
Все чаще разработчики сталкиваются со множеством проблемных запросов, что приводит к существенному снижению общей производительности сервера и его пропускной способности. Для специалистов по базам данных настройка производительности является не самой приятной задачей, но ее игнорирование и пренебрежение сейчас обходится значительно дороже, чем раньше. Поэтому разработчики и администраторы занимаются этим регулярно.
В данной статье мы рассмотрим как оптимизировать базу данных PostgreSQL на примере Linux на IBM Z.
Можно отметить, что улучшений, касающихся настройки базы данных можно достичь путем внесения изменений на уровне SQL. Например, путём создания индексов или адаптации SQL-запросов. В данной статье мы не будем останавливаться на таких приемах, а поговорим о конфигурационных изменениях в базовой среде: операционной системе (Linux) и промежуточном программном обеспечении (PostgreSQL).
Чтобы увеличить пропускную способность необходимо:
- Увеличить размер shared buffers PostgreSQL до 1/4 от общего объёма физической памяти и размер effective cache до 3/4 (подробнее можно узнать здесь).
Здесь стоит отметить, что это один из самых явных регуляторов, который повышает пропускную способность почти на 12%. Очень важно не увеличивать размер shared buffers больше чем нужно, например до1/2, так как это спровоцирует активность OOM Killer.
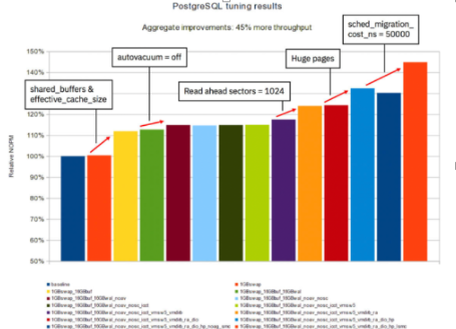
2. Отключить демона автоочистки (autovacuum daemon) для рабочих нагрузок, предназначенных только для чтения. В основном его рекомендуют оставлять включенным, ведь он выполняет полезные функции. Но стоит отметить, что отключение демона для рабочей нагрузки HammerDB TPC-C приведет к увеличению пропускной способности почти на 2%.
Для рабочих нагрузок с большим объёмом записи (с большим количеством операторов INSERT, UPDATE и DELETE), рекомендуется держать демона автоочистки включенным.
3. Включите read ahead для logical volume, содержащего файлы базы данных.
На данный момент существовала четкая рекомендация для баз данных, а именно отключать read ahead на уровне LV или блочного устройства. Например, DB2 работает лучше, если read ahead отключено на уровне LV/блочного устройства.
Включение этого параметра приведет к увеличению пропускной способности примерно на 6%. Скорее всего, причиной является зависимость PostgreSQL от эффективности кэша страниц Linux. Стоит отметить, что остальные базы данных самостоятельно решают, какие страницы следует читать заранее, и не полагаются на функциональность read ahead операционной системы.
4. Включите huge pages.
В этом контексте huge pages означают страницы, которые настраиваются с помощью параметра в /etc/sysctl.conf: vm.nr_hugepages=17408 (17 ГБ). Включение huge pages может привести к увеличению пропускной способности примерно на 7%.
В данном случае именно 17 Гб, так как shared buffers потребляют 16 ГБ и PostgreSQL нужна память, необходимая для иных целей и дополнительный «запас» по соображениям безопасности. Если необходимо точно определить, сколько памяти использует PostgreSQL, следует посмотреть файл /proc/[PID]/task/[TID]/status и найти запись «VmPeak».
5. Снизить стоимость миграции планировщика ядра для меньшего числа IFL и большого количества параллельных пользователей
kernel.sched_migration_cost_ns= устанавливает количество наносекунд — столько ядро будет ждать, прежде чем рассмотреть вопрос о переносе потока на другой CPU. Чем выше стоимость миграции, тем дольше планировщик будет ждать, прежде чем рассмотреть вопрос о переносе потока на другой CPU. Это актуально для больших Linux images и/или разбросанных Linux images, охватывающих несколько микросхем PU и/или несколько узлов.
Здесь важно помнить, что все ядра на чипе PU используют один и тот же кэш L3 (и, конечно же, кэш L4). PostgreSQL создает новый процесс для каждого виртуального пользователя.
Снижение стоимости миграции планировщика увеличивает пропускную способность почти на 9%.
Необходимо добавить в /etc/sysctl.conf следующее:
kernel.sched_migration_cost_ns=50000`
В конкретной конфигурации для производительности невыгодно позволять отдельным процессам PostgreSQL работать как можно дольше на одном и том же CPU. Даже если они распределены по другому ядру, они все ещё находятся на одном и том же чипе PU. Это значит, что, либо кэш L3 содержит много важной информации для процесса, либо кэш L3 полностью заполнен.
Если количество пользовательского времени увеличивается, это явный признак того, что Linux image выполняет более полезную работу с применением этого параметра. Это проверяется с помощью top и/или sar.
Здесь очень важно не применять параметр без тестирования для больших Linux images и/или Linux images, процессоры которых разбросаны по всей топологии z13 или средам, в которых у вас мало параллельных пользователей. Вы можете проверить текущую топологию с помощью lscpu --extended. В этом контексте небольшое количество пользователей означает #users = #cores.
От скорости работы баз данных зависит быстрота отклика сайта. Ведь замедленная обработка запросов влияет на PHP, следовательно — накапливается огромное количество операций, с которыми сервер может не справиться.
Ниже на графике мы показываем сравнение производительности СУБД SoQoL с другими аналогами. СУБД SoQoL - это высокопроизводительная масштабируемая реляционная СУБД нового поколения (разрабатывается компанией РЕЛЭКС).
Данные основаны на сравнительном тестировании по методике TPC-C от HammerDB, которое показывает кратное увеличение скорости обработки данных в СУБД SoQoL перед СУБД Oracle, MS SQL Server и PostgreSQL.
Вы можете получить бета-версию СУБД SoQoL для тестирования и пилотирования в вашей организации.
В данной статье мы опирались на примеры работы в Linux на IBM Z. Применяя выше перечисленные рекомендации, вы можете значительно повысить производительность базы данных PostgreSQL в своей работе.