Данная статья продолжает цикл статей про матричное программирование: первая, вторая, третья и четвертая. Функция поиска локального максимума имеется в библиотеке sklearn, но это мы уже обсуждали в предыдущих статьях. Предполагаю, что большинство читателей уже забыли раздел математики про дифференциалы и интегралы, где было такое определение - локальный максимум (экстремум), поэтому попробуем логическим способом прийти к этому определению.
Представим, что значения в ряду увеличиваются, и в какой-то момент рост прекращается, начинается снижение, которое можно определить по уменьшению значений по отношению к предыдущему. Точка перелома, в которой повышение сменилось на понижение и является локальным максимумом.
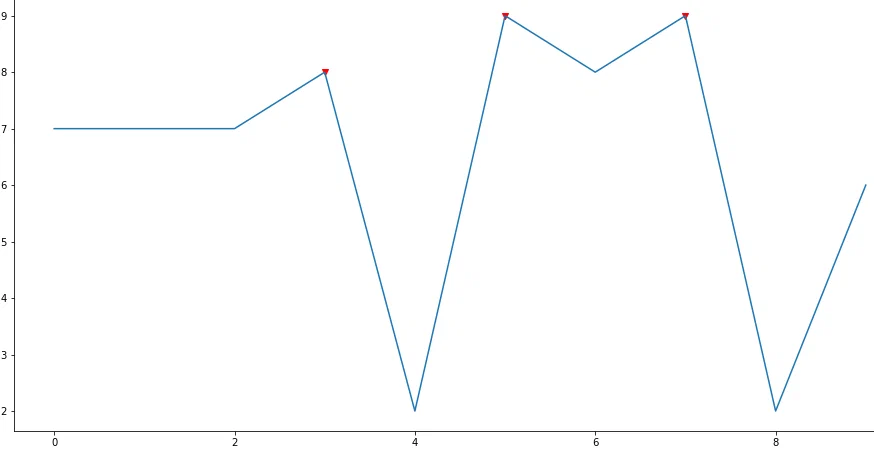
Продемонстрируем на примере следующего числового ряда: 7, 7, 7, 8, 2, 9, 8, 9, 2, 6. Локальными максимумами такого ряда будут четвертое, шестое и восьмое значение, так как индексация массивов в python начинается с 0, то индексы локальных максимумов будут: 3, 5, 7.
Функция локальных максимумов в классическом виде будет выглядеть так:

А теперь ту же функцию сделаем в стиле numpy-программирования:
Чтобы убрать условия мы получим вектор разности элементов исходного массива dif_v, но для сохранения размера исходного массива добавляем пустое значение вперед. Ведь у первого элемента разности не будет. Значение dif_v будет: [nan, 0., 0., 1., -6., 7., -1., 1., -7., 4.]. На самом деле нам не интересна разность, а именно знак этой разности. Если значение увеличивается, то знак будет положительный, если уменьшается - отрицательный, а при равенстве - 0. Значение sig_dif_v: [nan, 0., 0., 1., -1., 1., -1., 1., -1., 1.]. А уж если быть совсем точным, то нас интересуют участки, где рост 1 сменяется на падение -1, для этого возьмем разность вектора знаков. Для сохранения размера опять добавим пустое значение. Таким образом, dif_sig_dif_v станет: [nan, nan, 0., 1., -2., 2., -2., 2., -2., 2.]. В последнем массиве нам нужны значения -2, так как если перед падением -1 будет подъем 1, то разность будет выглядеть как -1 - 1.
Мы не случайно сохраняли размер вектора, ведь на по факту нужно получить индекс локального минимума, а не значение -2, поэтому размеры всех векторов должны быть одинаковы. К тому же значение -2 будет следующим значением, а нам нужно предыдущее, то есть его индекс будет меньше на единицу. Вишенкой на торте является вывод функции where, ведь нам нужно только первая часть вывода. Короткий вид этой же функции будет таким:
Согласитесь, что неподготовленному читателю, такая запись покажется непонятной, однако же она по содержанию идентична предыдущей. Для тренировки попробуйте "расшифровать" следующую функцию:
Если не получается понять с листа, то попробуйте разбить функцию на части, чтобы понять отдельно каждую часть.
Ждите следующих статей