
Во вкладке Normality (Проверка на нормальность) модуля Descriptive statistics программы Statisticа есть опции Normal expected frequencies, Kolmogorov-Smirnov & Lilliefors test for normality и Shapiro-Wilk's W test.
Рассмотрим последний из них - Shapiro-Wilk’s W test (W-тест Шапиро-Уилка).
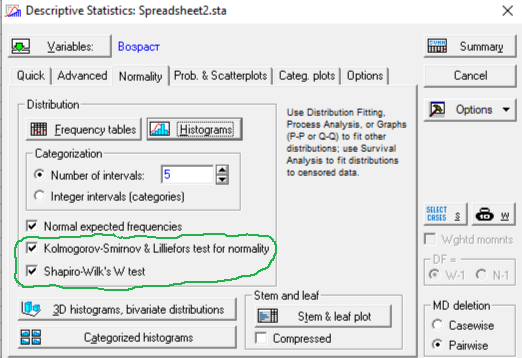
!Тест Шапиро-Уилка разработан, прежде всего, для проверки нормальности распределения малых выборок, численностью от 3 до 50 элементов!
Н0: выборка распределена нормально;
Н1: проверяемые данные не распределены нормально.
Рассмотрим, как работает W-тест Шапиро-Уилка на примере выборки, состоящей из нескольких значений кардиоинтервала.
Кардиоинтервалы — это время между соседними сокращениями сердца. На основе кардиоинтервалов строится кардиоинтервалограмма (КИГ). КИГ является одним из наиболее показательных методов статистической оценки сердечного ритма. Кардиоинтервалы измеряются по длительности RR – интервалов электрокардиограммы (ЭКГ) в секундах или миллисекундах (1 с=1000 мс).
У нас есть выборка (Т1, ... ,Тn) объёмом n = 10.
Т = (0,83; 0,72; 0,68; 0,75; 0,74; 0,44; 1,10; 0,70; 0,75; 0,78). Это значения 10 кардиоинтервалов, каждому из которых мы присвоили обозначение Тj. То есть, Т1 = 0,83; Т2 = 0,72; Т3 = 0,68 и т.д.
Проверим распределение этой выборки на нормальность, используя критерий Шапиро-Уилка. Для этого нам нужно рассчитать статистику критерия Шапиро-Уилка - W-статистику, по формуле:
, где b - вспомогательная величина, которая рассчитывается следующим образом:
, а D - дисперсия выборки:
Расчёт дисперсии подробно разобран здесь.
Алгоритм расчёта W-статистики критерия Шапиро-Уилка
Для этого удобно построить вспомогательную таблицу. Сначала просто внесём в неё 10 значений кардиоинтервалов из нашей выборки Тj.
Шаг 1. Упорядочим выборку Тj, расположив её значения в столбик от наименьшего к наибольшему.
Шаг 2. Найдём значение k:
У нас k = 10/2 = 5. Расположим числа от 1 до 5 в столбик в таблице.
Шаг 3. Найдём ∆Т, и также запишем значения в столбик. Они вычисляются следующим образом: из последнего элемента упорядоченной выборки вычитается первый, затем из предпоследнего – второй, и т. д.
У нас чётный объём выборки из 10 значений, поэтому все члены выборки используются для вычисления ∆Т. Но если объем выборки – число нечётное, то центральный элемент упорядоченной выборки в образовании разностей не участвует (т.е. если бы объем выборки был бы 11, а не 10, то все равно было бы образовано 5 разностей).
Шаг 4. Ищем известную константу an,k в специальной таблице:
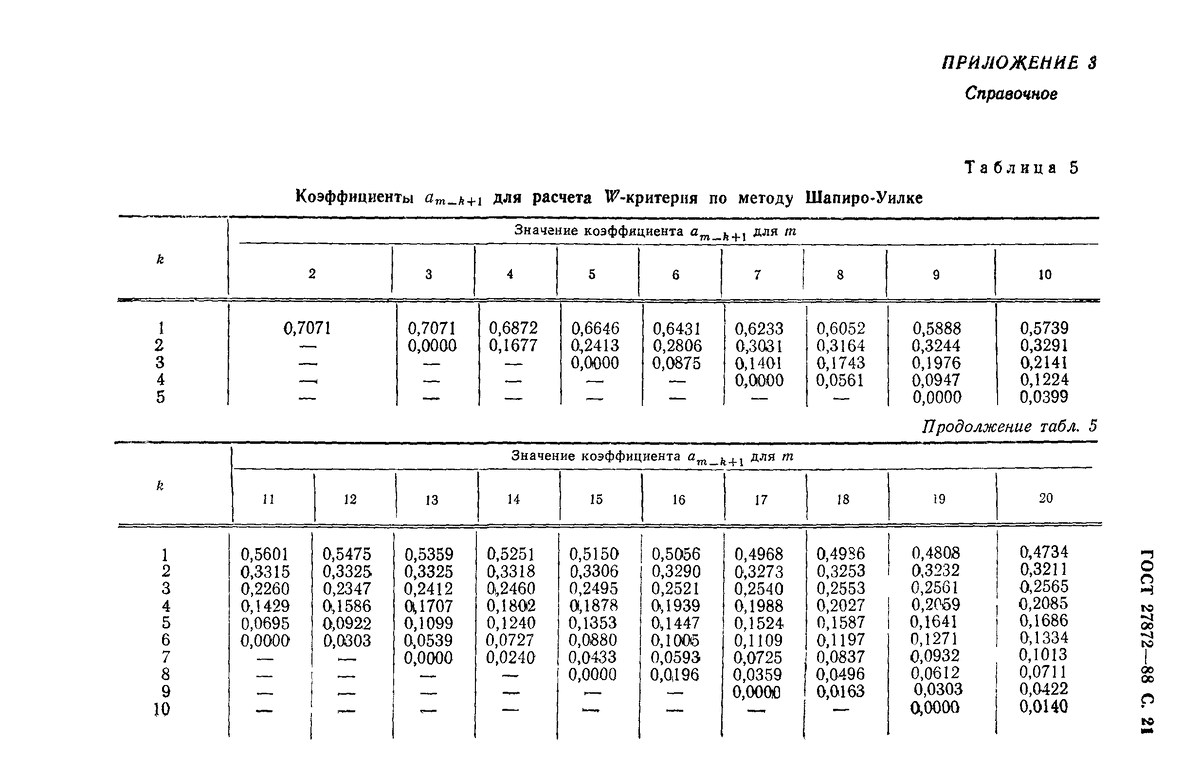
Шаг 5. Перемножаем значения ∆Т и an,k из соответствующих колонок.
Шаг 6. В результате выполнения Шага 5 получится 5 произведений ∆Т * an,k. Их нужно сложить. Получится искомая величина b, которая у нас составляет 0,4493.
Шаг 7. Расчёт дисперсии подробно разобран здесь. В нашем примере D = 0,0072.
Шаг 8.
Наконец,
Шаг 9. Сравниваем Wконтр с критическим табличным значением Wкрит с уровнем значимости α = 0,05 или α = 0,01.
Критическое значение W на уровне значимости α = 0.05:
Wкрит = 0,842.
Шаг 10. Wконтр = 3,16 > Wкрит = 0,842.
Вывод: с доверительной вероятностью p = 0.95 (1 - 0,05) в проанализированной выборке Тj выполняется нормальный закон распределения.
ВАЖНО: при работе с критерием Шапиро-Уилка нулевая гипотеза принимается, если контрольное значение критерия больше критического (а не меньше, как обычно в подобных ситуациях при работе с другими критериями).