Совсем недавно ко мне торжественно вернулась в печатном издании книга, которую приобретал еще в 2011 году под названием «Алгоритмы на C++» за авторством Роберта Седжвика. Торжественно вернулась она из отчего дома после многолетнего ожидания на полке, а случилось это ожидание потому, что в том году мой воспаленный ум первокурсника был ещё не в состоянии оценить по достоинству такой богатый материал и без того учебных курсов было много. А «руки то загребущие»...
Книга без всяких сомнений замечательная, вроде как не настолько распиарена как талмуд Кормена. Сейчас она судя по всему известна более широко в универсальном издании без привязки к конкретному языку программирования, но мне и плюсы очень симпатичны.

Первая глава книги, как полагается, является затравкой для всех еще-не-до-конца-заинтересованных и в качестве «подопытной» задачки автор предлагает так называемую задачу связности (dynamic connectivity problem).
Суть задачи такова: на вход программе подаются пары целых (если настаиваете - неотрицательных) чисел (p,q), каждое число пары идентифицирует некоторый объект (читай — вершину графа), а сама пара (p,q) обозначает наличие связи между двумя объектами p и q (читай — ребро графа). Отношение связности считается транзитивным и симметричным, то есть если p связано с q, то верно что q связано с p, и если к тому же q связано с m, то p так же связано с m (если сильно хочется большей математической строгости то очевидно что p и сам с собой связан, так что у нас точно все в порядке в задачке =)). На выходе алгоритм должен оставлять только те пары значений (ребра), которые не могут быть получены по транзитивности из предыдущего (ранее выведенного) набора значений. Например:
Вход: (1,2), (1,3), (2,4), (4,3), (5,2), (5,4)
Выход: (1,2), (1,3), (2,4), (5,2)
Иными словами необходимо динамически отсекать избыточные ребра, то есть выводить только остовное дерево.
В качестве первого (самого неоптимального) подхода в книге предлагается так называемый метод быстрого поиска. Идея подхода проста, но симпатична - будем считать что у каждой вершины имеется метка, причем метка это номер какой-то ещё вершины в графе (изначально вершина сама себе является меткой). После того как на входе появляется пара вершин, необходимо проверить как они помечены, и если их отметки отличаются будем так преобразовывать пометки всех известных нам к данному моменту вершин, чтобы они отражали информацию о наличии связности (все вершины в одной компоненте связности должны быть помечены одинаково). То есть метка будет по существу являться идентификатором компоненты связности.
Я совершу страшное преступление по отношению к первоисточнику и приведу имплементацию данного метода не на C++, а на Python. Будем считать что значения пары на вход подаются в текстовом файле, каждая новая входная пара записана в новой строке и отделена пробелами. Выводить ответ код будет в консоль в том же формате. Код демонстрационный и на лаконичность не претендует:
Прежде чем двинуться дальше предлагаю на секунду задуматься чем этот подход хорош, а чем не очень (собственно говоря, ровно то же самое предлагает сделать и Седжвик).
Бросается в глаза что в случае, если новая пара на входе является избыточной мы мгновенно от неё откажемся - именно это происходит в строках 10 и 11. Это само по себе довольно здорово, но мы платим за такую роскошь большую цену — нам приходится обходить весь словарь ids для поддержания возможности быстрого поиска (строки 13-15).
Если совсем строго формализовать вышесказанное, то мы можем разделить алгоритм на два этапа - поиск и объединение. Несложно понять что поиск это именно этап проверки входной пары на «избыточность», а объединение это возня для поддержания актуальной индексации компонент связности. Выражаясь в таких терминах алгоритм быстрого поиска выполняет не менее MxN операций для решения задачи связности при наличии N объектов, для которых требуется выполнение M операций объединения. Это совсем несложное утверждение и я настоятельно рекомендую попытаться самостоятельно его обосновать (если не получается — бегом читать книжку).
В этой связи возникает непреодолимое желание ускорить операцию объединения ценой стоимости операции поиска. Давайте попробуем это сделать при помощи хранения «представителя» для каждой вершины, причем самый главный «представитель» будет всегда в самом конце цепочки переходов. Торжественно назовем этот подход алгоритмом быстрого объединения и взглянем на листинг:
Теперь операция объединения не требует просмотра всего словаря ids, нам нужно только пробежаться по цепочке представителей для каждой вершины во входной паре — это выглядит намного дешевле (и в среднем — действительно так), но несложно понять что бывают ужасающие случаи неэффективности данного алгоритма (подумайте какие, достаточно предъявить «плохую» входную последовательность пар).
Уверен что вы быстро заметите «корень зла» данного подхода — если представлять информацию о представителях в виде дерева (т.е. проводить ребро от всякой вершины до её представителя после обработки каждой входной пары), некоторые из получаемых деревьев будут жутко несбалансированны. В таком случае нет ничего проще чем ввести свою балансировку, например по весу поддерева, где весом является количество вершин в поддереве. Лучше один раз увидеть код чем тысячу раз его пересказывать, назовем данный метод методом взвешенного быстрого объединения:
Теперь все ясно, такой код будет стараться цеплять более легкие поддеревья к более тяжелым, а это гарантирует нам балансировку. В качестве еще одного упражнения, хоть и уже существенно более сложного чем предыдущие, предлагаю подумать почему верно следующее утверждение (логарифм подразумевается по основанию двойки):
В ходе работы алгоритма взвешенного быстрого объединения для определения наличия связи между парой входных вершин при условии что всего вершин N штук, необходимо перейти не более чем по logN указателям.
Верность этого утверждения следует из того, что операция объединения сохраняет оценку глубины от вершины до корня в дереве представителей на всяком шаге. Если доказательство утверждения никак не поддается — снова радостно отсылаю вас к Седжвику.
Казалось бы что может быть лучше, но лучше может быть очень много чего. В книге представлено несколько модификаций основанных на сжатии путей в дереве представителей, которые амортизируют время обработки поисковых запросов ценой некоторой реструктуризации дерева. Это очень любопытные оптимизации и до них несложно дойти самостоятельно — попробуйте подумать о том, можно ли отказаться от длинных цепочек в дереве представителей если в конечном счете нас интересует только финальная вершина в цепочке? Чего нам будет стоить всегда стараться делать дерево не просто сбалансированным, а по настоящему плоским?
Для большей ясности ниже я попытался визуализировать дерево представителей для трех представленных выше алгоритмов когда на вход подается следующая последовательность пар: (1,2), (2,3), (4,5), (5,6), (3,4), (6,7), (7,8).
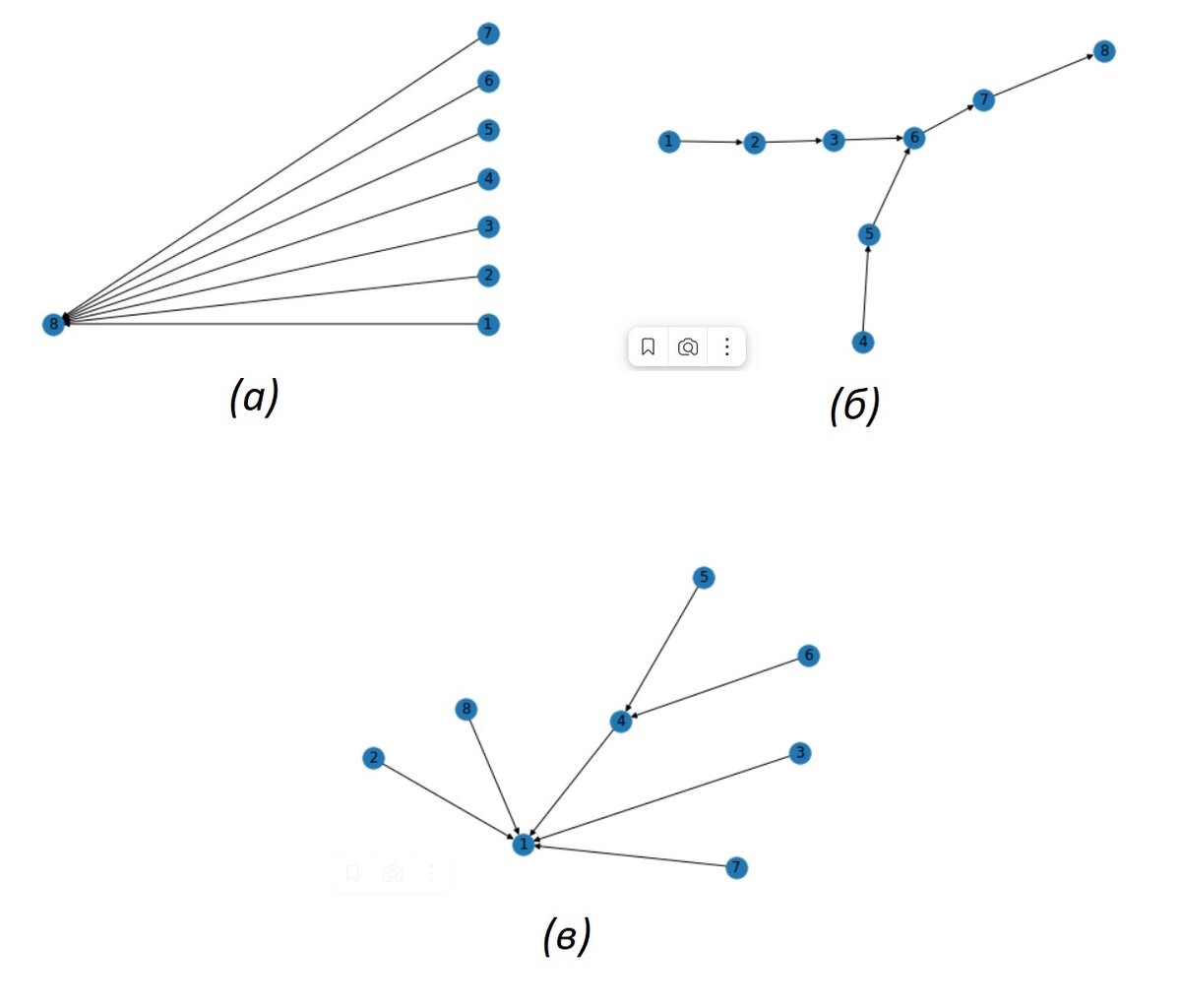
Интерес к этой задаче у меня разгорелся когда я наткнулся на упражнение к первой главе, которое оказалось очень полезным для глубокого понимания алгоритма взвешенного быстрого объединения. Упражнение сформулировано так:
Вычислите среднее расстояние от узла до корня в худшем случае в дереве из 2^n узлов, построенном алгоритмом взвешенного быстрого объединения.
Если читать невнимательно то может показаться что речь о той же задаче что упомянута ранее, однако акцент нужно расставить на слове «среднее». Максимальное расстояние мы теперь-то уже знаем — если вершин 2^n то максимальное обещают не более n шагов.
Эта задачка только выглядит сложной, на самом деле она довольна проста. Попробуйте решить её самостоятельно, далее я приведу свой ход размышлений и ответ, который у меня получился.
В худшем случае мы всегда объединяем поддеревья одного веса, именно тогда формируется самая глубокая цепочка. Рассмотрите для примера случай n=3 и последовательность входных пар: (1,2), (3,4), (5,6), (7,8), (1,3), (5,7), (1,5). Можно визуализировать эту цепочку по проходам. Первым проходом формируется 4 цепочки глубины 1 (после входной пары (7,8)), то есть у половины вершин глубина окажется нулевой, а у другой половины увеличится на единицу. После этого на втором проходе формируется два поддерева, в каждом из которых имеется цепочка глубины 2 (после пары (5,7)). Эти два поддерева формируются склейкой пар цепочек глубины 1, при этом происходит ровно тот же процесс, у половины вершин глубина увеличивается на единицу, а у другой половины остается неизменной. На последнем проходе формируется цепочка глубины 3, после входной пары (1,5). Здесь аналогично половина вершин глубину не изменила, а половина нарастила глубину на 1. Проходов у нас n штук (поскольку log(2^n)), на каждом проходе суммарная длина цепочек увеличивается на 0.5 * (2^n) = 2^(n-1). Изначально глубина нулевая. Среднее значение:
(n*2^(n-1))/(2^n) = n/2
В приведенном выше размышлении за кадром остается обоснование почему это худший случай, предлагаю Вам об этом подумать (или обнаружить у меня ошибку и написать об этом в комментарии).
Подписывайтесь на канал, спасибо что стоически дочитали до конца!
Успехов и гармонии! (и баланса, как у деревьев, а может даже лучше)