Предыдущая часть:
В предыдущей части было решено увеличить количество потоков.
Это просто. Вот как делался один поток:

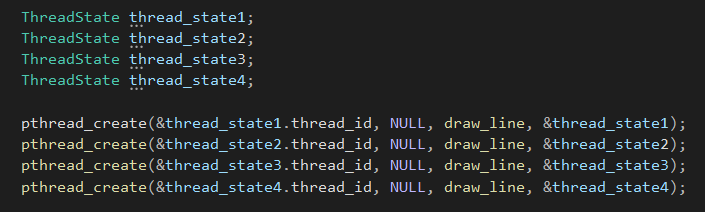
Надо просто повторить это несколько раз, дав каждому потоку свою структуру данных:
Но мы тогда упрёмся в следующую проблему. Вот как поток читает данные из буфера:
Пока в буфере нет данных, все потоки стоят на месте. Когда в буфере появились данные, условие work_tail == work_head нарушается и потоки могут преодолеть барьер.
То есть после появления данных у нас может возникнуть любое количество потоков, которые преодолели барьер. Все они начнут читать данные из буфера, и либо прочитают одно и то же, либо вообще что-то неправильное.
Очевидно, чтение из буфера должно быть синхронизировано, чтобы доступ к буферу и к указателю хвоста имел только один поток за один раз.
Блокировки
Можно сделать блокировку следующим образом. Введём глобальную переменную buffer_lock.
Теперь делаем сам буфер доступным или недоступным для чтения. То есть не данные в буфере (которые там могут быть или не быть), а сам буфер как структуру. Если буфер доступен для чтения, то переменная buffer_lock будет равна 0, а если нет, то 1.
Теперь в поток добавим проверку на блокировку буфера:
Проверка делается самой первой. Пока буфер занят, мы находимся в ожидании, а как только он освободился, мы сами занимаем его, устанавливая значение buffer_lock = 1. Теперь мы владеем буфером и снова находимся в ожидании, когда в него попадут данные. Всё это время буфер блокирован для других потоков, но это не страшно, так как в нём всё равно нет данных.
Когда мы прочитали данные, то сдвигаем хвост и освобождаем буфер, устанавливая значение buffer_lock = 0. Пусть теперь им занимаются другие потоки.
Но
Такая схема может работать только если повезёт, так как имеет один изъян. Когда мы дождались снятия блокировки и переходим к тому, чтобы установить собственную блокировку, между этими двумя операциями может вклиниться другой поток, который также увидел окончание блокировки. Но мы об этом уже не узнаем. Значит, данная схема не даёт никаких гарантий синхронизации.
Поиски решения без должной подготовки будут постоянно заводить в один и тот же тупик: если узнать значение, а потом изменить его, ничто не гарантирует, что кто-то узнал и изменил его раньше.
По этому поводу рекомендую почитать труд Э. Дейкстры "Кооперативные последовательные процессы", где он разбирает множество подобных примеров и даёт их решения. Или вот есть он же в PDF. Труд написан давно, но актуален и сейчас. Он очень занудный пунктуальный и подробный, что способствует лучшему пониманию.
Ну а мы пока будем использовать...
Мьютексы
Слово mutex происходит от mutually exclusive, то есть взаимно исключающий.
Мьютексом называется переменная-ресурс, который мы можем монопольно захватывать. Механизм захвата подразумевает всё то, что описано выше: дождаться освобождения блокировки, заблокировать самому, но реализован он уже корректным способом, поэтому нам не надо об этом беспокоиться.
Добавляем переменную mutex со специальным типом pthread_mutex_t:
Затем инициализируем её, то есть готовим к работе:
И уже внутри функции потока пишем захват и освобождение мьютекса:
Критическая секция начинается с pthread_mutex_lock() и заканчивается с pthread_mutex_unlock().
Теперь можно запустить несколько потоков, и программа будет работать корректно. Путём экспериментов я вывел оптимальное количество потоков – 4 штуки. Это позволяет ускорить программу в 2.5 раза. Почему не в 4 раза?
Самое заметное ускорение (почти в 2 раза) получается, когда создаются 2 потока. Когда добавляется третий, ускорение уже не настолько большое, а когда добавляется четвёртый, оно уже почти незаметное. Дальнейшее добавление потоков уже ничего не даёт.
То, насколько всё будет работать эффективно, зависит конечно же от числа ядер процессора и от их текущей загруженности. У меня получилось вот так.
Полная версия программы лежит в git:
https://github.com/nandakoryaaa/raster_triangle/blob/main/src/triangles_grad_threads.c
Думаю, что тут есть ещё простор для оптимизации, но это уже не сильно важно, так как основной задачей было получить корректный мультипоточный процесс.
Проблема мьютекса заключается в том, что он реализован в языке C, но может быть не реализован в других языках. Там могут быть свои средства синхронизации, которые опять же есть только в них. Хочется получить некий универсальный механизм, который можно во-первых осмыслить, а во-вторых самостоятельно реализовать на чём угодно и в любой среде.
Поэтому дальше я буду описывать алгоритмы от старика Дейкстры.



















