Когда речь заходит об архитектуре ЭВМ, то чаще всего вспоминают Гарвардскую архитектуру и архитектуру фон Неймана. Но понятие архитектуры ЭВМ гораздо шире, чем деление способу организации памяти, которую использует процессор. ЭВМ состоит из множества узлов, каждый из которых может иметь собственную архитектуру. Более того, соединение этих узлов в единое целое, что мы и называем собственно машиной (ЭВМ), тоже может выполняться разными способами. Поэтому нужного говорить и об архитектуре интерфейсов (шин).
Сегодня мы будем рассматривать архитектуру одного из важнейших компонентов любой ЭВМ - процессора. Причем не обязательно центрального процессора. Нас не будет интересовать архитектура памяти, поэтому нет никакой разницы между Гарвардской архитектурой и архитектурой фон Неймана. Нас не будет интересовать архитектура шин и ввода-вывода. Но нас не будет интересовать и архитектура многих узлов процессора, например, архитектура АЛУ.
Архитектура
Термин "архитектура" исторически относился к области строительства. Архитектор был, в некотором роде, "дирижером ансамбля" специалистов, которые возводили здания, создавали сады и парки. Каменотесы умели обрабатывать каменные глыбы и изготавливать блоки, из которых каменщики складывали стены. Инженеры и землекопы умели сооружать подвалы и фундаменты. Садоводы умели высаживать цветы и деревья. Но что бы все эти специалисты смогли создать шедевр было нужно их организовать.
Архитектор определял, создавал, общий вид здания и прилегающих территорий. Определял, как все это будет создаваться в реальности из различных фрагментов и готовых блоков. Какие специалисты, и в какой срок, будут привлекаться для работы. Сколько специалистов потребуется. Организовывал выполнение работ. Каменщики возводили стены, но где эти стены стояли, как выглядели, какой высоты, определял архитектор. Он действительно, как дирижер из разрозненных музыкантов создает оркестр, создавал из отдельных фрагментов потрясающий дворец или храм. Впрочем, почему создавал? Архитекторы прекрасно работают и сегодня.
Но понятие "архитектура" сегодня используется гораздо шире, далеко не только к строительству. Так сегодня является устоявшимся и термин "архитектура ЭВМ". Так что же такое архитектура? В первоначальном значении, которое появилось еще во времена античности, это зодчество. В более широком смысле, как мы его понимаем сегодня, это наука (и искусство!) о проектировании и построении объектов. Причем не только в строительстве.
Упрощенно можно сказать, что архитектура это некий свод правил, подходов, принципов, решений, которые используются при проектировании и построении (изготовлении) различных объектов.
Архитектура процессоров
ЭВМ это ведь тоже объект, который можно (и нужно!) проектировать и изготавливать (строить). И процессор, как один важнейших компонентов ЭВМ, тоже является самостоятельным объектом. Причем один и тот же процессор может использоваться в различных ЭВМ с совсем иной архитектурой других узлов. Процессоры могут быть очень разными и их тоже нужно проектировать.
Центральный процессор является основным узлом ЭВМ. Цифровых. А основным узлом процессора является АЛУ - Арифметико-Логическое Устройство. Именно АЛУ выполняет все операции. О том, как устроены АЛУ я кратко рассказывал в статьях
Но для построения процессора одного АЛУ недостаточно. Нужно еще обеспечить подачу на входы АЛУ операндов, причем как из внешней, по отношению к процессору, памяти, так и из внутренних узлов, например, регистров. Нужно обеспечить сохранение результата работы АЛУ во внешней памяти или внутренних узлах процессора. Для работы с памятью нужны узлы обеспечивающие вычисление адресов и выполнение процедур доступа к ячейкам. Для определения выполняемой АЛУ операции нужны декодер машинных команд и узлы их выборки, причем возможно с блоками предсказания переходов. Нужны узлы синхронизации работы всех узлов и блоков процессора, даже если используется внешний генератор тактового сигнала.
Другими словами, процессор, который строится вокруг АЛУ, является весьма сложным устройством. Очень кратко о построении процессоров я рассказывал в цикле статей "Микроконтроллеры для начинающих"
Но процессоры бывают не только центральными. В ЭВМ может использоваться несколько процессоров, часть из них будет выполнять вспомогательные функции и их правильнее называть периферийными процессорами. Таковым был и сопроцессор (более правильное произношение копроцессор, но с традицией не поспоришь) плавающей запятой в IBM/PC на процессорах 8086/8088/80186/80286. Периферийный процессор может управлять и, например, вводом-выводом. Такие процессоры мы привыкли называть контроллерами в ПК.
Точно так же и АЛУ в процессоре может быть несколько. Например, центральное АЛУ выполняет все операции, а периферийное (вспомогательное) занимается вычислением адресов операндов на основе используемых в машинной команде режимов адресации. Или вычислением физических адресов памяти в машинах с трансляцией адресов и управлением виртуальной памятью. Кратко об организации памяти я тоже уже рассказывал
Как именно все эти узлы будут объединяться в единое целое, как именно процессор будет выполнять различные машинные команды, как процессор будет работать в внешней памятью, и определяет архитектор процессора. Архитектор процессора это часть команды разработчиков. Именно он определяет концепцию построения процессора, которую команда разработчиков и будет использовать при проектировании всех узлов процессора и процессора в целом.
Мы сегодня будем рассматривать лишь малую часть общей архитектуры процессора, оставив далеко за кадром и вопросы синхронизации, и вопросы работы с памятью. Мы рассмотрим лишь общий подход к организации выполнения машинных команд внутри процессора. Ту часть, которая находится вокруг АЛУ. По большому счету, именно это и является определяющей концепцией процессора в целом.
Стек
Говоря о стеке, в бытовом понимании этого слова, чаще всего подразумевают "палку или короткую трость". Действительно, стек используют жокеи. Стек, короткую трость, использовали франтоватые представители дворянства в былые времена, причем в большей степени как модный атрибут. Но более правильно переводить слово stack как стопка или пачка. И монетница, которую часто используют для демонстрации принципа работы стека в ЭВМ, тоже является стопкой (монет).
Принцип работы стека (дисциплина) часто описывается сокращением LIFO - last in first out. Или "последний пришедший уходит первым", по русски. Логичность такого принципа описания работы стека очень наглядно показывает именно представления стека как стопки или штабеля.
Предположим, мы взяли книгу и положили ее на стол. Сверху положили, последовательно, еще несколько книг. Получилась стопка. Мы можем легко взять книгу, которую положили последней. Она лежит на самом верху стопки. Но мы не можем взять из стопки другие книги, пока не снимем лежащие сверху. То есть, мы складываем книги в стопку по порядку 1-2-3-4-5, но взять книги из стопки мы можем только в обратном порядке 5-4-3-2-1. Последнюю положенную книгу мы берем первой. А первая положенная, которая лежит в основании стопки, можем взять только последней.
Такой принцип работы является основополагающим для стека. И в этом главное отличие стека от очереди, принцип работы которой часто описывают сокращением FIFO - "пришедший первым уходит первым". Очереди видели все, например, в магазине, поэтому пояснения вряд ли требуются.
При работе со стеком (стопкой) использую две основные операции:
- PUSH - протолкнуть в стек, положить на вершину стека. Эта операция размещает новый объект в стеке. Расположенный на вершине объект при этом смещается вниз, а новый объект становится вершиной стека (располагается на вершине стека).
- POP - вытолкнуть из стека, снять с вершины стека. Эта операция извлекает объект из стека. При этом объект действительно удаляется из стека, а лежавший под ним (уровнем ниже) объект становится новой вершиной.
Это можно проиллюстрировать на примере той самой монетницы
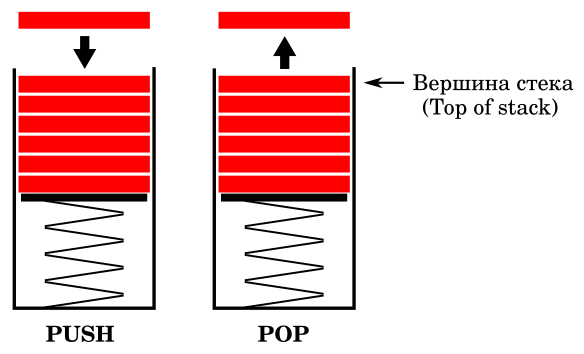
Помещая новый объект, например, монету, в стек мы действительно ее заталкиваем/проталкиваем преодолевая сопротивление пружины. А при извлечении объекта (монеты) пружина его выталкивает. Так появились названия этих операций.
Может ли при использовании стека что-либо "пойти не так"? Конечно может. Давайте исключим механические поломки. Остается две основные проблемы:
- Стек уже заполнен и новый объект разместить невозможно. Такую ситуацию называют переполнением стека (stack overflow).
- Стек пуст и извлечь объект невозможно. Такую ситуацию называют опустошением стека (stack underflow). Иногда используют неудачный, на мой взгляд, термин антипереполнение.
Эти ситуации называют исключительными ситуациями или просто исключениями. Их возникновение свидетельствует о возникновении ошибки в работе процессора или исполняемой им программы. Мы сегодня не будем учитывать возникновение исключительных ситуаций, но не упомянуть о них было нельзя.
С точки зрения ЭВМ (и процессора) стек это просто область памяти с определенной организацией. Разумеется, в отличии от рассмотренной ранее монетницы (механического стека) никакого перемещения размещенных в стеке объектов не происходит. Это потребовало бы слишком много лишнего времени и скорость работы со стеком была бы катастрофически низкой. Вместо этого используется специальный регистр указателя стека. Тот самый SP (stack pointer).
С точки зрения процессора, да и ЭВМ в целом, стек полностью описывается начальным адресом и количеством выделенных для него ячеек памяти (размером стека). И здесь возникает два любопытных вопроса - какой адрес будем считать началом стека и в какую сторону будем размещать новые элементы?
Ответ на первый вопрос довольно прост и очевиден. Поскольку новые элементы размещаются на вершине стека, а у нас SP указывает именно на расположенный на вершине элемент, значит вершина стека (ее адрес) постоянно изменяется при работе процессора (или программы). А вот "дно" стека остается неизменным. Значит адресом начала стека (области памяти выделенной под стек) будет именно "дно" стека, именно от него будет отсчитываться количество выделенных под стек ячеек памяти. Обратите внимание, что размер стека это максимальное количество объектов, которые можно в него поместить.
Ответ на второй вопрос не столь очевиден. Действительно, есть ли разница, в какую сторону будет двигаться SP при размещении новых объектов (и при удалении существующих)? С точки зрения обычной логики (и здравого смысла) никакой разницы нет. А значит, два эти подхода эквиваленты
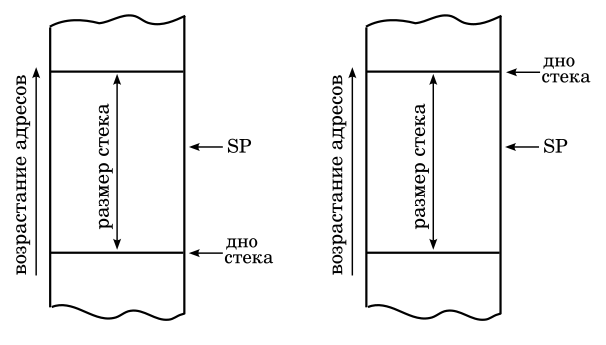
В левой части иллюстрации показан стек, который "растет" в сторону увеличения адресов памяти. Термин "растет" использован не случайно. Мы уже выяснили, что "дно" стека является неизменным, а вот вершина (указатель на вершину) стека перемещается при размещении новых объектов. Если новый объект размещается в стеке по адресу большему, чем предыдущая вершина стека, то и получается, что стек "растет" в сторону увеличения адресов памяти.
В правой части иллюстрации показан стек, который "растет" в сторону уменьшения адресов памяти. Не сомневаюсь, что большинство читателей скажут, что именно так и работает стек в современных ЭВМ. Это совершенно необязательно, но такой способ размещения стека действительно наиболее распространен сегодня. Если говорить об аппаратно поддерживаемых процессорами стеках, конечно. Программная организация стека может быть любой, причем чаще всего используется как раз размещение в сторону увеличения адресов.
Но чем же различается работа с этими двумя типами размещения стеков? Что бы ответить на этот вопрос нужно вспомнить, что SP всегда указывает на объект лежащий на вершине стека. Если мы просто запишем в ячейку, на которую указывает SP, новый объект, то размещенный ранее на вершине объект будет уничтожен. Поэтому операция PUSH всегда начинается с изменения SP. И лишь после изменения SP новый объект будет записан в указываемую им ячейку памяти.
Если стек "растет" в направлении увеличения адресов памяти, что изменение SP будет сводиться к увеличению хранящегося в нем значения. Ведь "SP указывает на лежащий на вершине стека объект" как раз и означает, что регистр SP хранит адрес ячейки памяти, которая в данный момент рассматривается как вершина стека. Если же стек "растет" в направлении уменьшения адресов, то изменение SP будет сводиться к уменьшению хранящегося в нем значения.
Вот и вся разница между способами размещения стеков! Так почему же размещение стека в сторону уменьшения адресов стало гораздо более популярным для аппаратно поддерживаемых стеков? Все очень просто - дело в программистах и способах управления памятью первых ОС.
Причем тут программисты? Дело, собственно говоря, в концепции, которая использовалась во многих языках программирования высокого уровня. Управление временем жизни переменных и областями их видимости опиралось именно на реализацию в виде стека. Как и организация вызовов процедур с передачей параметров. Я описывал это в статье
Кроме этого, программистам требовалось динамическое выделение и освобождение областей памяти при работе программы, динамическое распределение памяти.
В первых ОС, еще однозадачных, программа пользователя (программиста) загружалась в память начиная с определенного, фиксированного, адреса памяти. Сразу за областями памяти собственно ОС. При этом размер программы зачастую был меньше доступного для программ объема памяти. Таким образом, после области памяти загруженной программы, оставалась свободная область памяти, которая и использовалась и для динамически распределяемой памяти, и для размещения стека. Что бы избежать пересечения динамической памяти и стека, насколько это возможно, свободная область памяти организовывалась таким образом
Область динамической памяти и область стека просто располагались с двух разных сторон оставшейся свободной области памяти. Скорее всего, дело случая, что стек стали размещать начиная со старших адресов памяти (рост в направлении уменьшения адресов). И это стало стандартом "де-факто". Такое размещение стека и динамической памяти позволяло избежать жесткого указания их размеров. Исключительная ситуация возникала лишь при пересечении этих областей. И это было удобно, так как при разработке программы далеко не всегда можно предсказать требуемый ей размер стека и динамической памяти (на то она и динамическая).
Для нас сегодня совершенно непринципиально, в какую именно сторону растет стек. В иллюстрациях я буду показывать, что стек растет "снизу вверх", просто так удобнее.
Кстати, размещение стека в направлении уменьшения адресов дает нам дополнительное, хоть и необязательное, удобство. Ранее размещенные в стеке объекты имеют положительные смещения относительно SP. Или положительные индексы массива, если рассматривать стек реализованный как массив. В статье на моем сайте, ссылку на которую я давал ранее, это хорошо видно.
Процессор стековой архитектуры
"Процессор стековой архитектуры" означает вовсе не то, что процессор поддерживает стек на аппаратном уровне. Это означает организацию выполнения операций на базе внутреннего стека процессора. И мы сейчас это увидим. Такая архитектура менее распространена, чем регистровая или аккумуляторная, но используется и сегодня.
Давайте представим, что процессор не имеет внутренних регистров для обработки данных. Нет даже регистра-аккумулятора. Все имеющиеся регистры предназначены исключительно для выполнения служебных функций, причем они могут быть и недоступными для программиста. При этом процессор имеет и внутреннюю, небольшую, область памяти, но даже она недоступна для программиста напрямую. Тяжелый случай и бесполезный процессор, который спроектировал "недалекий архитектор"? Если Вы действительно так считаете, то очень сильно заблуждаетесь!
Если внутренняя память процессора организована в виде аппаратного стека, то перед нами процессор стековой архитектуры. И абсолютно ничто не мешает ему быть просто превосходным.
Для работы со стеком используется регистр SP, но он совершенно не обязательно должен быть доступен для программиста. И сам стек совершенно не обязательно должен быть доступен. При этом процессор будет полностью функциональным. Не верите? Тогда давайте посмотрим, как он может работать.
Доступ процессора к внешней памяти
Как и любой другой процессор, процессор стековой архитектуры должен уметь получать данные для обработки из внешней, по отношению к процессору, памяти. Внешняя, по отношению к процессору, память может быть внутренней памятью ЭВМ. Причем нам не важно, ОЗУ это, или ПЗУ. Точно так же, процессор должен уметь передавать во внешнюю память результат своей работы.
Процессоры регистровой архитектуры могут использовать поля операндов в машинных командах для прямого или косвенного указания адресов ячеек внешней памяти. Процессоры аккумуляторной архитектуры для доступа к внешней памяти используют машинные команды LDA (load - загрузка) и STA (store - сохранение), или их аналоги. А что на счет стековых процессоров? Нам требует всего две команды, которые будут аналогичны командам LDA и STA. Причем обе команды нам уже известны.
- PUSH [addr] - команда загрузки содержимого указанной ячейки на вершину стека процессора. Режим адресации ячейки может быть как прямым, так и косвенным. Загруженный в стек операнд становится новой вершиной стека (содержимое SP корректируется).
- POP [addr] - команда сохранения данных с вершины стека в указанной ячейке памяти. Режим адресации ячейки может быть как прямым, так и косвенным. Извлекаемые из стека данные удаляются, не физически, а путем корректировки SP. Новой вершиной стека становится его ячейка, расположенная ниже (выше) старой вершины.
Эти две команды единственные, которые могут адресовать внешнюю, для процессора, память. Причем мы не можем как-либо указать адрес или номер ячейки в стеке, с которым эти команды работают, мы указываем только адрес внешней памяти. Причем это совершенно не является для нас ограничением.
Однако, нам нужна еще одна команда, которая позволит помещать на вершину стека константы, которые обычно называют литералами. Можно рассматривать их как числа, которые уже известны во время разработки программы. Поэтому добавим команду
- PUSH [literal] - команда помещения на вершину стека указанного в ней числового значения. За исключением того, что операнд команды является числом, а не адресом ячейки внешней памяти, она идентична рассмотренной ранее команде PUSH [addr].
Команды логических и арифметических операций
Самое интересно, что для этих команд нам вообще не нужно указывать адреса операндов! Просто команды могут работать с данными расположенными на вершине стека и уровнями ниже, а результат помещать на вершину. Почему я не указал конкретное количество ячеек стека, с которым работает команда? Просто количество операндов команды может быть разным.
Давайте начнем с двух простых команд:
- NOT - логическая, команда отрицания.
- NEG - арифметическая, команда смены знача числа.
Этим командам нужен лишь один операнд. И этот операнд будет располагаться на вершине стека.
В дальнейшем я буду вместо мнемоники конкретной команды на иллюстрациях использовать мнемонику OP, что означает просто "операция", без уточнения.
Схематически можно показать работу этих команд так
Точками показано содержимое ячеек, которое нам в данный момент не важно. Value это исходное содержимое ячейки на вершине стека, именно на нее указывает SP. Result это результат операции. То есть, наши две одно-операндные команды просто заменяют содержимое ячейки на вершине стека на результат своей работы.
Обратите внимание, что я показал вершину стека не в верхней строке, а "где-то посередине". Вспомните, что данные у нас в стеке не перемещаются и их фактические адреса нам и не известны, и безразличны. Мы оперируем лишь понятием "вершина стека", что указывается с помощью SP. Но даже это лишь "возможно", так как конкретная реализация аппаратного внутреннего стека может быть разной.
С командами требующими двух операндов все тоже очень просто. Операндами будут являться две самые верхние ячейки стека, вершина и ячейка прямо под ней. Оба операнда будут удалены из стека, а вместо них на вершину стека будет загружен результат операции. Это можно схематически показать так
Обратите внимание, что после выполнения команды в стеке оказывается меньше данных, так как исходные операнды занимают две ячейки, а результат только одну.
Для некоторых двух-операндных команд небезразлично, в каком порядке хранящиеся в стеке операнды используются при выполнении операции. Для устранения неоднозначности в документации на стековый процессор обычно уточняется, например, так
(SP+1) OP (SP) -> SP
Поскольку нам неважно, в какую именно сторону растет внутренний аппаратный стек процессора, SP+1 просто означает следующую занятую после вершины стека ячейку.
Какие двух-операндные команды могут быть? Вот далеко не полный список наиболее популярных:
- ADD - сложение
- SUB - вычитание
- MUL - умножение
- DIV - деление
- AND - логическое И
- OR - логическое ИЛИ
- XOR - логическое исключающее ИЛИ
Возникает один, не самый очевидный вопрос - что делать, если размещенные в стеке операнды располагаются не в том порядке, который нам нужен при выполнении команды. Если программист сам загружает в стек данные из памяти, то нужно просто изменить порядок загрузки, это проблема (и скорее всего ошибка) программиста. А если неверный порядок возникает при выполнении последовательности команд? Значит на нужна еще одна команда, немного специфичная
- XCHG - обмен содержимого двух верхних ячеек стека.
Могут ли быть команды требующие большего количества операндов? Конечно могут, это встречается редко. Например, в специализированном процессоре может быть команда, выполняющая перенос декартовой системы координат с одновременным поворотом. Такой команду нужно три операнда: смещение по оси x, смещение по оси y, угол поворота.
Переходы и вызовы
Очень сложно представить процессор без команд перехода, вызова подпрограмм и возврата из них, обработки прерываний. Такое возможно, например, в потоковых процессорах, но это для большинства читателей является экзотикой. В стековых процессорах не возникает никаких проблем с командами переходов и вызовов/возвратов. Включая условные. Причем стековый процессор при этом работает точно так же, как процессор любой другой архитектуры.
С командами переходов, включая условные, нет никаких проблем. С командами вызовов/возвратов все немного сложнее. Далеко не самой очевидной особенность выполнения команд вызовов/возвратов является необходимость использования отдельного стека для хранения адресов возврата. Причем этот стек возвратов не обязательно должен располагаться внутри процессора, он вполне может располагаться во внешней памяти.
Почему для хранения адресов возвратов нельзя использовать внутренний стек? Причина проста - этот стек используется только для работы с данными и помещение в него адресов возвратов будет нарушать его работу. Давайте рассмотрим простой пример. Пусть нам нужно вызвать подпрограмму, которая требует три аргумента. Пусть адрес возврата при вызове процедуру помещается во внутренний стек. Получив управление подпрограмма начинает выполнять вычисления с данными в стеке точно так, как мы ранее рассматривали. Но при этом возникает проблема, так как на вершине стека располагается адрес возврата, который нужно не просто пропустить, но и как то использовать при возврате, а ведь SP после вычислений может указывать на совсем другую ячейку стека.
Любая попытка решить эту проблему приводит к необходимости использовать дополнительную область памяти, причем организованную как стек, так как вложенность вызовов подпрограмм может быть разной в разные моменты времени.
Итак, архитектура фон Неймана использует единую память и для программ, и для данных. Гарвардская архитектура использует разную память для программ и данных. Обе эти архитектуры могут использоваться в процессорах с регистровой, аккумуляторной, стековой, архитектурами. При этом процессоры регистровой и аккумуляторной архитектур используют один стек и для данных, и для адресов возвратов. Процессоры стековой архитектуры используют раздельные стеки для адресов возвратов и данных.
Универсальность стековых процессоров
Давайте подведем небольшой промежуточный итог. Стековые процессоры оказались вполне удобными и универсальными, ничуть не уступающими процессорам куда более распространенной аккумуляторной архитектуры. Причем они могут еще и уменьшить количество обращений к внешней памяти, что положительно сказывается на быстродействии.
Для уменьшения количества обращений во внешнюю память, которая обычно медленнее внутренней для процессора, нам нужно лишь увеличить размер внутреннего стека данных. Он не должен быть слишком большим, вполне достаточным может быть, например, 32 ячейки. При этом в коде машинной команды не нужно указывать информацию об используемых регистрах, ведь всегда используются ячейки на вершине стека. А значит, код команды может быть короче. Но это еще не все. Ячейки внутреннего стека автоматически используются для хранения промежуточных результатов в длинных цепочках вычислений. Мы скоро увидим, как это достигается.
Обратная польская запись и стековые процессоры
Для большинства обычных людей термин "обратная польская запись" не имеет смысла, во всяком случае, практического. Действительно, при записи математических формул мы обычно используем так называемую инфиксную форму записи. То есть, знаки операций размещаются между операндами. Во простейший пример:
(a + 2) / 3
Здесь a, 2, 3, это операнды. + и / это операции. Хорошо видно, что операции записаны между операндами, которые они используют. Увы, необходимость использования скобок для уточнения порядка выполнения операций (приоритета), как и связана с инфиксной записью.
Гораздо менее очевидно, что при записи математических формул мы используем и префиксную форму записи. Наиболее простым примером является запись отрицательных чисел, например, минус 2. Вот чуть более сложный комплексный пример
a + 2 - (-b)
Здесь у нас есть два знака минус. Первый, располагающийся сразу после числа 2, является инфиксной записью операции вычитания. Второй, расположенный в скобках перед переменной b), является префиксной записью операции смены знака числа. В качестве другого примера можно привести использование функций. Так sin(a) является префиксной записью операции вычисления синуса от переменной a.
Встречаются и постфиксные операции, например, факториал.
a!
является постфиксной запись операции вычисления факториала числа a. Кстати, операция возведения в степень является инфиксной записью, а не постфиксной. Она записывается, в классическом виде, как верхний индекс указанный после числа или переменной, который указывает степень. Собственно операция возведения в степень здесь записывается именно как переход к верхнему индексу, без использования отдельного символа операции.
Все это нисколько не влияет на то, что мы обычно используем инфиксную запись. В общем и целом. Обратная польская запись запись является чисто постфиксной. В ней операции указываются после операндов, которые они используют. Такая форма записи математических формул для большинства непривычна и кажется неудобной. Однако, она не требует использования скобок, что уже может оказаться полезным. Но нам важнее всего то, что она отлично подходит для стековых процессоров.
Давайте рассмотрим несколько простых примеров преобразования инфиксной записи в постфиксную, обратную польскую
a + b + c -> a b c + + или a b + c +
a + b * c - d -> a b c * + d -
a / (b + c) -> a b c + /
Давайте на этом остановимся и попробуем записать последнюю формулу как последовательность команд нашего стекового процессора, причем сразу будем смотреть, как это работает. Будем использовать постфиксную, обратную польскую, запись
Ну а теперь собственно программа и покомандные снимки состояния стека ее выполнения
Здесь все достаточно просто и вряд ли требует пояснений. Используется последовательность использования операндов, которую мы уже рассматривали ранее. Обратите внимание, что программа получилась простой, хоть и непривычной для неискушенного взгляда. При этом нам действительно не требовалось знать адреса ячеек в стеке и состояние SP. Обратите так же внимание, что промежуточные результаты вычислений (b+c) автоматически оказались размещенными в стеке, о чем я упоминал ранее.
Заключение
Стековые процессоры вовсе не так сложны, как иногда считается. Да, эта архитектура для многих непривычна, что не делает ее менее удобной и интересной. Она подходит и для вычислительных задач, и для работы с текстами. Многие задачи синтаксического анализа текстов, например, выполняемые компиляторами языков программирования высокого уровня, используют стек.
Стековые процессоры можно использовать примерно так же, как и процессоры регистровой или аккумуляторной архитектуры. При этом даже не требуется большой внутренний стек. Но гораздо эффективнее использовать ту же обратную польскую запись для составления ориентированных на стек цепочек вычислений. Это позволит уменьшить количество обращений к памяти и увеличить быстродействие.
Вы считаете, что стековые процессоры в реальной жизни не встретить? Вы ошибаетесь! Уже упомянутый ранее сопроцессор плавающей запятой (8087/80287/80387 и более свежие) как раз используют стековую архитектуру. Стековая архитектура использовалась и в программируемых калькуляторах советской эпохи Б3-21/Б3-34/МК-52/МК-54/МК-61, которыми активно пользовались и студенты, и инженеры. И настольная инженерная ЭВМ (по сути, большой калькулятор) 15ВСМ-5, о которой я уже рассказывал, была стековой
Сегодня я лишь слегка коснулся темы архитектуры ЭВМ, причем для начала выбрал не самую распространенную. И не стал приводить пример функциональной схемы стекового процессора, так как статья и так получилась довольно объемной. Насколько интересна читателям эта тема я пока не знаю. Можете высказывать свое мнение и предложения в комментариях. И, как всегда, можете задавать любые вопросы.