Я тут выкладывал свои поделки в leonardo для магических предметов, потом выкладывал рассказы к которым делал иллюстрации все там же, в нейросети leonardo.ai.
Сейчас, хотелось бы сделать более глубокий (насколько я могу себе это позволить) экскурс в саму сеть.
Изначально, думал оформить всё в один пост. Но пока собирал все в кучу, то понял, что материала получается прям дофига. Одних только изображений вышло более чем 100шт!
Теперь думаю, что буду бить на небольшие блоки ~ 500 слов.
Часть 1. Интерфейс
Часть 2. Количество кадров и их размер
Часть 3. Размер изображения
Часть 4. Работа с реферансами. Обзор изменений от 18.03.2023
Часть 5. Твой первый Promt!
⚠В связи с обновлениями от 18.03.23г, смотри 4 часть!⚠
ИНТЕРФЕЙС
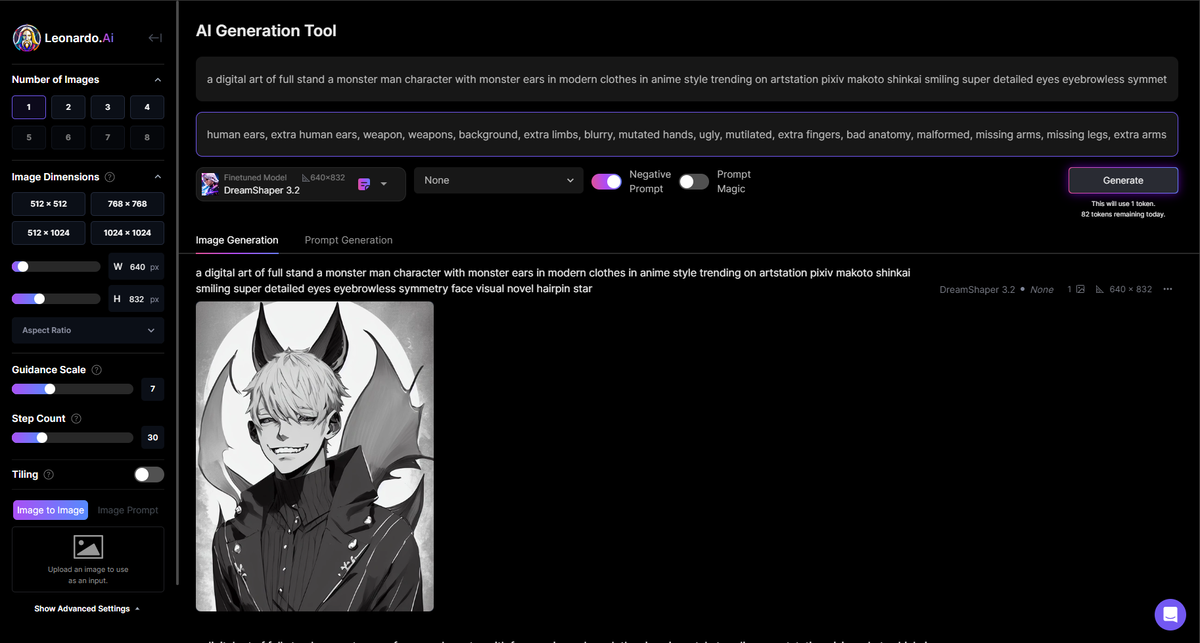

Интерфейс по сути своей не очень сложный, а главное интуитивно понятный для любого, кто владеет английским на уровне хотя бы школы. Ко всем ползункам, полям и кнопочкам есть всплывающие пояснения в которых объясняется суть той или иной фичи. А дальше уже, если прям ОЧЕНЬ интересует, добро пожаловать в интернет.
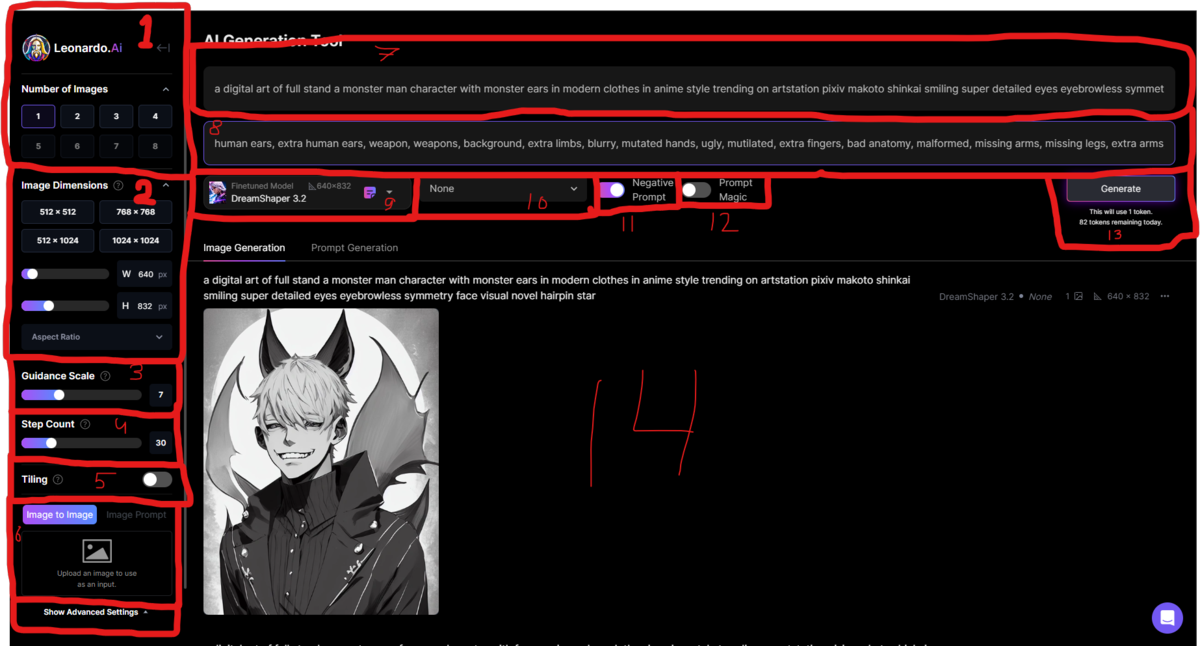
- Number of Images - кнопочки позволяют выбрать нам, сколько изображений за раз будет генерировать нейросеть.
!Чем больше количество изображений, тем больше токенов за раз! - Image Dimensions - размеры генерируемого изображения можно как выбрать из предложенных, так и с помощью ползунков выставить свои параметры.
Так же, можно выбрать то, в каком соотношении генерировать изображение.
!Так как нейросеть тренируется на изображениях ОПРЕДЕЛЕННОГО РАЗМЕРА, то выбрав размеры отличающиеся от модели (п.9) никто не гарантирует вам, что качество будет лучше (или хуже)! - Guidance Scale - то, насколько "дословно" будет нейросеть воспринимать ваш запрос. В данном случае, порядок слов играет большую роль.
Step Count -определяет количество "шагов", которое сделает нейросеть при отрисовке изображения. Проще говоря, чем выше значение, том четче изображение, но не всегда это идет в плюс.Теперь недоступно бесплатных пользователям- Tiling - позволяет генерировать задний фон или текстуру.
- Image to Image - позволяет использовать в качестве promt картинку. Это может быть изображение из интернета, нарисованное вами, фото или созданное нейросетью.
- Promt - строка для ввода тестового описания того, что мы хотим сгенерировать. Ввод только на английском, хотя в сети есть варианты Stable Diffusion на разных языках.
- Negative Prompt - строка для ввода текстового описания того, что мы НЕ ХОТИМ генерировать, например всякие рога и копыта, лишние руки и ноги. (включается кнопкой п.11)
- Finetuned model - здесь мы выбираем модель которая будет работать за нас. На выбор представлены основные модели и несколько тех, которые вы использовали.
- Styles - вкладка со стилями, которые можно применять к генерируемым изображениям. Пока доступно 2 варианта: Leonardo Style и None.
- Переключатель Negative Promt.
- Переключатель Magic Promt.
Применяет какие-то алгоритмы обработки текстового запроса, которые кардинально меняют выводимое изображение. Особенно это заметно при использовании в качестве promt изображения.Поменялся принцип работы, смотри 4 часть! - Кнопка Generate, под которой выводятся текущее кол-во токенов, время до их обновления и сколько из них будет потрачено на текущую генерацию.
- Поле вывода. Тут выводятся изображения, текстовые запросы и различные данные по запросу, такие как модель, стиль, размер и кол-во изображений.
- Так же есть отдельная вкладочка слева внизу, с дополнительными настройками, но об это потом.