Прогнозирование временных рядов — полезный метод науки о данных, который можно применять в самых разных отраслях и областях. Вот руководство по началу работы с основными концепциями, лежащими в его основе.
Прогнозирование временных рядов — это задача прогнозирования будущих значений на основе исторических данных. Примеры из разных отраслей включают прогнозирование погоды, объемов продаж и цен на акции. Совсем недавно он был применен для прогнозирования ценовых тенденций для криптовалют, таких как биткойн и эфириум. Учитывая распространенность приложений для прогнозирования временных рядов во многих различных областях, каждый специалист по данным должен иметь некоторые знания о доступных методах его выполнения.
Для прогнозирования временных рядов доступен широкий спектр методов. Одной из наиболее часто используемых является авторегрессивная скользящая средняя (ARMA), статистическая модель, которая предсказывает будущие значения, используя прошлые значения. Однако этот метод несовершенен, поскольку не учитывает сезонные тенденции. Он также предполагает, что данные временного ряда являются стационарными, что означает, что их статистические свойства не изменятся с течением времени. Этот тип поведения является идеализированным предположением, которое, однако, не выполняется на практике, а это означает, что ARMA может давать искаженные результаты.
Расширением ARMA является модель авторегрессивной интегрированной скользящей средней (ARIMA), которая не предполагает стационарность, но все же предполагает, что данные практически не имеют сезонности. К счастью, сезонный вариант ARIMA (SARIMA) представляет собой статистическую модель, которая может работать с нестационарными данными и фиксировать некоторую сезонность.
Python предоставляет множество простых в использовании библиотек и инструментов для прогнозирования временных рядов. В частности, в библиотеке статистики Python есть инструменты для построения моделей ARMA, ARIMA и SARIMA всего несколькими строками кода. Поскольку все эти модели доступны в одной библиотеке, вы можете легко проводить множество экспериментов с использованием разных моделей в одном скрипте или блокноте.
Здесь мы рассмотрим, как построить модели ARMA, ARIMA и SARIMA для прогнозирования будущих цен на биткойны (BTC).
Чтение и отображение данных временных рядов BTC
Мы начнем с чтения исторических цен на BTC с помощью программы чтения данных Pandas. Давайте установим его с помощью простой команды pip в терминале:
pip install pandas-datareader
Давайте откроем скрипт Python и импортируем средство чтения данных из библиотеки Pandas:
import pandas_datareader.data as web
import datetime
Давайте также импортируем саму библиотеку Pandas и ослабим ограничения на отображение столбцов и строк:
import pandas as pd
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
Теперь мы можем импортировать библиотеку даты и времени, которая позволит нам определить даты начала и окончания для нашего извлечения данных:
import datetime
Теперь у нас есть все необходимое для извлечения данных временных рядов цен на биткойны, давайте соберем данные.
import pandas_datareader as web
btc = web.get_data_yahoo(['BTC-USD'], start=datetime.datetime(2018, 1, 1), end=datetime.datetime(2020, 12, 2))['Close']
print(btc.head())
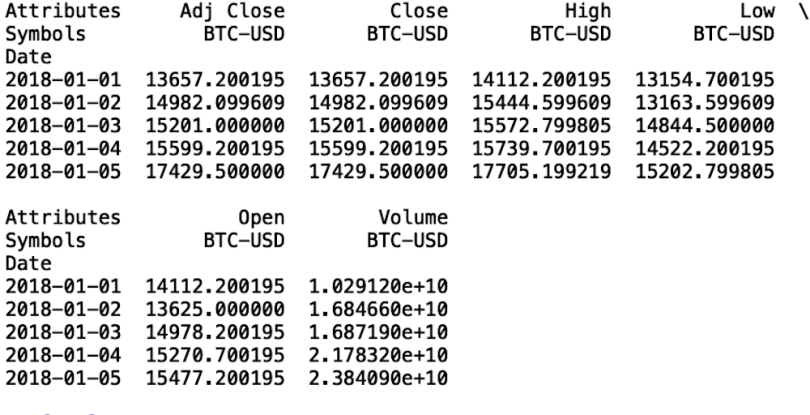
Мы видим, что наш фрейм данных содержит много столбцов. Давайте рассмотрим, что означает каждый из этих столбцов.
- Дата: это индекс в нашем временном ряду, который указывает дату, связанную с ценой.
- Закрытие: последняя цена, по которой BTC был куплен в этот день.
- Открыто: первая цена, по которой BTC был куплен в этот день.
- High: Самая высокая цена, по которой BTC был куплен в этот день.
- Низкая: самая низкая цена, по которой BTC был куплен в этот день.
- Объем: общее количество сделок за день.
- Adj Close: цена закрытия с поправкой на дивиденды и дробление акций.
Мы будем использовать цену закрытия для наших моделей прогнозирования. В частности, мы будем использовать исторические цены закрытия BTC, чтобы предсказать будущие цены BTC.
Давайте запишем наши данные о цене закрытия BTC в файл csv. Таким образом, мы можем избежать повторного извлечения данных с помощью средства чтения данных Pandas.
btc.to_csv("btc.csv")
Теперь давайте прочитаем наш CSV-файл и отобразим первые пять строк:
btc = pd.read_csv("btc.csv")
print(btc.head())
Чтобы использовать модели, предоставляемые библиотекой статистики, нам нужно установить столбец даты в качестве индекса фрейма данных. Мы также должны отформатировать эту дату, используя метод to_datetime:
btc.index = pd.to_datetime(btc['Date'], format='%Y-%m-%d')
Давайте отобразим наш фрейм данных:
del btc['Date']
Давайте построим данные нашего временного ряда. Для этого импортируем библиотеки визуализации данных Seaborn и Matplotlib:
import matplotlib.pyplot as plt
import seaborn as sns
Давайте отформатируем нашу визуализацию с помощью Seaborn:
sns.set()
И пометьте ось Y и ось X, используя Matplotlib. Мы также повернем даты по оси x, чтобы их было легче читать:
plt.ylabel('BTC Price')
plt.xlabel('Date')
plt.xticks(rotation=45)
И, наконец, сгенерируйте наш график с помощью Matplotlib:
plt.plot(btc.index, btc['BTC-USD'], )
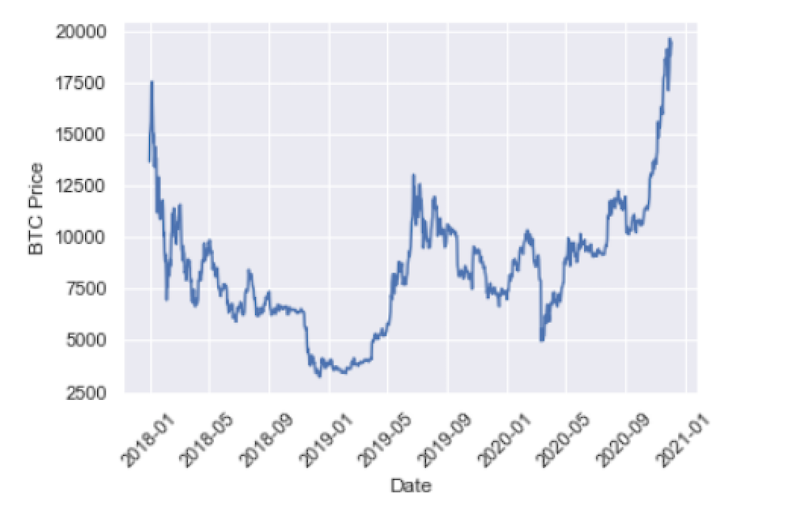
Теперь мы можем приступить к построению нашей первой модели временного ряда, авторегрессионной скользящей средней.
Разделение данных для обучения и тестирования
Важной частью построения модели является разделение наших данных для обучения и тестирования, что гарантирует, что вы создадите модель, которая может обобщаться за пределами обучающих данных, и что производительность и выходные данные будут статистически значимыми.
Мы разделим наши данные таким образом, чтобы все данные до ноября 2020 года служили обучающими данными, а все данные после 2020 года — данными тестирования:
train = btc[btc.index < pd.to_datetime("2020-11-01", format='%Y-%m-%d')]
test = btc[btc.index > pd.to_datetime("2020-11-01", format='%Y-%m-%d')]
plt.plot(train, color = "black")
plt.plot(test, color = "red")
plt.ylabel('BTC Price')
plt.xlabel('Date')
plt.xticks(rotation=45)
plt.title("Train/Test split for BTC Data")
plt.show()
Авторегрессионная скользящая средняя (ARMA)
Термин «авторегрессия» в ARMA означает, что модель использует прошлые значения для прогнозирования будущих. В частности, прогнозируемые значения представляют собой взвешенную линейную комбинацию прошлых значений. Этот тип метода регрессии похож на линейную регрессию, с той разницей, что входными данными здесь являются исторические значения.
Скользящее среднее относится к предсказаниям, представленным взвешенной линейной комбинацией условий белого шума, где белый шум является случайным сигналом. Идея заключается в том, что ARMA использует комбинацию прошлых значений и белого шума для прогнозирования будущих значений. Авторегрессия моделирует поведение участников рынка, например, покупку и продажу BTC. Белый шум моделирует шокирующие события, такие как войны, рецессии и политические события.
Мы можем определить модель ARMA, используя пакет SARIMAX:
from statsmodels.tsa.statespace.sarimax import SARIMAX
Давайте определим наш ввод:
y = train['BTC-USD']
А затем давайте определим нашу модель. Чтобы определить модель ARMA с классом SARIMAX, мы передаем параметры порядка (1, 0, 1):
ARMAmodel = SARIMAX(y, order = (1, 0, 1))
Затем мы можем подогнать нашу модель:
ARMAmodel = ARMAmodel.fit()
Сгенерируйте наши прогнозы:
y_pred = ARMAmodel.get_forecast(len(test.index))
y_pred_df = y_pred.conf_int(alpha = 0.05)
y_pred_df["Predictions"] = ARMAmodel.predict(start = y_pred_df.index[0], end = y_pred_df.index[-1])
y_pred_df.index = test.index
y_pred_out = y_pred_df["Predictions"]
И постройте результаты:
plt.plot(y_pred_out, color='green', label = 'Predictions')
plt.legend()
Мы также можем оценить производительность, используя среднеквадратичную ошибку:
import numpy as np
from sklearn.metrics import mean_squared_error
arma_rmse = np.sqrt(mean_squared_error(test["BTC-USD"].values, y_pred_df["Predictions"]))
print("RMSE: ",arma_rmse)
RMSE довольно высок, о чем мы могли догадаться, изучив сюжет. К сожалению, модель предсказывает снижение цены, когда цена на самом деле растет. Опять же, ARMA ограничена тем, что не подходит для нестационарных временных рядов и не учитывает сезонность. Давайте посмотрим, сможем ли мы улучшить производительность с помощью ARIMA.
Мы также можем оценить производительность, используя среднеквадратичную ошибку:
import numpy as np
from sklearn.metrics import mean_squared_error
arma_rmse = np.sqrt(mean_squared_error(test["BTC-USD"].values, y_pred_df["Predictions"]))
print("RMSE: ",arma_rmse)
RMSE довольно высок, о чем мы могли догадаться, изучив сюжет. К сожалению, модель предсказывает снижение цены, когда цена на самом деле растет. Опять же, ARMA ограничена тем, что не подходит для нестационарных временных рядов и не учитывает сезонность. Давайте посмотрим, сможем ли мы улучшить производительность с помощью ARIMA.
Мы также можем оценить производительность, используя среднеквадратичную ошибку:
import numpy as np
from sklearn.metrics import mean_squared_error
arma_rmse = np.sqrt(mean_squared_error(test["BTC-USD"].values, y_pred_df["Predictions"]))
print("RMSE: ",arma_rmse)
RMSE довольно высок, о чем мы могли догадаться, изучив сюжет. К сожалению, модель предсказывает снижение цены, когда цена на самом деле растет. Опять же, ARMA ограничена тем, что не подходит для нестационарных временных рядов и не учитывает сезонность. Давайте посмотрим, сможем ли мы улучшить производительность с помощью ARIMA.
Мы также можем оценить производительность, используя среднеквадратичную ошибку:
import numpy as np
from sklearn.metrics import mean_squared_error
arma_rmse = np.sqrt(mean_squared_error(test["BTC-USD"].values, y_pred_df["Predictions"]))
print("RMSE: ",arma_rmse)
RMSE довольно высок, о чем мы могли догадаться, изучив сюжет. К сожалению, модель предсказывает снижение цены, когда цена на самом деле растет. Опять же, ARMA ограничена тем, что не подходит для нестационарных временных рядов и не учитывает сезонность. Давайте посмотрим, сможем ли мы улучшить производительность с помощью ARIMA.
Мы также можем оценить производительность, используя среднеквадратичную ошибку:
import numpy as np
from sklearn.metrics import mean_squared_error
arma_rmse = np.sqrt(mean_squared_error(test["BTC-USD"].values, y_pred_df["Predictions"]))
print("RMSE: ",arma_rmse)
RMSE довольно высок, о чем мы могли догадаться, изучив сюжет. К сожалению, модель предсказывает снижение цены, когда цена на самом деле растет. Опять же, ARMA ограничена тем, что не подходит для нестационарных временных рядов и не учитывает сезонность. Давайте посмотрим, сможем ли мы улучшить производительность с помощью ARIMA.
Давайте импортируем пакет ARIMA из библиотеки статистики:
from statsmodels.tsa.arima.model import ARIMA
Задача ARIMA имеет три параметра. Первый параметр соответствует запаздыванию (прошлым значениям), второй соответствует разнице (это то, что делает нестационарные данные стационарными), а последний параметр соответствует белому шуму (для моделирования ударных событий).
Давайте определим модель ARIMA с параметрами порядка (2,2,2):
ARIMAmodel = ARIMA(y, order = (2, 2, 2))
ARIMAmodel = ARIMAmodel.fit()
y_pred = ARIMAmodel.get_forecast(len(test.index))
y_pred_df = y_pred.conf_int(alpha = 0.05)
y_pred_df["Predictions"] = ARIMAmodel.predict(start = y_pred_df.index[0], end = y_pred_df.index[-1])
y_pred_df.index = test.index
y_pred_out = y_pred_df["Predictions"]
plt.plot(y_pred_out, color='Yellow', label = 'ARIMA Predictions')
plt.legend()
import numpy as np
from sklearn.metrics import mean_squared_error
arma_rmse = np.sqrt(mean_squared_error(test["BTC-USD"].values, y_pred_df["Predictions"]))
print("RMSE: ",arma_rmse)
Наконец, давайте посмотрим, повысит ли производительность SARIMA, учитывающая сезонность.
Сезонная АРИМА (SARIMA)
Сезонный ARIMA фиксирует исторические значения, шоковые события и сезонность. Мы можем определить модель SARIMA, используя класс SARIMAX:
SARIMAXmodel = SARIMAX(y, order = (5, 4, 2), seasonal_order=(2,2,2,12))
SARIMAXmodel = SARIMAXmodel.fit()
y_pred = SARIMAXmodel.get_forecast(len(test.index))
y_pred_df = y_pred.conf_int(alpha = 0.05)
y_pred_df["Predictions"] = SARIMAXmodel.predict(start = y_pred_df.index[0], end = y_pred_df.index[-1])
y_pred_df.index = test.index
y_pred_out = y_pred_df["Predictions"]
plt.plot(y_pred_out, color='Blue', label = 'SARIMA Predictions')
plt.legend()
Открытый поиск
+1
Руководство по прогнозированию временных рядов в Python
Прогнозирование временных рядов — полезный метод науки о данных, который можно применять в самых разных отраслях и областях. Вот руководство по началу работы с основными концепциями, лежащими в его основе.
Опубликовано 05 октября 2021 г.
Прогнозирование временных рядов — это задача прогнозирования будущих значений на основе исторических данных. Примеры из разных отраслей включают прогнозирование погоды, объемов продаж и цен на акции. Совсем недавно он был применен для прогнозирования ценовых тенденций для криптовалют, таких как биткойн и эфириум. Учитывая распространенность приложений для прогнозирования временных рядов во многих различных областях, каждый специалист по данным должен иметь некоторые знания о доступных методах его выполнения.
Видео обзор прогнозирования временных рядов
Для прогнозирования временных рядов доступен широкий спектр методов. Одной из наиболее часто используемых является авторегрессивная скользящая средняя (ARMA), статистическая модель, которая предсказывает будущие значения, используя прошлые значения. Однако этот метод несовершенен, поскольку не учитывает сезонные тенденции. Он также предполагает, что данные временного ряда являются стационарными, что означает, что их статистические свойства не изменятся с течением времени. Этот тип поведения является идеализированным предположением, которое, однако, не выполняется на практике, а это означает, что ARMA может давать искаженные результаты.
Расширением ARMA является модель авторегрессивной интегрированной скользящей средней (ARIMA), которая не предполагает стационарность, но все же предполагает, что данные практически не имеют сезонности. К счастью, сезонный вариант ARIMA (SARIMA) представляет собой статистическую модель, которая может работать с нестационарными данными и фиксировать некоторую сезонность.
Python предоставляет множество простых в использовании библиотек и инструментов для прогнозирования временных рядов. В частности, в библиотеке
Python есть инструменты для построения моделей ARMA, ARIMA и SARIMA всего несколькими строками кода. Поскольку все эти модели доступны в одной библиотеке, вы можете легко проводить множество экспериментов с использованием разных моделей в одном скрипте или блокноте.
Здесь мы рассмотрим, как построить модели ARMA, ARIMA и SARIMA для прогнозирования будущих цен на биткойны (BTC).
ПРОГНОЗИРОВАНИЕ ВРЕМЕННЫХ РЯДОВ
Прогнозирование временных рядов — это задача прогнозирования будущих значений на основе исторических данных. Примеры из разных отраслей включают прогнозирование погоды, объемов продаж и цен на акции. Совсем недавно он был применен для прогнозирования ценовых тенденций для криптовалют, таких как биткойн и эфириум. Учитывая распространенность приложений для прогнозирования временных рядов во многих различных областях, каждый специалист по данным должен иметь некоторые знания о доступных методах его выполнения.
ДРУГИЕ РАБОТЫ САДРАКА ПЬЕРА
Руководство по анализу временных рядов в Python
Чтение и отображение данных временных рядов BTC
Мы начнем с чтения исторических цен на BTC с помощью программы чтения данных Pandas. Давайте установим его с помощью простой команды pip в терминале:
pip install pandas-datareader
Давайте откроем скрипт Python и импортируем средство чтения данных из библиотеки Pandas:
import pandas_datareader.data as web
import datetime
Давайте также импортируем саму библиотеку Pandas и ослабим ограничения на отображение столбцов и строк:
import pandas as pd
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
Теперь мы можем импортировать библиотеку даты и времени, которая позволит нам определить даты начала и окончания для нашего извлечения данных:
import datetime
Теперь у нас есть все необходимое для извлечения данных временных рядов цен на биткойны, давайте соберем данные.
import pandas_datareader as web
btc = web.get_data_yahoo(['BTC-USD'], start=datetime.datetime(2018, 1, 1), end=datetime.datetime(2020, 12, 2))['Close']
print(btc.head())
Мы видим, что наш фрейм данных содержит много столбцов. Давайте рассмотрим, что означает каждый из этих столбцов.
- Дата: это индекс в нашем временном ряду, который указывает дату, связанную с ценой.
- Закрытие: последняя цена, по которой BTC был куплен в этот день.
- Открыто: первая цена, по которой BTC был куплен в этот день.
- High: Самая высокая цена, по которой BTC был куплен в этот день.
- Низкая: самая низкая цена, по которой BTC был куплен в этот день.
- Объем: общее количество сделок за день.
- Adj Close: цена закрытия с поправкой на дивиденды и дробление акций.
Мы будем использовать цену закрытия для наших моделей прогнозирования. В частности, мы будем использовать исторические цены закрытия BTC, чтобы предсказать будущие цены BTC.
Давайте запишем наши данные о цене закрытия BTC в файл csv. Таким образом, мы можем избежать повторного извлечения данных с помощью средства чтения данных Pandas.
btc.to_csv("btc.csv")
Теперь давайте прочитаем наш CSV-файл и отобразим первые пять строк:
btc = pd.read_csv("btc.csv")
print(btc.head())
Чтобы использовать модели, предоставляемые библиотекой статистики, нам нужно установить столбец даты в качестве индекса фрейма данных. Мы также должны отформатировать эту дату, используя метод to_datetime:
btc.index = pd.to_datetime(btc['Date'], format='%Y-%m-%d')
Давайте отобразим наш фрейм данных:
del btc['Date']
Давайте построим данные нашего временного ряда. Для этого импортируем библиотеки визуализации данных Seaborn и Matplotlib:
import matplotlib.pyplot as plt
import seaborn as sns
Давайте отформатируем нашу визуализацию с помощью Seaborn:
sns.set()
И пометьте ось Y и ось X, используя Matplotlib. Мы также повернем даты по оси x, чтобы их было легче читать:
plt.ylabel('BTC Price')
plt.xlabel('Date')
plt.xticks(rotation=45)
И, наконец, сгенерируйте наш график с помощью Matplotlib:
plt.plot(btc.index, btc['BTC-USD'], )
Теперь мы можем приступить к построению нашей первой модели временного ряда, авторегрессионной скользящей средней.
Разделение данных для обучения и тестирования
Важной частью построения модели является разделение наших данных для обучения и тестирования, что гарантирует, что вы создадите модель, которая может обобщаться за пределами обучающих данных, и что производительность и выходные данные будут статистически значимыми.
Мы разделим наши данные таким образом, чтобы все данные до ноября 2020 года служили обучающими данными, а все данные после 2020 года — данными тестирования:
train = btc[btc.index < pd.to_datetime("2020-11-01", format='%Y-%m-%d')]
test = btc[btc.index > pd.to_datetime("2020-11-01", format='%Y-%m-%d')]
plt.plot(train, color = "black")
plt.plot(test, color = "red")
plt.ylabel('BTC Price')
plt.xlabel('Date')
plt.xticks(rotation=45)
plt.title("Train/Test split for BTC Data")
plt.show()
Авторегрессионная скользящая средняя (ARMA)
Термин «авторегрессия» в ARMA означает, что модель использует прошлые значения для прогнозирования будущих. В частности, прогнозируемые значения представляют собой взвешенную линейную комбинацию прошлых значений. Этот тип метода регрессии похож на линейную регрессию, с той разницей, что входными данными здесь являются исторические значения.
Скользящее среднее относится к предсказаниям, представленным взвешенной линейной комбинацией условий белого шума, где белый шум является случайным сигналом. Идея заключается в том, что ARMA использует комбинацию прошлых значений и белого шума для прогнозирования будущих значений. Авторегрессия моделирует поведение участников рынка, например, покупку и продажу BTC. Белый шум моделирует шокирующие события, такие как войны, рецессии и политические события.
Мы можем определить модель ARMA, используя пакет SARIMAX:
from statsmodels.tsa.statespace.sarimax import SARIMAX
Давайте определим наш ввод:
y = train['BTC-USD']
А затем давайте определим нашу модель. Чтобы определить модель ARMA с классом SARIMAX, мы передаем параметры порядка (1, 0, 1):
ARMAmodel = SARIMAX(y, order = (1, 0, 1))
Затем мы можем подогнать нашу модель:
ARMAmodel = ARMAmodel.fit()
Сгенерируйте наши прогнозы:
y_pred = ARMAmodel.get_forecast(len(test.index))
y_pred_df = y_pred.conf_int(alpha = 0.05)
y_pred_df["Predictions"] = ARMAmodel.predict(start = y_pred_df.index[0], end = y_pred_df.index[-1])
y_pred_df.index = test.index
y_pred_out = y_pred_df["Predictions"]
И постройте результаты:
plt.plot(y_pred_out, color='green', label = 'Predictions')
plt.legend()
Мы также можем оценить производительность, используя среднеквадратичную ошибку:
import numpy as np
from sklearn.metrics import mean_squared_error
arma_rmse = np.sqrt(mean_squared_error(test["BTC-USD"].values, y_pred_df["Predictions"]))
print("RMSE: ",arma_rmse)
RMSE довольно высок, о чем мы могли догадаться, изучив сюжет. К сожалению, модель предсказывает снижение цены, когда цена на самом деле растет. Опять же, ARMA ограничена тем, что не подходит для нестационарных временных рядов и не учитывает сезонность. Давайте посмотрим, сможем ли мы улучшить производительность с помощью ARIMA.
Авторегрессионное интегрированное скользящее среднее (ARIMA)
Давайте импортируем пакет ARIMA из библиотеки статистики:
from statsmodels.tsa.arima.model import ARIMA
Задача ARIMA имеет три параметра. Первый параметр соответствует запаздыванию (прошлым значениям), второй соответствует разнице (это то, что делает нестационарные данные стационарными), а последний параметр соответствует белому шуму (для моделирования ударных событий).
Давайте определим модель ARIMA с параметрами порядка (2,2,2):
ARIMAmodel = ARIMA(y, order = (2, 2, 2))
ARIMAmodel = ARIMAmodel.fit()
y_pred = ARIMAmodel.get_forecast(len(test.index))
y_pred_df = y_pred.conf_int(alpha = 0.05)
y_pred_df["Predictions"] = ARIMAmodel.predict(start = y_pred_df.index[0], end = y_pred_df.index[-1])
y_pred_df.index = test.index
y_pred_out = y_pred_df["Predictions"]
plt.plot(y_pred_out, color='Yellow', label = 'ARIMA Predictions')
plt.legend()
import numpy as np
from sklearn.metrics import mean_squared_error
arma_rmse = np.sqrt(mean_squared_error(test["BTC-USD"].values, y_pred_df["Predictions"]))
print("RMSE: ",arma_rmse)
Мы видим, что прогнозы ARIMA (выделены желтым цветом) находятся выше прогнозов ARMA. Давайте попробуем увеличить параметр разности до ARIMA (2,3,2):
Мы видим, что это помогает зафиксировать возрастающее направление цены. Давайте еще поиграем с параметрами с помощью ARIMA(5,4,2):
И у нас есть RMSE 793, что лучше, чем у ARMA.
Наконец, давайте посмотрим, повысит ли производительность SARIMA, учитывающая сезонность.
Сезонная АРИМА (SARIMA)
Сезонный ARIMA фиксирует исторические значения, шоковые события и сезонность. Мы можем определить модель SARIMA, используя класс SARIMAX:
SARIMAXmodel = SARIMAX(y, order = (
5
, 4, 2), seasonal_order=(2,2,2,12))
SARIMAXmodel = SARIMAXmodel.fit()
y_pred = SARIMAXmodel.get_forecast(len(test.index))
y_pred_df = y_pred.conf_int(alpha = 0.05)
y_pred_df["Predictions"] = SARIMAXmodel.predict(start = y_pred_df.index[0], end = y_pred_df.index[-1])
y_pred_df.index = test.index
y_pred_out = y_pred_df["Predictions"]
plt.plot(y_pred_out, color='Blue', label = 'SARIMA Predictions')
plt.legend()
Внедрение прогнозирования временных рядов
Прогнозирование временных рядов — обычная задача, с которой сталкиваются многие команды специалистов по данным в разных отраслях. Хорошее знание общедоступных инструментов и методов позволит специалистам по данным быстро проводить новые эксперименты и получать результаты. Понимание значения параметров в каждой из этих моделей, таких как параметр запаздывания, разность, белый шум и сезонность, может заложить основу для построения простых моделей временных рядов. Это также обеспечивает хорошую основу для понимания некоторых более продвинутых доступных методов.
Способность точно и надежно прогнозировать будущие события — это ценный навык, который находит применение за пределами криптовалют и традиционных финансовых рынков. При этом любой специалист по данным, независимо от отрасли, в которой он работает, должен быть знаком с основами. Python предоставляет библиотеки, которые облегчают начинающим специалистам по обработке и анализу данных изучение того, как внедрять модели прогнозирования временных рядов.
#прогназирование #python #анализданных #программирование #биткоин #da