP ’03. Swift’s work revived interest in a more microkernel-like approach to operating systems; minimally, it finally gave some good reasons why address-space based protection could be useful in a modern OS.
[W10] “Hard Disk Driver” by Washington State Course Homepage. Available online at this site: http://eecs.wsu.edu/˜cs460/cs560/HDdriver.html. A nice summary of a simple IDE disk drive’s interface and how to build a device driver for it.
ps - изображение - галлюцинации нейросети шедеврум