В чем разница между командами Kubernetes kubectl drain и kubectl cordon? Что ж, чтобы кластер Kubernetes оставался работоспособным и бесперебойно работал, необходимо регулярно обслуживать отдельные узлы. Обслуживание может включать в себя обновление программного обеспечения, модернизацию оборудования или даже полную переустановку ОС. Но как подготовить узел к техническому обслуживанию, не нарушая работу приложений? Вот где на помощь приходят drain и cordon, давайте исследуем!
Обслуживание узлов Kubernetes: Drain vs. Cordon
kubectl drain и kubectl cordon — это две основные команды в наборе инструментов Kubernetes, которые используются для управления планированием и вытеснением модулей pod на узле, как правило, во время обслуживания или обновлений.
Kubectl Drain and Cordon в терминах непрофессионала
- Представьте, что вы ремонтируете дом. Вы хотите, чтобы все временно съехали, чтобы вы могли работать без помех. Итак, вы вежливо просите жильцов дома (pods) переехать в другой дом (узел) на некоторое время. Вы убедитесь, что они уезжают изящно и обустраиваются в своем новом доме (узлах) без каких-либо хлопот. Как только ремонт будет завершен, они могут плавно вернуться обратно, и ваш дом снова готов сиять! Это акт дренажа kubectl.
- Теперь, допустим, вам нужно исправить несколько вещей в вашей квартире (узле), но не все. Вы вешаете табличку с надписью «закрыто на ремонт», указывающую на то, что новые жильцы (капсулы) пока не могут заехать. Тем не менее, те, кто уже живет там (капсулы, работающие на узле), могут оставаться на месте и продолжать заниматься своими повседневными делами. Таким образом, вы можете управлять ремонтом, не причиняя никаких сбоев существующим жильцам. В этом заключается действие kubectl cordon.
Ныряя дальше, что именно делают kubectl drain и kubectl cordon?
kubectl cordon
Команда kubectl cordon помечает узел Kubernetes как недоступный для планирования. Это означает, что новые поды не могут быть запланированы на узле, который был оцеплен. Однако все существующие модули pod, размещенные на этом конкретном узле, не будут затронуты и продолжат работать в обычном режиме.
Kubectl Cordon используется, когда вы хотите подготовить узел к обслуживанию или обновлениям, не затрагивая работающие в данный момент поды.
В идеале, если вы планируете удалить поды, на которых работает узел, вы можете просто использовать команду drain.
Пример использования команды kubectl cordon
Прежде всего, если вы хотите настроить узел для обслуживания, вам необходимо определить этот конкретный узел. Вы можете использовать команду ниже, чтобы получить список узлов;
kubectl get nodes
Образец вывода;
NAME STATUS ROLES AGE VERSION
k8smas1.kalyuzhnyy.ru Ready control-plane 3h29m v1.31.5
k8smas2.kalyuzhnyy.ru Ready control-plane 3h21m v1.31.5
k8smas3.kalyuzhnyy.ru Ready control-plane 3h16m v1.31.5
k8swor1.kalyuzhnyy.ru Ready 174m v1.31.5
k8swor2.kalyuzhnyy.ru Ready 172m v1.31.5
k8swor3.kalyuzhnyy.ru Ready 172m v1.31.5
Как только вы узнаете конкретный узел, вы можете двигаться дальше и оцепить его.
kubectl cordon <node-name>
Например;
kubectl cordon master-01
Итак
- Узел master-01 помечается как недоступный.
- гарантирует, что на этом узле не будут запланированы новые модули pod.
- Сделайте так, чтобы существующие модули pod на этом узле продолжали выполняться до тех пор, пока они не будут вручную вытеснены или завершены.
kubectl drain
Команда kubectl drain, с другой стороны, выполняет действия kubectl cordon на узле, а затем вытесняет все модули pod с этого узла. Другими словами, он помечает узел как незапланированный, чтобы на нем не производилось никаких новых развертываний. После этого он изящно вытесняет все поды из узла. Обычно он используется для задач технического обслуживания, где узел должен быть очищен от работающих модулей pod, например, во время обновления узла или вывода из эксплуатации.
Примечание: Команда drain будет ожидать корректного вытеснения всех капсул. Поэтому не следует работать на машине до тех пор, пока команда не завершится.
Пример использования команды kubectl drain
Чтобы выполнить дренаж узла, определите узел для стока:
kubectl get nodes
Выполните команду drain для узла:
kubectl drain <node-name>
Что касается слива подов, работающих на узле Kubernetes, все поды, кроме DaemonSet и статических/зеркальных подов, безопасно вытесняются.
Таким образом, если на узле есть поды, управляемые набором демонов, команда drain не будет выполнена без опции —ignore-daemonsets, которая указывает ей пропустить сброс таких подов.
Для получения дополнительной информации о параметрах командной строки обратитесь к:
kubectl drain --help
Все вытесненные модули pod будут перенесены на другие доступные узлы.
Иллюстрация Kubectl Cordon/Drain
Процесс оцепления и выселения капсул из узлов проиллюстрирован на схеме ниже.
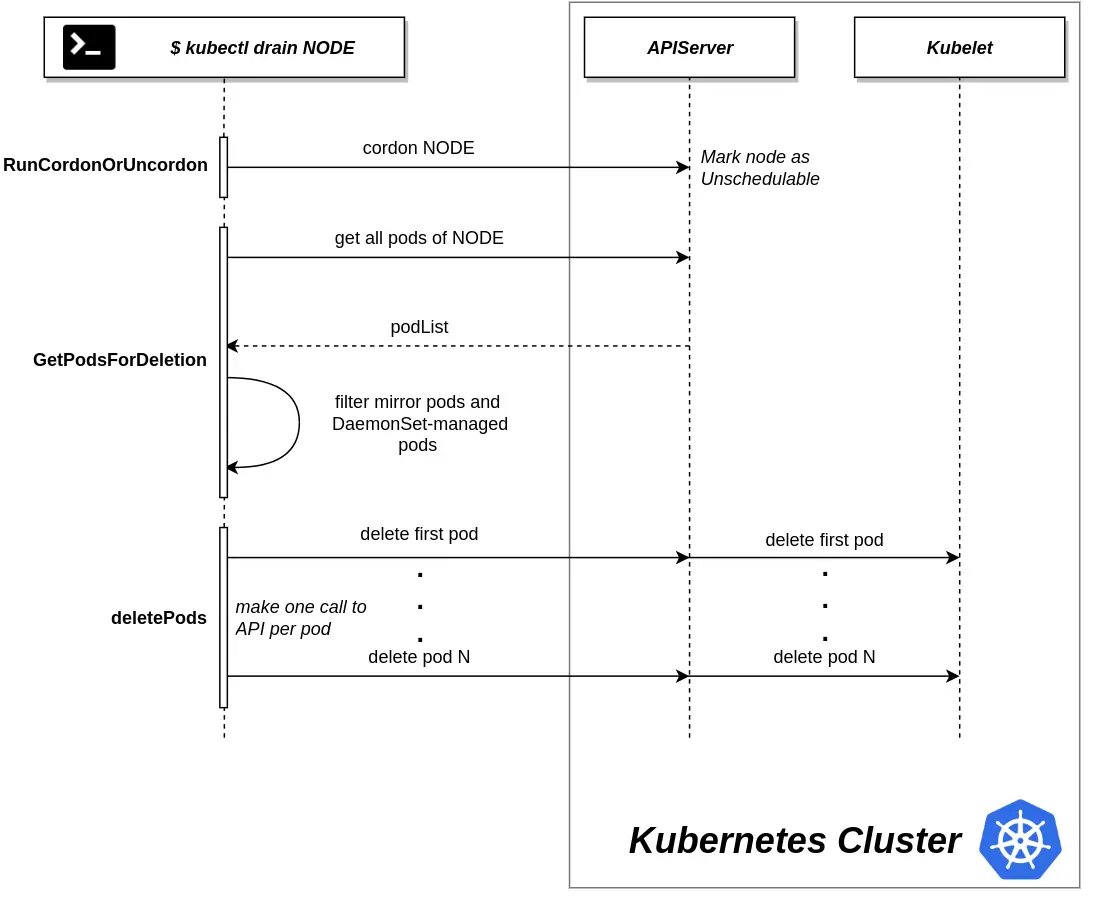
kubectl drain node gets stuck forever [Ошибка Apparmor]
Вы пробовали слить узел, но это заняло много времени или даже не удалось? Ну, частично для экспериментов мои рабочие узлы , размещенные в системе Ubuntu 24.04, а остальные на Rocky Linux 9.5 и RHEL9.5, используют контейнерный CRI.
kubectl drain k8swor1.kalyuzhnyy.ru --ignore-daemonsets
node/k8swor1.kalyuzhnyy.ru cordoned
Warning: ignoring DaemonSet-managed Pods: calico-system/calico-node-7lg6j,
calico-system/csi-node-driver-vbztn, kube-system/kube-proxy-9g7c6
evicting pod calico-system/calico-typha-bd8d4bc69-8mnjl
evicting pod apps/nginx-app-6ff7b5d8f6-hsljs
...
И капсулы застряли на terminating… state!
Это подтолкнуло меня к проверке логов на рабочих узлах и увы!
sudo tail -f /var/log/kern.log
worker-01 kernel: audit: type=1400 audit(1718391883.329:221): apparmor="DENIED" operation="signal"
class="signal" profile="cri-containerd.apparmor.d" pid=7445 comm="runc" requested_mask="receive"
denied_mask="receive" signal=kill peer="runc"
В файле журнала, по сути, говорится;
- runc, среда выполнения, используемая CRI, например, containerd для управления контейнерами, пыталась получить сигнал об уничтожении для завершения работы контейнеров.
- Однако, когда он попытался получить сигнал об убийстве, это действие было отклонено политикой безопасности AppArmor в профиле cri-containerd.apparmor.d.
Актуальные версии containerd/runc;
root@k8swor1.kalyuzhnyy.ru:~# containerd --version
containerd github.com/containerd/containerd 1.7.12
root@k8swor1.kalyuzhnyy.ru:~# runc --version
runc version 1.1.12-0ubuntu3
spec: 1.0.2-dev
go: go1.22.2
libseccomp: 2.5.5
root@k8swor1.kalyuzhnyy.ru:~# crictl --version
crictl version v1.30.0
root@k8swor1.kalyuzhnyy.ru:~#
Вы поняли, что, хотя вы можете обойти эту неприятность, остановив сервис apparmor, на самом деле вы можете открыть ящик Пандоры в своей системе. Поэтому, чтобы избежать этого, вы можете просто выгрузить профиль cri-containerd.apparmor.d, который по умолчанию не хранится в каталоге профилей apparmor, /etc/apparmor.d/, используя команду aa-remove-unknown.
Согласно справочной странице;
aa-remove-unknown will inventory all profiles in /etc/apparmor.d/, compare that list to the profiles currently loaded into the kernel, and then remove all of the loaded profiles that were not found in /etc/apparmor.d/. It will also report the name of each profile that it removes on standard out.
Следовательно, выполните команду;
sudo aa-remove-unknown
Теперь команда drain должна быть выполнена до конца.
Вы можете временно остановить сервис apparmor, когда вы опустошаете узлы/удаляете поды, и запустить его снова после того, как узлы будут опустошены/поды завершены.
НО, к счастью, есть возможность вручную создать профиль cri-containerd.apparmor.d, который прекрасно справляется с этой ошибкой. Вы можете установить профиль, выполнив команду ниже.
sudo tee /etc/apparmor.d/cri-containerd.apparmor.d << 'EOL'
#include <tunables/global>
profile cri-containerd.apparmor.d flags=(attach_disconnected,mediate_deleted) {
#include <abstractions/base>
network,
capability,
file,
umount,
# Host (privileged) processes may send signals to container processes.
signal (receive) peer=unconfined,
# runc may send signals to container processes.
signal (receive) peer=runc,
# crun may send signals to container processes.
signal (receive) peer=crun,
# Manager may send signals to container processes.
signal (receive) peer=cri-containerd.apparmor.d,
# Container processes may send signals amongst themselves.
signal (send,receive) peer=cri-containerd.apparmor.d,
deny @{PROC}/* w, # deny write for all files directly in /proc (not in a subdir)
# deny write to files not in /proc/<number>/** or /proc/sys/**
deny @{PROC}/{[^1-9],[^1-9][^0-9],[^1-9s][^0-9y][^0-9s],[^1-9][^0-9][^0-9][^0-9]*}/** w,
deny @{PROC}/sys/[^k]** w, # deny /proc/sys except /proc/sys/k* (effectively /proc/sys/kernel)
deny @{PROC}/sys/kernel/{?,??,[^s][^h][^m]**} w, # deny everything except shm* in /proc/sys/kernel/
deny @{PROC}/sysrq-trigger rwklx,
deny @{PROC}/mem rwklx,
deny @{PROC}/kmem rwklx,
deny @{PROC}/kcore rwklx,
deny mount,
deny /sys/[^f]*/** wklx,
deny /sys/f[^s]*/** wklx,
deny /sys/fs/[^c]*/** wklx,
deny /sys/fs/c[^g]*/** wklx,
deny /sys/fs/cg[^r]*/** wklx,
deny /sys/firmware/** rwklx,
deny /sys/devices/virtual/powercap/** rwklx,
deny /sys/kernel/security/** rwklx,
# allow processes within the container to trace each other,
# provided all other LSM and yama setting allow it.
ptrace (trace,tracedby,read,readby) peer=cri-containerd.apparmor.d,
}
EOL
Затем проверьте файл на наличие синтаксических ошибок и загрузите его в подсистему безопасности AppArmor.
sudo apparmor_parser -r /etc/apparmor.d/cri-containerd.apparmor.d
Это также должно идеально решить вопрос. Подробнее о вероятной ошибке.
Обязательно следите за логами, kern.log или системным журналом на предмет любых проблем, связанных с apparmor.
Работа с бюджетом на нарушение работы капсул (PDB)
Бюджет прерывания работы pod (PDB) — это ресурс Kubernetes, который указывает минимальное количество или процент модулей pod в развертывании, которые должны быть доступны в любой момент времени. Он используется для обеспечения того, чтобы определенное количество модулей оставалось в рабочем состоянии во время добровольных сбоев, таких как техническое обслуживание или обновления. PDB особенно важны для обеспечения высокой доступности и стабильности приложений, гарантируя, что критически важные сервисы останутся доступными даже во время запланированных сбоев.
При очистке узла с помощью kubectl Kubernetes проверяет PDB-файлы, чтобы убедиться, что не нарушен определенный бюджет на прерывание. Если вытеснение пода нарушит PDB, Kubernetes заблокирует вытеснение и отобразит сообщение об ошибке.
Если команда drain заблокирована из-за нарушений PDB, у вас есть несколько вариантов:
- Настройка PDB: Временно отрегулируйте PDB, чтобы обеспечить большую гибкость во время периода обслуживания.
- Принудительное истощение: В крайнем случае, вы можете использовать флаг –force для принудительного слива, игнорируя PDB-файлы. Это следует делать с особой осторожностью, так как это может привести к простою приложения.
Повторное включение планирования модулей pod на узле
Когда вы будете готовы снова ввести узел в эксплуатацию, вы можете снова сделать его доступным для планирования с помощью команды;
kubectl uncordon <cordoned-node-name>
Например;
kubectl uncordon master-01
Заключение
Подводя итог;
КомандаПланирование новых модулей podВыселение стручковkubectl cordonПредотвращает планирование новых модулей pod на узлеНе вытесняет существующие стручки.kubectl drainПредотвращает планирование новых модулей pod на узле и вытесняет существующие модули pod.Вытесняет существующие поды, исключая по умолчанию DaemonSet и статические поды.
Подробнее о:
kubectl cordon --help
kubectl drain --help
Если у вас есть какие-либо мысли или вопросы по этой теме, пожалуйста, не стесняйтесь оставить комментарий или отправить мне сообщение. Я хотел бы продолжить дискуссию и услышать вашу точку зрения.
А также вы всегда можете поддержать меня зайдя на сайт и подписаться https://dzen.ru/kalyuzhnyy.ru и найти больше статей на моих ресурсах https://kalyuzhnyy.ru и https://dev.kalyuzhnyy.ru