Diesel
Diesel - это безопасный, расширяемый ORM и построитель запросов для Rust.
Diesel является наиболее продуктивным способом взаимодействия с базами данных в Rust из-за его безопасных и компонуемых абстракций над запросами.
Для этого руководства мы рассмотрим несколько простых примеров для каждого из разделов CRUD, который означает «Create Read Update Delete». Каждый шаг в этом руководстве будет основан на предыдущем и должен следовать вперед.
Необходимые условия
- PostgreSQL
Убедитесь, что PostgreSQL установлен и запущен.
- Rust версия
Diesel требует Rust 1.31 или выше. Если вы следуете вместе с этим руководством, убедитесь, что вы используете по крайней мере
эту версию Rust, запустив `rustup update stable`.
Применение
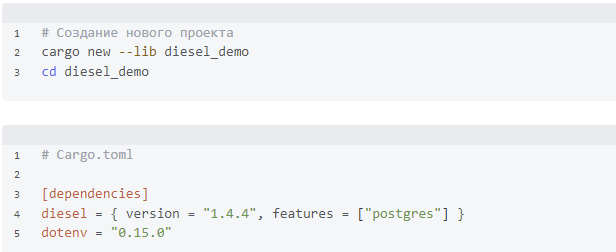
Инициализация нового проекта
Первое, что нам нужно сделать, это создать наш проект.
Установка интерфейса командной строки Diesel
Diesel предоставляет отдельный CLI-инструмент для управления проектом. Поскольку это автономный двоичный файл и не влияет непосредственно на код проекта, мы не добавляем его в файл Cargo.toml. Вместо этого мы просто устанавливаем его в нашу систему.
Создание базы данных
Нам нужно создать базу данных с именем пользователя и паролем.
Настройка Diesel для проекта
Мы должны сказать Diesel, где найти нашу базу данных. Для этого необходимо задать переменную среды DATABASE_URL. На наших машинах для разработки, скорее всего, будет реализовано несколько проектов, и мы не хотим загрязнять окружающую среду. Вместо этого можно поместить URL-адрес в файл `.env`.
Теперь Diesel CLI может настроить все для нас.
Это приведет к созданию нашей базы данных (если она еще не существовала) и созданию пустого каталога миграции, который можно использовать для управления нашей схемой (подробнее об этом позже).
Первое, что нам понадобится, это таблица для хранения наших сообщений. Давайте создадим миграцию.
Diesel CLI создаст для нас два пустых файла в требуемой структуре. Вы увидите выходные сообщения, которые выглядят примерно так:
Миграции позволяют с течением времени развивать схему базы данных. Каждая миграция может быть применена (up.sql) или возвращена (down.sql). Применение и немедленный возврат миграции должны оставить схему базы данных без изменений.
Далее мы напишем SQL для миграции:
up.sql
down.sql
Мы можем применить нашу новую миграцию:
Рекомендуется убедиться, что файл down.sql верен. Вы можете быстро подтвердить, что ваш down.sql откатывает вашу миграцию правильно, повторив миграцию:
Примечание по Raw SQL в миграциях:
Поскольку миграции записываются в raw SQL, они могут содержать определенные функции используемой системы базы данных. Например, приведенная выше инструкция `CREATE TABLE` использует тип PostgreSQL `SERIAL`. Если вместо этого необходимо использовать SQLite, вместо него необходимо использовать `INTEGER`.
Примечание по использованию миграции на лету:
Пакет diesel_migrations 1.4.0 - Docs.rs - https://docs.rs/crate/diesel_migrations/1.4.0 обеспечивает `embed_migrations!` , позволяя встраивать сценарии миграции в окончательный двоичный файл. После использования кода можно просто включить e`mbedded_migrations::run(&db_conn)` в начале основной функции для запуска миграции при каждом запуске приложения.
Пишем в rust
Начнем с написания кода, чтобы показать последние пять опубликованных идей. Первое, что нам нужно сделать, это установить подключение к базе данных.
Далее нам нужно создать два модуля, которые мы только что объявили.
`[derive (Queryable)]` создаст весь код, необходимый для загрузки структуры Post из SQL запроса.
Обычно модуль схемы создается не вручную, а Diesel. Когда мы запустили установку diesel setup, был создан файл `diesel.toml`, который говорит Diesel поддерживать файл на `src/schema.rs` для нас. Файл должен выглядеть следующим образом:
Точные выходные данные могут несколько отличаться в зависимости от базы данных, но должны быть эквивалентными.
`table!` создает пакет кода на основе схемы базы данных для представления всех таблиц и столбцов. Мы посмотрим, как именно использовать это в следующем примере.
При каждом запуске или возврате миграции этот файл будет автоматически обновлен.
Примечание по полю упорядочивания
Использование `#[derive(Queryable)]` предполагает, что порядок полей в структуре публикаций соответствует столбцам в таблице публикаций, поэтому необходимо определить их в порядке, указанном в файле schema.rs.
Показать публикации
Давайте напишем код, чтобы показать нам наши публикации.
При использовании `diesel_demo::schema::posts::dsl::*` строка импортирует набор псевдонимов, чтобы было вместо `posts::table` и опубликованных вместо `posts::published`. Это полезно, когда мы имеем дело только с одной таблицей, но это не всегда то, чего мы хотим.
Мы можем запустить наш сценарий `cargo run--bin show_posts`. К сожалению, результаты не будут ужасно интересными, так как у нас на самом деле нет никаких записей в базе данных. Тем не менее, мы написали приличное количество кода, так что давайте продолжим.
Полный код для демонстрации на данном этапе можно найти здесь v1.4.4· `diesel-rs/diesel` - https://github.com/diesel-rs/diesel/tree/v1.4.4/examples/postgres/getting_started_step_1/.
Создать публикацию
Затем напишем код, чтобы создать новую публикацию или поста. Нам нужна структура для вставки новой записи.
Теперь давайте добавим функцию для сохранения новой записи.
Когда мы вызываем `.get_result` в инструкции `insert` или `update`, она автоматически добавляет` RETURN *` в конец запроса и позволяет загрузить его в любую структуру, которая реализует `Queryable` для нужных типов.
Diesel может вставить несколько записей в один запрос. Просто передайте Vec или срез для вставки, а затем вызовите `get_results` вместо `get_result`. Если вы не хотите ничего делать с только что вставленной строкой, вызовите `execute`. Компилятор не будет жаловаться на вас, таким образом. :)
Теперь, когда все настроено, мы можем создать небольшой сценарий, чтобы записать новый пост.
Мы можем запустить наш новый сценарий `cargo run --bin write_post`. Вперед и написать пост для блога. Получите креатив! Вот мой:
К сожалению, запуск `show_posts` все еще не отобразит наш новый пост, потому что мы сохранили его как черновик. Если мы вернемся к коду в `show_posts`, мы добавили `.filter` `(published.eq (true))` и опубликовали значение по умолчанию `false` в нашей миграции. Мы должны опубликовать его! Но для этого нам нужно будет посмотреть, как обновить существующую запись. Сначала давайте сделаем. Код для этой демонстрации на данном этапе можно найти здесь.
Публикация поста
Теперь, когда мы создаем и читаем, обновление на самом деле относительно просто. Давайте перейдем прямо к сценарию:
Вот и все! Попробуем `cargo run --bin publish_post 1`.
Мы все еще покрыли только три из четырех задач CRUD. Давайте покажем, как удалять записи. Иногда мы пишем то, что на самом деле ненавидим, и у нас нет времени искать удостоверение личности. Поэтому давайте удалим, основываясь на названии, или даже просто некоторые слова в названии.
Мы можем запустить сценарий `cargo run --bin delete_post demo` (по крайней мере, с заголовок я выбрал). Ваш результат должен выглядеть примерно так:
Когда мы пытаемся запустить `cargo run --bin show_posts` снова, мы видим, что пост был фактически удален. Это едва царапает поверхность того, что вы можете сделать с Diesel, но, надеюсь, это учебное пособие дало вам хороший фундамент, чтобы строить. Для получения дополнительной информации рекомендуется изучить документы API. Окончательный код для этого учебного пособия можно найти здесь v1.4.4· diesel-rs/diesel - https://github.com/diesel-rs/diesel/tree/v1.4.4/examples/postgres/getting_started_step_3/.
FAQs
не удается найти таблицу макросов в этой области, невозможно найти производный макрос `Queryable` в этой области
Статья на list-site.