Эта статья посвящена особенностям тематического анализа в MAXQDA общедоступных полнотекстовых статей, скаченных в формате PDF. В процессе работы с ними я столкнулся проблемой, что не могу воспользоваться таким инструментом MAXQDA как комплексный поиск кодированных сегментов (“Complex Coding Query”) с функциями Следующий (“Followed by”) и Близость (“Near”). Соответственно, возможность визуализации близости расположения кодов в Браузере Кодовых Связей (“Code Relations Browser”) и на Карте Кода (“Code Map”) отсутствует полностью, а в Строке кода (“Codeline”) ограничена, поскольку для этого инструмента единицей анализа является страница, а не абзац.
Несмотря на то, что формат PDF стал стандартом научного электронного документооборота во всем мире, но у исследователей до сих пор регулярно возникает проблема корректного извлечения текста из таких файлов. Выявлены и другие проблемы, например получение полной и последовательной структуры из документа со сложным, нестандартным макетом страницы.
Все это связано с тем, что формат PDF предназначен не для редактирования текста, а для макетирования статьи при ее подготовке к печати. Документы PDF отличаются от текстовых тем, что в них не предусмотрены ни строки, ни абзацы. Дополнительные сложности возникают из-за большого разнообразия возможных макетов и стилей, используемых в научных публикациях. В этой связи некоторые методики MAXQDA, учитывающие абзац как единицу текста, не могут использоваться для интеллектуального анализа документов PDF.
Однако разработчики MAXQDA и здесь позаботились о пользователе, предоставив возможность автоматической декомпозиции и преобразования файлов PDF. Для этого нужно нажать правой кнопкой мыши на один или несколько выделенных PDF файлов в окне “Система документов” и в контекстном меню выбрать функцию “Вставить текст из PDF как новый документ”. Новый текст появится в “Системе документов” непосредственно под выбранным документом, но при этом изображения и форматирование, в том числе и табличное, в нем будут проигнорированы.
Допустим, что вы нуждаетесь в том, чтобы сохранить и иллюстрации к тексту, и таблицы, в которых обычно содержится множество полезной структурированной информации. В данном случае можно порекомендовать программу ABBYY FineReader 15, позволяющую не только извлекать текст, но и сохранять в нем без изменений мультимодальный контент, например, изображения и таблицы. Конвертация в формат Word возможна в 4 режимах оформления: Простой текст, Форматированный текст, Точная копия и Редактируемая копия. Логично предположить, что каждый из способов имеет различную степень пригодности для решения нашей задачи, но в сети Интернет я не нашел на этот счет каких-либо рекомендаций или инструкций. Таким образом, есть несколько вариантов конвертации PDF в DOCX, но неизвестно какой из них наиболее предпочтительный.
Для определения самых оптимальных методов извлечения нами проведена небольшая исследовательская работа, состоявшая из трех частей. Вначале мы сравнили тождественность текстов, извлеченных системой MAXQDA, и конвертированных ABBYY FineReader 15 с различными режимами оформления. Цель второго этапа исследования - изучение качества извлечения текста со сложной структурой страницы и на основе сопоставления качественных результатов выявить наиболее перспективные методы. Задачей третьего раздела работы было выявление зависимости полноты и точности комплексного поиска кодированных сегментов (“Complex Coding Query”) в зависимости от способа извлечения текста из PDF файла.
В качестве исходного материала взята полнотекстовая статья “Role of fascial connectivity in musculoskeletal dysfunctions: A narrative review”, скаченная с сайта Национальной медицинской библиотеки США (NLM). Нами специально выбран текст со сложным макетом оформления: разделение на 2 колонки, наличие внедренных рисунков и таблиц, а также обозначение страниц верхними и нижними колонтитулами. При извлечении подобного текста высока вероятность нарушения порядка строк и/или параграфов, особенно в таких сложных областях как перенос абзаца на следующую колонку или страницу, а также его разрыв колонтитулами, встроенными таблицами или рисунками.
В первой части эксперимента текстовые документы для анализа в MAXQDA 2022 были получены путем конвертации файла (“Role of fascial connectivity (pdf)”) с применением собственного инструмента, а также специальной программы ABBYY FineReader 15. Файлы Word, полученные последовательным применением различных типов оформления конвертации в ABBYY FineReader 15, были сохранены в отдельной папке. Их названия отражали использованный тип оформления: “Role of fascial connectivity (простой текст FR)”, “Role of fascial connectivity (редактируемая копия FR)”, “Role of fascial connectivity (точная копия FR)”, “Role of fascial connectivity (форматированный текст FR)”. Для корректного сравнения между разными программными продуктами при конвертации ABBYY FineReader 15 опции “Сохранять колонтитулы и номера страниц”, “Сохранять деление на страницы“, “Сохранять переносы и деление на строки” и “Сохранять номера строк” в настройках были активированы. Подготовка завершена импортом полученных файлов Word в ранее созданный проект MAXQDA.
Для определения тождественности качества распознания текстов мы использовали автономный модуль статистики MAXQDA Stats. Итоги предварительного анализа представлены в таблице № 1.
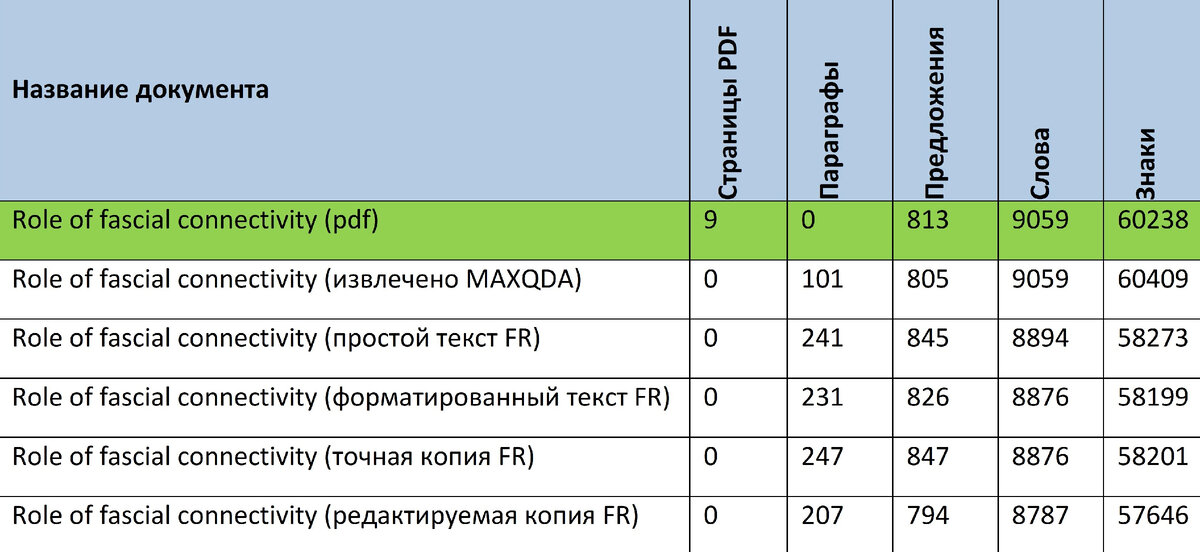
Взглянув на таблицу, можно обнаружить, что, как и обещали разработчики MAXQDA, в текстовых файлах нет разделения на страницы, а в PDF - отсутствуют абзацы. Второй вывод - извлеченные тексты по анализируемым критериям иногда значительно различаются. Выводы, в принципе, очевидны, но все-таки требовали математического подтверждения.
При более пристальном рассмотрении таблицы № 1 можно заметить, что в каждом сравниваемом документе количество абзацев, предложений, слов и знаков отличается друг от друга и от исходного текста разнонаправленно и неравномерно. Чтобы иметь возможность сравнить их между собой и использовать при расчёте схожести объектов абсолютные величины выбранных семантических информационных единиц были переведены в относительные к значениям показателей, полученных при анализе в MAXQDA Stats исходного PDF файла. Важно отметить, что абзацы в нем были предварительно подсчитаны вручную.
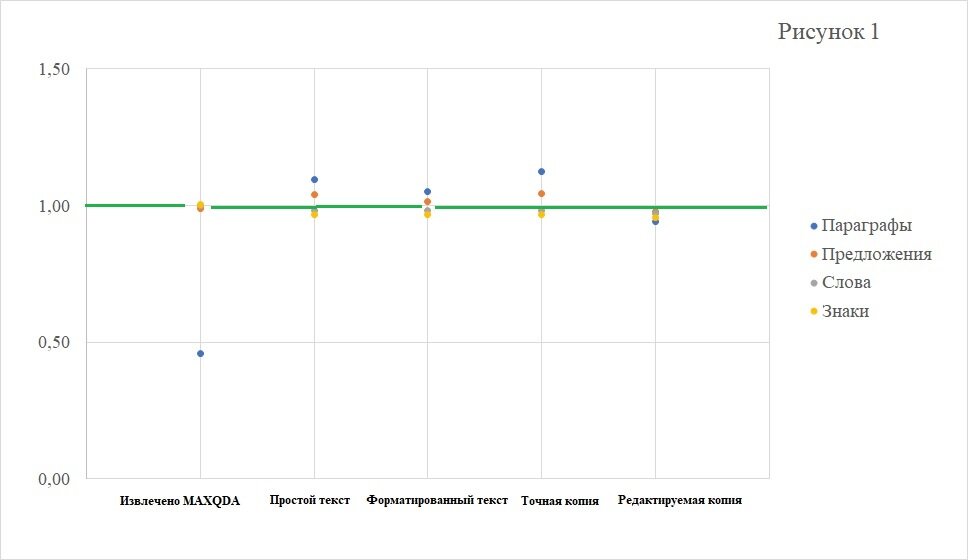
На Рисунке 1 можно видеть, что относительные значения, представленные в виде точек разного цвета, наиболее близко расположены друг к другу и к эталонным значениям (отмечены зеленной линией) на участке диаграммы соответствующему Редактируемая копия (Editable copy). Из этого наблюдения можно сделать вывод, текст извлеченный ABBYY FineReader 15 с применением данного типа оформления, наиболее схож с оригиналом.
На втором этапе было решено проверить возможности изучаемых средств извлечения текста из файла pdf со сложной структурой страницы. Важно отметить, что в настройках ABBYY FineReader 15 опции “Сохранять колонтитулы и номера страниц”, “Сохранять деление на страницы“, “Сохранять переносы и деление на строки” и “Сохранять номера строк” уже были деактивированы.
Первое задание заключалось в оценке сохранения порядка следования слов и предложений в абзаце, разделенном между двумя колонками. Как видно на Рисунке 2 первый абзац оригинального текста, начинающийся со слов “Musculoskeletal pain and….”, не только расположен на двух колонках, но и разделен пристраничной цитатой и сведениями для переписки с автором. Слова “Musculoskeletal” и “patients” выделены маркерами желтого и зеленого цвета для третьей части эксперимента. Теперь последовательно опишем результаты конвертации выбранного нами фрагмента текста.
При извлечении средствами MAXQDA (Extracting MAXQDA) 2 отдельных абзаца в разных колонках, но расположенные на одном уровне, а также данные об авторе объединяются в один. При этом пристраничная цитата, информация из верхнего колонтитула распознаны как отдельные абзацы (Рисунок 3). Все это однозначно снизит точность и полноту комплексного поиска кодированных сегментов (“Complex Coding Query”) с функциями Следующий (“Next”) и Близость (“Near”) с заданными пределами обнаружения. Также имеются неточности в виде сохранившегося знака переноса в слове “development” и соединение слов “of” и “musculoskeletal”.
Использование типа оформления Простой текст (Plain text). Абзац, расположенный на двух колонках, распознан как два отдельных, к тому же разделенных строками со сведениями об авторе, также распознанных как отдельные абзацы (Рисунок 4). Следующий абзац и пристраничная цитата выделены как отдельные абзацы. Также остался знак переноса в слове “development”.
Применение ABBYY FineReader 15 с типом оформления Форматированный текст (Formatted text). Порядок абзацев и их содержание не нарушено (Рисунок 5). Сохранились сведения о публикации, также разделенные на отдельные абзацы.
Извлечение текста в ABBYY FineReader 15 с типом оформления Точная копия (Exact copy) ничем не отличается от предыдущего варианта, кроме того, что в слове “development” удален символ переноса (Рисунок 6).
Оптимальным вариантом оказалось извлечение текста с типом оформления Редактируемая копия (Editable copy). Порядок абзацев и их содержание полностью соответствуют оригиналу. Переносы и сведения о публикации и авторах, а также пристраничные ссылки корректно удалены (Рисунок 7).
Теперь аналогичным образом проверим работу программного обеспечения на таком сложном участке как абзац, разделенный страницами и колонтитулами. Как видно на Рисунке 8 первый абзац оригинального текста, начинающийся со слов “Manual therapists, use several….”, расположен на двух страницах, а также разделен сведениями для переписки с автором и верхним колонтитулом. Слова “Musculoskeletal” и “understand” выделены маркерами желтого и зеленого цвета для следующей части эксперимента.
При извлечении средствами MAXQDA (Extracting MAXQDA) абзац, расположенный на двух разных страницах, распознан как отдельные абзацы. Данные об авторе, пристраничная цитата и информация из верхнего колонтитула выделены в отдельные абзацы, при этом их порядок расположения на странице нарушен. Абзацы в разных колонках, но на одном уровне макета страницы объединены в один (Рисунок 9).
Результаты извлечения текста в ABBYY FineReader 15 с типом оформления Простой текст (Plain text) и Точная копия (Exact copy) практически идентичны предыдущему (Рисунок 10, 11).
Как и в первом задании извлечение текста в ABBYY FineReader 15 с типом оформления Форматированный текст (Formatted text) не изменило порядок абзацев и их содержание (Рисунок 12). Сохранились сведения о публикации, также разделенные на отдельные абзацы.
В этом задании оптимальным вариантом также оказался выбор типа оформления Редактируемая копия (Editable copy), что продемонстрирована на Рисунке 13.
Третьим этапом данной исследовательской работы являлось сравнение полноты и точности поиска в зависимости от выбора способа извлечения текста. Для сравнения были использованы результаты комплексного поиска кодированных сегментов (“Complex Coding Query”) с функциями Следующий (“Followed by”) и Близость (“Near”), ограниченными параметрами расстояния в 0 и 1 абзац. Для тестирования по первому заданию была выбрана пара “Musculoskeletal” и “patients”, а по второму - “Musculoskeletal” и “understand”. Подсчет вручную количества сегментов, которые должны быть обнаружены при комплексном поиске сегментов с определенными условиями, дал нам эталонные значения выполнения этих транзакций. Результаты тестирования представлены в таблице № 2, в которой регистрировали только те методы извлечения текста, в которых было полное совпадение с эталоном.
Данный раздел эксперимента позволил определить, что, используя ABBYY FineReader 15 с типом оформления Редактируемая копия (Editable copy), результат конвертации PDF файла значительно ближе к оригиналу по порядку чтения и дает наилучшее совпадение итогов комплексного поиска кодированных сегментов с функциями Следующий (“Next”) и Близость (“Near”).
Подводя итоги этого небольшого исследования можно с опредленной долей уверенности утверждать, что для конвертации PDF файлов, содержащих необходимые таблицы и рисунки, лучше всего выбрать тип оформления Редактируемая копия (Editable copy), а в настройках ABBYY FineReader 15 деактивировать опции “Сохранять колонтитулы и номера страниц”, “Сохранять деление на страницы“, “Сохранять переносы и деление на строки” и “Сохранять номера строк”.
Безусловно, эта работа имеет слабые места. Поскольку для исследования использован только один PDF файл, то сложно утверждать о достоверности выводов и возможности их экстраполяции на прочие макеты оформления статей. Также возможно выбрана не оптимальная методика оценки результата или есть погрешности при планировании эксперимента.
Но я надеюсь на вашу конструктивную критику и доброжелательные комментарии)).