Сегодня поговорим про память в JVM.
Все знают про heap и stack. Начнем с них.
1) heap, она же куча. Хранит все создаваемые при работе JVM объекты. Очищается сборщиком мусора - garbage collector.
Делится на поколения: Eden, Survivor и Tenured (Old), между которыми перемещаются выжившие при сборке мусора объекты.
Кроме объектов начиная с Java 7 хранит также пул строк и другие пулы. Другие пулы - это пулы базовых типов-обверток над примитивами с фиксированным числом значений. Т.е. Boolean, Byte, Short, Integer, Long, Character. Цель использования пулов - уменьшение объема используемой памяти.
Раз пулы находятся в куче, то можно предположить, что неиспользуемые значения также удаляются сборщиком мусора. Так и есть.
Размер кучи можно регулировать параметрами: java -Xms256m -Xmx2048m
-Xms - начальный размер
-Xmx - максимальный размер.
По умолчанию максимальный размер для 64 разрядной системы при работе в сервером режиме равен 1/4 оперативной памяти, но не более 32 Гб.
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/parallel.html#default_heap_size
Посмотреть размер памяти у запущенного процесса:
java -XX:+PrintFlagsFinal <GC options> -version | grep MaxHeapSize.
Размер пулов тоже настраивается, пример для пула строк:
-XX:StringTableSize=4901
Если памяти не хватило - вылетает OutOfMemoryError: Java heap space
2) stack. Хранит стек вызовов всех Java потоков. В стеке хранятся локальные переменные и параметры примитивных типов, а также ссылки на объекты локальных переменных и параметров. Сами объекты при этом хранятся в куче.
Размер регулируется параметром -Xss. Как правило занимает немного, хотя в теории 100 потоков - это 100 Мб. Не стоит забывать, что кроме созданных в коде потоков есть служебные - потоки сборщика мусора и потоки JIT компилятора. Если памяти не хватило, а это как правило означает бесконечную рекурсию, то вылетает https://stackoverflow.com/questions/214741/what-is-a-stackoverflowerror
Также некоторые могут вспомнить про MetaSpace)
3) MetaSpace, он же Class metadata. Хранит метаданные классов, загружаемые classloaders. А классов в Java много - стандартная библиотека rt.jar, Spring, другие используемые библиотеки, ваши собственные классы, генерация классов при работе программы.
До Java 8 классы хранились в области с названием PermGenSpace. Возможно кто-то еще помнит, а может и сталкивается до сих пор с OutOfMemoryError: PermGen space. (((
Отличия MetaSpace от PermGenSpace - неограниченный размер по умолчанию и то, что с ним наконец-то научился работать сборщик мусора. Хотя размер по умолчанию не ограничен, регулировать его при желании можно: XX:MaxMetaspaceSize и XX:CompressedClassSpaceMax. При желании можно получить и OutOfMemoryError: Metaspace)))
Оффтоп: почему опции две? В зависимости от включения UseCompressedOops и UseCompressedClassesPointers класс попадает либо в обычный MetaSpace, либо в MetaSpace для классов с сжатыми указателями. MaxMetaspaceSize включает в себя CompressedClassSpaceMax.
Про сжатые указатели https://habr.com/ru/post/440166/
Теперь пойдут области, покрытые мраком)
4) GC - область памяти, используемая Garbage Collector при работе. Занимает 3-4% от кучи. Также размер зависит от типа сборщика мусора.
5) JIT\Code - как известно, компилятор у Java довольно тупой, а вот JVM - умная) При работе она анализирует использование классов, выполняет разные оптимизации, а также компилирует часто используемые классы в нативный код. Процесс называется Just In Time Compilation. Именно в этой области скомпилированный код и хранится.
Размер регулируется ключом: XX:ReservedCodeCacheSize. Если установить слишком маленький размер - будет постоянная рекомпиляция, начнет страдать производительность. Больше опций, регулирующих процесс тут - https://docs.oracle.com/javase/8/embedded/develop-apps-platforms/codecache.htm
6) JIT\Compiler - собственно память, занимаемая компилятором.
Ну и самые кишочки... )))
7) Internal - память под внутренние нужны JVM, не упомянутые выше.
В частности здесь выделяются Direct ByteBuffers - https://docs.oracle.com/javase/8/docs/api/java/nio/ByteBuffer.html В случае объекта в heap, содержащего данные файла, ОС вначале копирует данные в свой низкоуровневый буфер, а потом JVM копирует данные к себе, то в случае Direct ByteBuffers этого можно избежать. Используются во многих высоконагруженных системах, в частности Kafka.
Размер настраивается через -XX:MaxDirectMemorySize=N. Нехватку памяти можно определить по "OutOfMemoryError: Direct buffer memory".
Т.к. ByteBuffer - объект, то сборщик мусора также умеет убирать и данные, выделенные в Direct ByteBuffers. Правда с некоторой задержкой, т.к. сами данные все же находятся не в куче, и механизм уборки получается чуть более сложный.
Сравнение скорости работы прямого и heap буфера с комментарием о том, что это всего лишь один из возможных случаев использования: https://elizarov.livejournal.com/20381.html
А увидеть все эти области можно запустив java процесс со специальным ключом XX:NativeMemoryTracking и используя утилиту jcmd из состава JDK.
Cм. детали тут https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/tooldescr007.html
Запускать в ПРОДе с этой опцией нужно с осторожностью, overhead может быть 5-10%
Может показаться, что главное - это heap, все остальное по сравнению с ним - мелочи. Это не всегда так, см. исследование https://shipilev.net/jvm/anatomy-quarks/
Для иллюстрации вот как разместиться в памяти такой код:
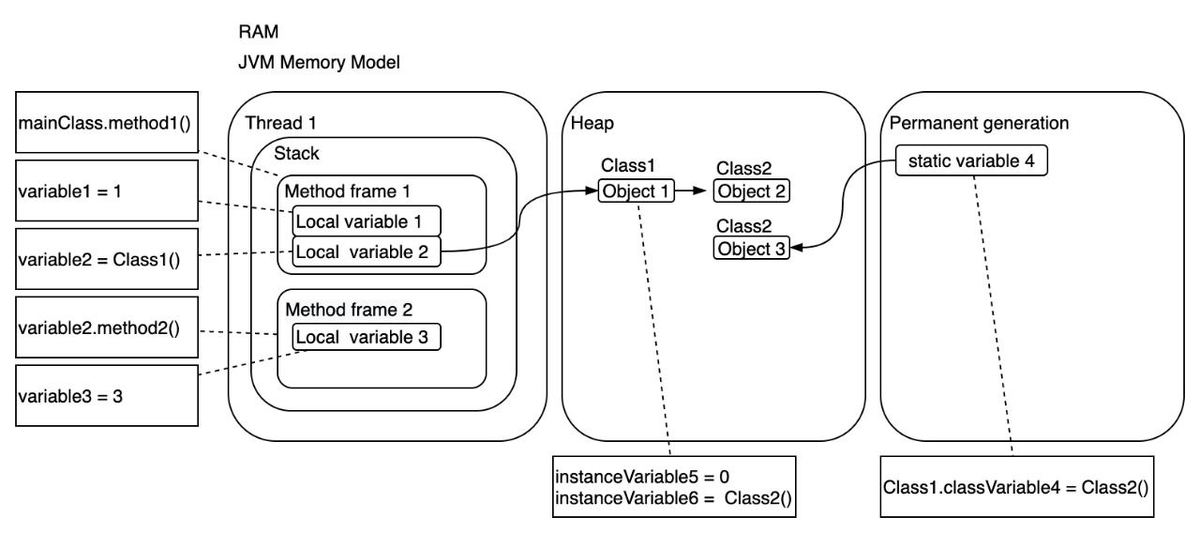
class MainClass {
void method1() { //<- main
int variable1 = 1;
Class1 variable2 = new Class1();
variable2.method2();
}
}
class Class1 {
static Class2 classVariable4 = new Class2();
int instanceVariable5 = 0;
Class2 instanceVariable6 = new Class2();
void method2() {
int variable3 = 3;
}
}
class Class2 { }
Взял отсюда https://stackoverflow.com/questions/362740/java-memory-model-can-someone-explain-it/362804
#java #interview_question