
Закон нормального распределения имеет особую важность для медицины и биологии. Пример: для определения среднего роста и веса людей в разных возрастных группах, для определения нормальных уровней кровяного давления, холестерина, глюкозы и т. д. Более того, в силу центральной предельной теоремы, распределение многих величин при достаточно больших объёмах выборки хорошо аппроксимируется нормальным распределением вне зависимости от того, какое распределение было у выборки исходно!
!Проверка распределения данных на нормальность - обязательна на начальном этапе статистической обработки данных!
Существует множество вариантов проверки данных на нормальность, и мы начнём с самого очевидного: с помощью вкладки Normality модуля Descriptive statistics программы Statisticа.
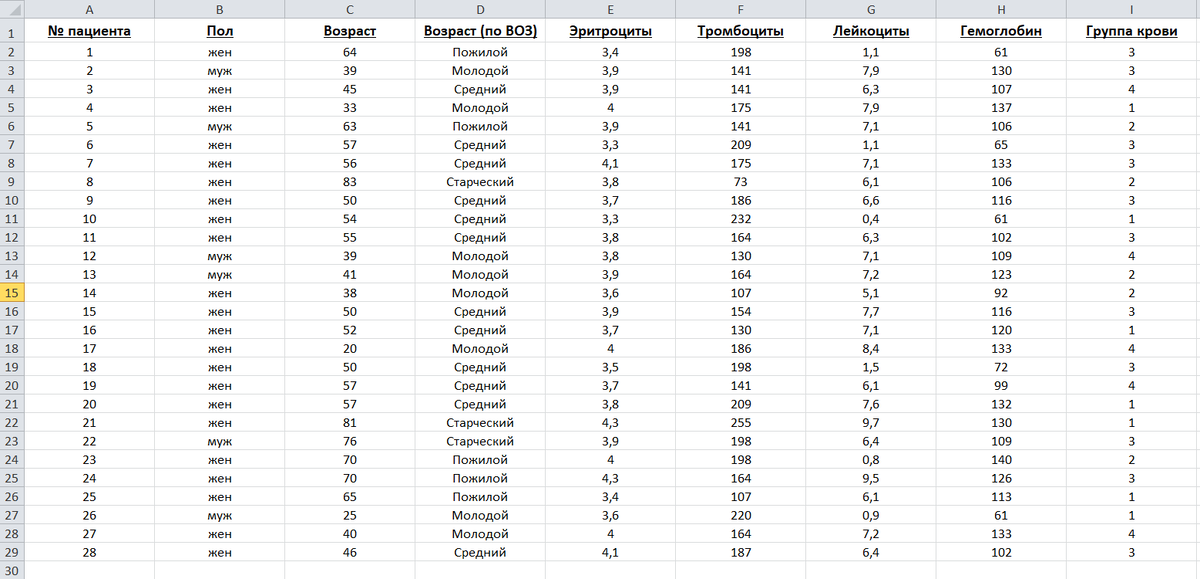
В качестве примера рассмотрим таблицу с гемограммами 28 пациентов.
1. Запустим модуль Basic Statistics:
2. Выберем пункт Descriptive Statistics. Нажмём OK:
3. Перед нами появилось диалоговое окно Descriptive statistics, которое по умолчанию открыто на вкладке Quick (Быстро).
4. Мы нажимаем на вкладку Normality (Проверка на нормальность). Нажмём на кнопку Variables и выберем из списка анализируемую переменную. Пусть это будет возраст наших 28 рандомных пациентов - переменная Возраст.
Обратите внимание, что галочкой отмечена строчка Show appropriate variables only. Это означает, что нам предлагаются именно те переменные, которые можно "уложить" в непрерывное, а не дискретное, распределение.
Итак, переменная Возраст выбрана.
5. Сразу поставим флажки рядом с опциями Normal expected frequencies, Kolmogorov-Smirnov & Lilliefors test for normality и Shapiro-Wilk's W test. Собственно, это и есть наиболее распространенные методы проверки принадлежности данных на нормальность.
- опция Normal expected frequencies (Ожидаемые нормальные частоты) - при ее выделении и последующем нажатии на кнопку Frequency tables программа выдаст таблицу, которая помимо фактических частот численных значений переменной, будет содержать также теоретически ожидаемые нормальные частоты.
- опция Kolmogorov-Smirnov & Lilliefors test for normality (Тест Колмогорова-Смирнова и Лиллиефорса на нормальность) - тест, применяемый для проверки соответствия анализируемых данных закону нормального распределения.
- опция Shapiro-Wilk’s W test (W-тест Шапиро-Уилка) - другой тест, применяемый для проверки соответствия данных нормальному распределению.
Кнопка Frequency tables (Таблицы частот) – вычисление таблицы частот для каждой выбранной переменной. Для группировки данных предназначены опции под общим названием Categorization (Категоризации). Можно поставить флажок рядом с одним из двух методов: Number of intervals - по числу интервалов и Integer intervals (categories) - по категориям.
6. Разбиение совокупности на группы, однородные по какому-либо признаку, называется группировкой. Признак, по которому происходит объединение отдельных единиц совокупности в однородные группы, называется группировочным признаком (он может быть как количественным, так и качественным). Количественные границы выделяемых групп очерчивает интервал, представляющий собой промежуток между максимальными и минимальными значениями признака в группе. Интервал – это значение варьирующего признака, лежащее в определенных границах. Для анализируемой переменной Возраст группировочный признак будет количественным, и начнём мы с того, что разобьём его на интервалы.
Метод Number of intervals (Число интервалов) позволяет получить ряд распределения с заданным количеством равных интервалов. Количество интервалов пользователь задаёт кнопками со стрелками вверх и вниз. Поставим число 5 для нашего примера.
Перед нами - наглядная частотная таблица, в которой программа автоматически отметила возрастные интервалы с шагом 20, при этом границы интервалов установлены (также автоматически) от 0 до 100. Это мы видим в столбце Category (Категория), который содержит ранжированные численные значения анализируемой переменной, отмеченные в выборке. Следует помнить, что Statisticа не всегда абсолютно точно устанавливает заданное пользователем число интервалов, иногда программа сама определяет, что нужно отнять/добавить "лишнюю" строку, исходя из характера данных.
Также в таблице имеются столбцы со следующими условными обозначениями:
- Count (Счет): здесь приведены частоты, с которыми в выборке встречались те или иные значения переменной. В нашем примере: 1 пациент принадлежит возрастной категории 0 - 20, 6 пациентов - относится к возрастному интервалу 20 - 40, 13 (максимальное число) - принадлежит возрастной категории 40 - 60 и так далее.
- Cumulative count (Кумулятивный счёт): накопленные частоты численных значений переменной. Это - частота переменной на данном интервале плюс частота переменной на предыдущем интервале. В нашем примере: интервал 20-40 содержит 6 пациентов своего интервала плюс 1 из интервала 0 - 20, то есть, 7.
- Percent of valid (Процентная доля): процентная доля, которую составляет каждая из частот от общего числа наблюдений. В нашем примере: 3,57143 % составляют пациенты (1 человек), принадлежащие возрастной категории 0 - 20, и так далее.
- Cumul % of valid (Cumulative percent, Накопленные доли процентов): накопленные процентные доли частот значений переменных. В нашем примере: 25,00000 % содержит интервал 20 - 40, что складывается из 21,42857% (6 человек) категории 20 - 40 и 3,57143 % (1 человек), принадлежащих возрастной категории 0 - 20. Нетрудно догадаться, что последняя строчка будет содержать 100%.
- % of all cases (% от общего ко-ва) - процентная доля, которую составляет каждая из частот от общего числа наблюдений ПЛЮС незаполненные ячейки с пропущенными значениями. Если таковые отсутствуют, то % of all cases совпадает с Percent of valid. В нашем примере значения совпадают.
- Cumulative % of All (Накопленные доли процентов от общего количества) - накопленные процентные доли всех частот значений переменных, куда включены незаполненные ячейки. Если таковые отсутствуют, то Cumulative % of All совпадает с Cumulative % of All. В нашем примере значения совпадают.
- Expected count (Ожидаемый счёт) - теоретически ожидаемые частоты, с которыми должны встречаться в выборке значения переменной при условии, что выборка - нормально распределена.
- Cumulative Expected (Ожидаемый кумулятивный счёт) - теоретически ожидаемые при нормальном распределении накопленные частоты численных значений переменной.
- Percent Expected - процентная доля, которую в теории при идеальном нормальном распределении должно составлять каждое значение переменной от их общего числа .
- Cumulative % Expected - накопленные процентные доли частот значений переменных, которые ожидаются при теоретически рассчитанной нормально распределённой выборке.
*Последняя строка итоговой таблицы называется Missing (Отсутствующие) - она имеет отношение к пропущенным (т.е. не внесенным в таблицу) значениям анализируемой переменной. Таковых в нашем примере нет, в связи с чем, на пересечении столбца Count и строки Missing видим 0. Стоит отметить, что строка Missing появляется только, если включен режим обработки пропущенных данных Pairwise. Если же для пропущенных данных используется Casewise, эта строка будет отсутствовать, также, как и столбцы % of all cases и Cumulative % of All в таблице с частотами.
Так как мы проставили флажки рядом с опциями Normal expected frequencies, Kolmogorov-Smirnov & Lilliefors test for normality и Shapiro-Wilk's W test, то в верхней строке таблицы мы сразу можем увидеть, что:
1) статистика Колмогорова-Смирнова d = 0,10596. Чем меньше величина этой статистики, тем ближе распределение случайной величины к нормальному. Вероятность нулевой гипотезы (р) более 0,20. Иными словами, мы можем принять нулевую гипотезу о том, что распределение исследуемой величины "Возраст" статистически значимо не отличается от нормального. Таким же образом здесь интерпретируется Lilliefors test;
2) статистика Shapiro-Wilk's W = 0,98488, р = 0,94670. Результаты W-теста Шапиро-Уилка также говорят о том, что мы можем принять нулевую гипотезу и утверждать, что переменная "Возраст" распределена по нормальному закону.
Графическим изображением вариационного ряда при непрерывной вариации является гистограмма. Чтобы увидеть её, справа от кнопки Frequency tables находится кнопка Histograms (Гистограмма). Она даёт возможность построить графики гистограмм для каждой выбранной переменной с наложенной кривой нормального распределения. Все настройки, произведенные для таблицы частот, действуют и в отношении гистограмм. И сверху мы также можем увидеть рассчитанные критерии Колмогорова-Смирнова, Лиллиефорса и Шапиро-Уилкса.
Каждый столбец полученной гистограммы соответствует конкретному интервалу (отображено на оси абсцисс). Ось ординат - частота переменных, встречаемых на данном интервале.
7. Группировка, в которой для характеристики групп применяется численность группы, называется рядом распределения. Ряд распределения состоит из двух элементов: варианты – отдельного значения варьирующего признака, которое он принимает в ряду распределения, и частоты – численность отдельных вариант, т.е. частота повторения каждой варианты. Если частота выражена в долях единицы или в процентах к итогу (к общей сумме частот), то это – частость.
Метод Integer intervals (categories) (Целые интервалы (категории)) позволяет получить дискретный ряд распределения, где будут перечислены все встречающиеся значения. Обычно этот метод построения таблицы частот используют для дискретных данных. Однако и для непрерывных данных построение категоризированной таблицы частот может быть актуально, если а) данных не слишком много, и б) встречающихся значений переменной также не слишком много. Поэтому для наглядности используем всё ту же переменную Возраст из таблицы с гемограммами 28 пациентов.
Поставим флажок рядом с методом категоризации Integer intervals (categories). Мы увидим, что опции оценки нормальности - Normal expected frequencies, Kolmogorov-Smirnov & Lilliefors test for normality и Shapiro-Wilk's W test, стали неактивными. Это неудивительно, опираясь на данные, категоризированные по такому методу, невозможно оценить их "нормальность"!
Щёлкнем кнопку Frequency tables (Таблицы частот).
Перед нами - категоризированная таблица, в столбце Category (Категория) которой содержатся все значения анализируемой переменной, то есть, все возраста наших 28 пациентов.
Условные обозначения, встречаемые в данной частотной таблице: Count, Cumulative count, Percent of valid, Cumul % of valid, % of all cases, Cumulative % of All - аналогичны тем, которые использовались в таблице частот, построенной по методу Number of intervals. Только здесь эти показатели применены ко всем значениям переменной, которые встречаются в выборке с определённой частотой. Собственно, так как Integer intervals (categories) обычно применяют для дискретных данных, то каждая строчка в этом случае обычно и представляет собой какой-либо интервал (группу). В нашем примере каждая строчка соответствует значению переменной Возраст.
Графическим изображением вариационного ряда при дискретной вариации признака является полигон распределения. Чтобы визуализировать это, нажмём кнопку Histograms (Гистограмма):
Перед нами - гистограмма (полигон), каждый столбец которой соответствует значению переменной (отображено на оси абсцисс Category). Ось ординат - частота данной переменной в данной выборке.
8. Выйдем из модуля Basic Statistics и туда зайдём снова. Нажмём на кнопку "3D histograms, bivariate distributions". В рабочем окне для ввода данных укажем, допустим, Возраст и Гемоглобин. Нажмём OK:
Перед нами - 3D гистограмма.
9. Нажмём на кнопку Categorized histograms. Так как переменная Возраст уже выбрана нами ранее, перед нами сразу откроется поле выбора переменных, по которым может осуществляться категоризация (номинальные и порядковые). В нашем примере это пол пациентов (номинальная переменная) и возраст в соответствии с классификацией возрастов, принятой ВОЗ (порядковая переменная). Допустим, нас интересует категоризация только по признаку пола, соответственно, в одном, первом, поле мы указываем Пол. Далее программа предлагает нам обозначить названия переменной, нажимаем на кнопку All, и видим, что категории переменной автоматически обозначаются так, как мы их указали в списке: жен и муж.
Нажмём Ок, и увидим гистограммы частотных распределений отдельно для категорий муж. и жен.
Сверху находится надпись, которая содержит: жен Возраст = 22*10*normal(х; 54,2273; 14,7678). 22 - число пациентов с меткой жен., 10 - число интервалов, на который разбит ряд Возраст, 54,2273 - средний возраст пациенток, 14,7678 - стандартное отклонение показателя. Аналогично расшифровывается вторая строчка, с меткой муж.
10. Диаграмма «стебель-листья» (диаграмма «опора-и-консоль»).
Это такой интересный способ систематизации данных по их разрядному значению, для демонстрации распределения данных.
Таким образом, в наборе данных (4,11,2,20,17,23) данные будут распределены на основе десятков, но отображаться при этом будут только единицы:
0 - 2, 4
10 - 1, 7
20 - 0, 3
Диаграммы «стебель-листья» удобны для краткого обзора распределения данных, а также для выявления выбросов и моды. Если имеется два набора данных, можно составить двойную или парную диаграмму «стебель-листья» - это позволить сопоставить наборы данных друг с другом.
С точки зрения слабых сторон, диаграммы «стебель-листья» ограничены объемом данных, которые они могут отобразить. Если данных слишком мало, теряется смысл, а если слишком много, диаграмма становится перегруженной.
Чтобы получить диаграмму «стебель-листья» нужно нажать кнопку Stem & leaf plot. Из предложенных переменных выберем Гемоглобин.
Если поставить отметить флажком опцию Compressed, мы получаем ту же диаграмму «стебель-листья», но в сжатом виде, с теми же интерпретациями.