Дисклеймер: данная публикация была написана без использования ИИ.
Привет, читатель! Ниже я расскажу, как установить на компьютер нейросеть, которая сможет делать почти все, что умеет делать чатгпт: писать тексты, программы, болтать и т.д. Фишка в том, что все это будет крутиться локально на твоем компьютере.
Содержание:
- Для чего оно надо?
- Что для этого нужно?
- В чем суть?
- Как это установить?
- Для тех, кому лень читать.
Для чего оно надо?
1. Джаст фор фан. Да, если у тебя есть доступ к настоящему ChatGPT, а сегодня его получить не так уж и сложно, то от локальной установки какой-то особой пользы ты не получишь. Кроме этого прекрасного чувства, когда зародыш искусственного интеллекта сидит в твоем компьютере и находится полностью в твоей власти, апхахаха.
2. Анонимность. Если ты не хочешь, чтобы твои запросы читали, сохраняли и анализировали пендосские программисты, а также админы всевозможных телеграм GPT ботов, то ты пришел по адресу. Не забывай, товарищ, все что ты вводишь в интернете, в будущем будет использовано против тебя. Локальная нейросеть избавлена от этого недостатка, все твои запросы остаются на твоем компьютере. Твои темные делишки в безопасности. Но все равно не рекомендую у нее спрашивать как варить мет или напалм, не потому что незаконно, а потому что есть большая вероятность, что наврет в рецептуре.
3. На случай большого звездеца. Мы все живем в неспокойное время, сегодня ты цифровой человек 24/7 подключенный к интернету на скорости в сотни мегабит/с, а завтра ты сидишь в подвале/бункере даже без EDGE и, под мирное потрескивание счетчика Гейгера, судорожно ищешь диск со вторым фолычем или третьими героями. Ну и кто ты без своего интернета? Гений, миллиардер, плейбой, филантроп. А подготовься ты заранее, то будет с кем поговорить или у кого спросить совета. Люди делятся на два типа, те кто уже скачал полную библиотеку либрусека флибусты на компьютер и тех кто только хочет это сделать. Теперь можно скачать еще и нейросеть и быть готовым к апокалипсису на 100%.
Что для этого нужно?
Компьютер. Спасибо, кэп. Нейросеть стремящаяся быть похожей на ChatGPT жрет дофига ресурсов компа. Да, я тоже видел, как умельцы установили подобную нейросеть локально на смартфон. Но! Есть прямо пропорциональная зависимость между тем насколько нейросеть умна и сколько она требует оперативной памяти (у кого есть видеокарта - видеопамяти).
Итак:
- нужен комп с хотя бы 16 ГБ оперативки, лучше 32 ГБ, еще больше еще лучше.
- нужно примерно 20 ГБ свободного места на жестком диске компа, лучше побольше.
Это был минимум, чтобы оно заработало, если хочешь, чтобы работало быстро, то можно вместо оперативной памяти использовать память видеокарты или использовать и то, и то. Процессор тоже влияет на скорость, но по сути, если ты будешь ждать ответа не 30 секунд, а, например, 2 минуты, то все, что ты потеряешь - это полторы минуты.
Я использую 8 ядерный процессор, 32 ГБ оперативки и не использую видеокарту, гребаные майнеры.
В чем суть?
Это необязательный раздел теории, который можно пропустить и сразу перейти к установке.
Большая языковая модель (LLM) - это именно то, что перевернуло (ну немножко пошатнуло) нашу жизнь примерно пол года назад, когда мы все услышали про ChatGPT.
LLM (ларге лангуаге модел) - это нейросеть, которую научили угадывать слова, то есть скармливают ей незаконченное предложение, нейросеть пытается угадать недостающее слово, если угадывает - получает пирожок увеличивает веса параметров, которые привели ее к этому слову, если не угадывает, получает по жопе веса уменьшает. Элементарно. И если у тебя есть огромные вычислительные мощности и много данных в текстовом формате, то ты можешь обучить еще один чатгпт. Так, собственно, много кто поступает, например, Яндекс и даже обычные энтузиасты.
Примечание. На этом моменте читатель должен понять, что ЧатГПТ нифига не искусственный интеллект, а просто угадыватель подходящих по контексту слов.
Модель (нейросеть) состоит из миллиардов параметров. Параметр в этой модели - это число с плавающей точкой и занимающее 2 байта памяти. То есть, на каждый миллиард параметров нужно 2 ГБ памяти. Для понимания пропасти отделяющей нас от пендосских корпораций: у ChatGPT 4, говорят, порядка 500 миллиардов параметров.
Нам сейчас доступны модели с 60 млрд, 30 млрд, 13 млрд и 7 млрд параметров (мы будем запускать модель с 30 млрд параметров). Казалось бы, все равно требует дофига памяти и на пк не запустить. Но на помощь нам приходит ggml и квантование.
GGML - это библиотека для C, которая позволяет, кроме всего прочего, упаковывать большие языковые модели (LLM) в двоичный формат. В рунете (кто-то еще использует это слово?) почти нет материала про GGML, тут его тоже не будет, но приведу хотя бы расшифровку: GGML - Georgi Gerganov machine learning. Да, болгарский(?) программист Георгий Геранов просто назвал библиотеку своим именем.
Квантование - красивое футуристичное слово, но в данном контексте означает всего лишь процесс округления параметров (весов) в большой языковой модели. Если помнишь, выше ты читал про 2 байта памяти на один параметр, квантование позволяет округлить (не совсем округлить, но сути не меняет) число, занимающее 2 байта, до числа занимающее 8 бит или 4 бита, или даже 2 бита. Конечно это сказывается на "интеллекте" нейросети, но не так сильно, как может показаться.
Благодаря этому мы можем запускать модели содержащие миллиарды параметров у себя на компьютере и параллельно еще во что-нибудь играть.
Примечание. Счастливым обладателям мощных видеокарт, стоит погуглить пояндексить GPTQ, по сути то же самое но, работает на видеокартах, а не в оперативке.
Как это установить?
Переходим к сути гойда гайда. Тебе понадобится модель (нейрость) и интерпретатор - графический интерфейс.
Модели находятся на буржуйском сайте https://huggingface.co/ . Там их дохеовер9000 штук. Модели выкладывают энтузиасты и не только, многие заточены под какие-то специальные цели, например, рассказывать анекдоты. Все они постоянно обновляются. Так как же выбрать ту самую модель, которая будет идеальной? Вопрос не тривиальный. Есть рейтинги, есть отзывы. Возможно в одной из следующих публикаций я проведу сравнительный тест нескольких моделей, а пока посоветую ту модель, что советуют все, миллионы мух же не могут ошибаться, да?
WizardLM-30B-Uncensored-GGML - для тех у кого 32ГБ оперативки;
WizardLM-13B-V1.0-Uncensored-GGML - для тех у кого 16 ГБ оперативки (Для тех у кого ОЗУ еще меньше, стоит поискать версии 7B).
Мой выбор пал на эту модель совсем не из-за слов "Без цензуры" в названии, нет. Хотя возможность обсудить политику многого стоит. Ты только посмотри, как о ней отзываются наши пендосские друзья.
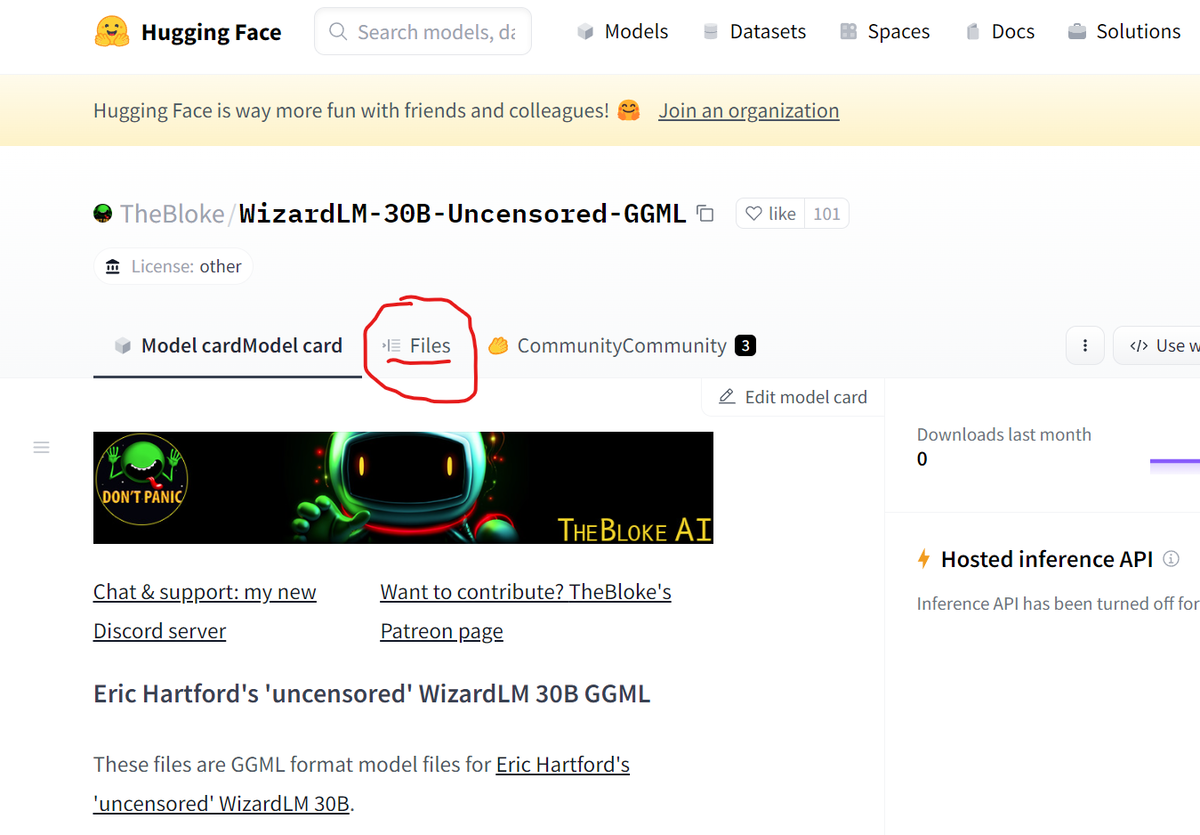
Итак, переходи по указанной выше ссылке на страницу конкретной модели. Там есть три вкладки: model card, files и community. На вкладке карточка модели все о ней подробно рассказано, в том числе есть таблица, в которой расписано, какой файл сколько оперативы жрет, советую ознакомиться. Переходи на вкладку Files.
На этой вкладке найди файлы оканчивающиеся на q4_0.bin. Цифра 4 - означает квантование до 4 бит, чем больше цифра, тем ближе к оригиналу модель, но те больше ресурсов она требует. Файлы с названием оканчивающимся на букву K - проквантованы более совершенным способом, но не все интерпретаторы их понимают. Если коротко, то в них размер параметра плавающий, то есть некоторые параметры 2 бита занимают, другие 3 бита, третьи 4 бита, это позволяет еще больше сэкономить места. Особой разницы с обычным квантованием я не заметил.
Скачивай подходящий файл, я взял WizardLM-30B-Uncensored.ggmlv3.q5_1.bin.
Примечание. Скачивать лучше специальной программой, поддерживающей многопоточную закачку и возобновление, иначе это займет много времени. Я использую uget (не реклама).
Графический интерфейс. Они бывают всякие разные, от копии ChatGPT, до просто запуска в командной строке (это уже не gui, а cli?). Все они основаны на llama.cpp Разбор этих интерфейсов возможно сделаю в будущих публикациях. Сейчас же советую тебе использовать самый простой и похожий на ChatGPT интерфейс - Alpaca Electron. Скачать его можно по ссылке: https://github.com/ItsPi3141/alpaca-electron/releases .
Скачиваешь, устанавливаешь, запускаешь. Появится такое окошко:
В нем жмешь по кнопке change model и выбираешь ранее скаченную ggml модель. Да, говорят в пути к файлу не должно быть русских букв, хз правда ли это. Все нейросеть у тебя на компе, можешь задавать вопросы.
Для тех, кому лень читать.
Скачиваешь модель отсюда:
WizardLM-30B-Uncensored-GGML - для тех у кого 32ГБ оперативки;
WizardLM-13B-V1.0-Uncensored-GGML - для тех у кого 16 ГБ оперативки.
Скачиваешь программу отсюда:
https://github.com/ItsPi3141/alpaca-electron/releases .
Устанавливаешь программу и в ней выбираешь скаченную модель. Все, ты восхитителен.