Сводная статья для workshop
Для менеджеров
1. Введение в термины
Термином «Искусственная Нейронная Сеть» или просто «Нейронная Сеть» часто обозначают математическую модель. В изначальной подаче считается, что работа Нейронной сети похожа на работу человеческого мозга с точки зрения коммуникаций между нейронами, отсюда и название, хотя вопрос дискуссионный.
Можно лишь уверенно сказать, что у модели есть базовая математика с огромным количеством вычислений, такими как векторные и матричные умножения, логарифмы и производные.
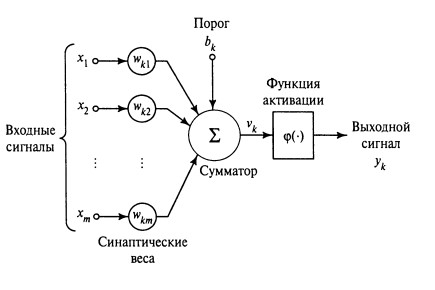
В большинстве случаев для реальных практических задач нейронные сети являются многослойными, откуда и возник термин "Deep Learning", то есть глубокое обучение или обучение "глубокой" многослойной сети.
Говорят, что все модели неточны, но некоторые помогают.
Действительно, никто не видел силу тяжести, но есть известная формула mg, и на основании ее можно рассчитать расстояние, скорость, время и так далее. Расчеты достаточно хорошо совпадают с фактами, точнее, находятся в рамках заданного допустимого уровня погрешности, и это всех или многих устраивает. С Нейронными сетями ситуация аналогичная. Не всегда проходящие внутренние процессы поддаются трактовке в привычном человеческом понимании, хотя конечный результат может быть вполне приемлем.
В большинстве случаев обучение нейронной сети заключается в подборе набора параметров, дающий оптимальный результат для конкретной задачи.
Вычислений очень много, но все они очень похожи. Векторные умножения сейчас заложены прямо в железо, происходят очень быстро, и рост производительности микросхем очень существенно повлиял на развитие нейронных сетей.
Если раньше нужно было годами теоретизировать и доказывать теоремы, то сейчас возможно запустить прямой циклический перебор с разными вариациями и модель пойдет считать, и при правильном подборе архитектуры через некоторое время выдаст набор параметров, дающих приемлемый результат для конкретной задачи.
Конечно, данное описание очень и очень упрощено, но нам как пользователям многие внутренние нюансы и не важны, важен конечный результат.
На этом можно завершить поверхностную теоретическую часть и перейти к практическому применению в ежедневных бизнес-процессах.
Прежде всего применения Искусственного Интеллекта и Искусственных Нейронных Сетей в Корпорации целесообразно разделить на два сегмента:
1. Что можно применять самостоятельно
2. Что можно поручить разработчикам и применять после разработки
Данная статья посвящена тому, что "можно поручить разработчикам и применять после разработки".
Сегмент "что можно применять самостоятельно" представлен в других статьях, например, в этой, и список может постепенно дополняться.
Далее целесообразна следующая классификация:
1. Компьютерное зрение (Computer Vision)
2. Большие языковые модели (LLM - Large Language Model)
3. Общее, прочее, разное
Компьютерное зрение
(Computer Vision)
Варианты применения
1. Распознавание изображений
2. Классификация изображений (котик / собачка, паспорт / не паспорт, какой тип лютика, какая цифра)
3. Определение объектов на изображении (какие объекты изображены на изображении, текстовое описание происходящего)
4. Определение наличия объекта на изображении (есть котик / нет котика, в маске / не в маске
5. Определение местоположение объекта на изображении (обводит контур)
6. Сегментация изображения (закрашивает объекты разным цветом)
7. Определение эмоций, жестов, расы, пола, возраста, наклонностей угрожающих действий (зависит от библиотек, постепенно расширяется)
8. Распознавание лиц (распознает лица по ключевым точкам, применимо в сфере безопасности и авторизации)
9. Восстановление пропущенных фрагментов на изображении
10. Перенос стиля, смешивание изображений
Обработка естественного языка
(NLP - Natural Language Processing)
В сфере NLP наиболее распространены GPT-модели.
GPT - Generative Pre-trained Transformer
(Генеративный предобученный трансформер)
"Нашумевший" ChatGPT-3 - как раз из этой серии.
Можно сказать, что есть GPT и GPT-like модели, и потом все остальные.
Если языковая модель что-либо генерирует в одну сторону, чаще всего "слева направо", то в общем случае чаще всего это будет GPT или GPT-like. Если языковая модель что-либо анализирует, классифицирует или "генерирует в обе стороны", то в общем случае чаще всего это будет BERT или BERT-like, хотя определенные классификации возможны сразу и на GPT.
Все остальные модели, типа LSTM и прочие, популярные недавно, постепенно уступают и применяются все реже и реже.
Варианты применения
1. Машинный перевод (в сфере иностранных языков)
2. Генерация текста (новости, статьи, истории). Используется как для чат-ботов в режиме "болталка" для поддержания общей беседы. Может подключаться к чатам для удержания клиента на ресурсе.
3. Генерация текста с учетом дозагруженных собственных данных. Есть много настроек, позволяющих настраивать распределение и выбор модели между общими и дозагруженными данными. Применим для генерации контекста, более коррелирующего с собственными загруженными данными. Пример - генерация реплик о финансовых рынках, но не основе общих данных и википедии, а на основе подобранной литературы и собственных баз знаний.
4. Стилизация текста. Генерация текста в заданном стиле. Например, в стиле Достоевского или в стиле Пушкина. В общем случае аналогично пункту 3.
3. Классификация текста (токсично / не токсично, позитивно / негативно, последовательно / непоследвательно). Применимо для классификации комментариев.
4. Суммаризация текста.(Большой текст превращается в маленький или в заголовок)
5. Подстановка пропущенных слов
6. Определение ближайшего по смыслу слова
7. Определение ближайшего по смыслу текста (применимо для поддержки пользователей при наличии детерминированной Базы Знаний формата "Вопрос-Ответ" из FAO-раздела, сеть ищет ближайший по смыслу запрос из Базы Знаний и отвечает детерминированным ответом из Базы Знаний)
8. Генерация уникального текста в соответствии с загруженной Базой Знаний формата "Вопрос-Ответ" (применимо для автоматической поддержки пользователей при наличии Базы Знаний и существенной вариативности запросов)
9. Выделение смысловых сущностей (применимо для приема заказов. Например, "мне пожалуйста обычную вашу воду две большие бутылки завтра после обеда если можно спасибо". Сеть определит смысловые сущности и зафиксирует заказ в CRM.
10. Определение "близости" текстов (применимо для анализа соответствий диалогов менеджеров по продажам утвержденному сценарию)
Общее, прочее, разное
1. Голосовые помощники типа "Алиса" и "Сбер". Могут общаться голосом. Распознавание и синтез речи уже приемлемого качества. В ряде случаев нахождение в Каталоге Сбер может рассматриваться как канал привлечения новых пользователей.
2. Рекомендательные системы для торговли. Очень отдельный пункт.
3. Распознавание и синтез речи
4. Генерация изображения по тексту
5. Генерация виде по тексту
6. Классификация набора данных (перспективный кандидат / не перспективный, перспективный инвестпроект / не перспективный, выдавать кредит / не выдавать)
7. Поиск закономерностей (определение закономерностей "успешных" и "неуспешных" наборов, последующая классификация поступающих данных.
--- --- ---
Оставьте комментарий
С каждым пунктом связана обширная информация.
Сообщите, какие из пунктов вызывают особый интерес для более подробного раскрытия.
--- --- ---