Рассмотрим вопрос на примере датасета о прогнозе выживаемости пассажиров "Титаника". Загрузим набор данных:
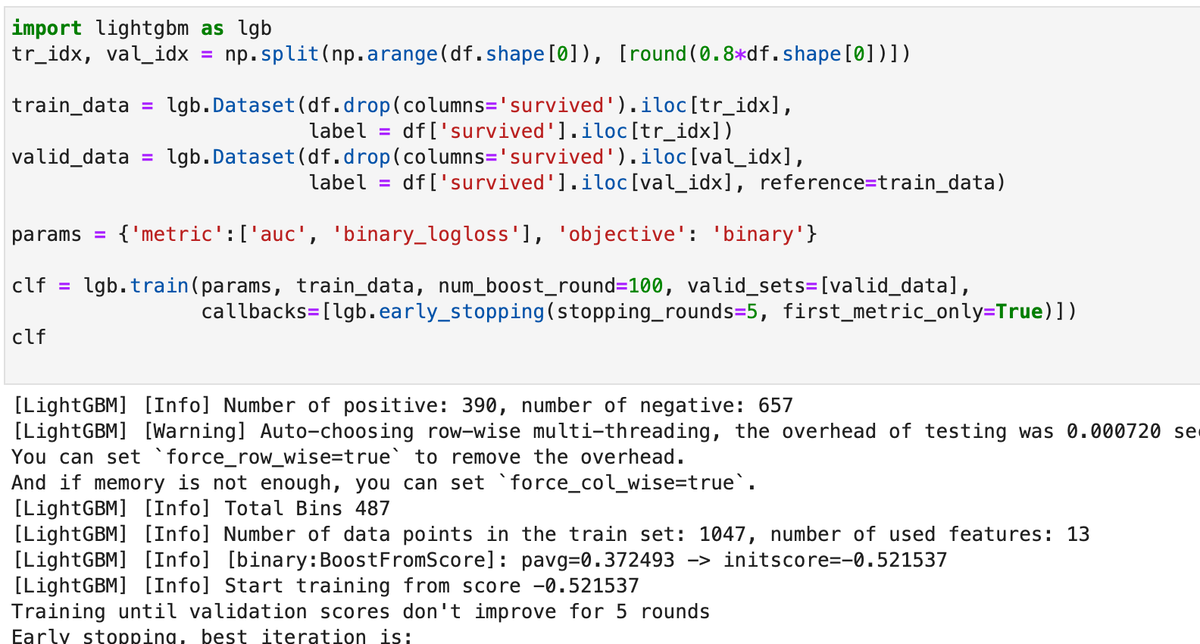
Сначала вспомним, как осуществить ранний останов без кросс-валидации. Для этого следует сформировать два датасета (Dataset) и вызвать метод train с параметрами, включающими измеряемые метрики, тренировочный и валидационный датасеты (valid_sets), функцию раннего останова (добавляется в список в параметре callbacks) с указанием количества итераций, в течение которых отслеживается факт улучшения метрики (stopping_rounds). Если задано несколько валидационных метрик, то параметр first_metric_only=True в callback функции указывает, что выбор итерации будет происходит не с учетом их всех, а только первой:
Лучшая итерация и значения метрик хранятся в атрибутах best_iteration, best_score объекта lightgbm.basic.Booster:
Для кросс-валидации используется функция cv, которая принимает аналогичные параметры, только вместо двух датасетов один (так как сама осуществляет разбиение) и стратегию разбиений (количество фолдов или их индексы), дополнительные параметры здесь:
Лучшую итерацию можно получить из атрибута best_iteration CVBooster:
Задав номер лучшей итерации, проведем кросс-валидацию вручную и сверим качество:
Обратите внимание на параметр reference=data_all при формировании train_data. Он нужен для того, чтобы бинаризация переменных при поиске оптимальной границы осуществлялась по всему массиву данных. Именно так происходит в функции cv. В противном случае бинаризация идет только по тренировочному датасету, и результаты совпадать не будут.



















