Представьте, что ваш руководитель дал задание очень быстро написать обзор современных методов лечения и диагностики плантарного (подошвенного) фасциита. Я хочу предложить выполнить это поручение путем автокодирования множества текстовых документов ключевыми словами авторов статей. Этот способ будет особенно полезен тем, кто хотя бы поверхностно знаком с исследуемой темой, но в данный момент не собирается вникать в проблему глубже, чем нужно для решения текущей задачи. При этом вы должны понимать, что повышенная скорость анализа неизбежно приведет к некоторой потере качества)).
Для скрининг-анализа лучше выбрать англоязычные статьи из известных информационных платформ, например Science Direct, а для автоматической обработки и классификации полученных данных использовать библиографический менеджер Mendeley. Это обусловлено аккуратным заполнением метаданных статей и универсальностью методов извлечения из них библиографической информации.
Итак, приступим.
1. Создаем отдельную папку в Mendeley, назовем ее “Plantar fasciitis”. В задачи этой статьи не входит объяснение принципов работы в Mendeley, поскольку мы уверенны, что у вас имеется огромный опыт работы с данной программой для управления библиографической информацией. Если это не так, то более подробное описание возможностей библиографического менеджера компании Elsevier вы найдете здесь.
2. Далее ищем в Science Direct статьи, имеющие отношение к теме “Plantar fasciitis”, для чего (1.) в поисковое поле вводим – Plantar fasciitis, без использования групповых символов и операторов. Однако при других, более сложных запросах, их применение является обоснованным.
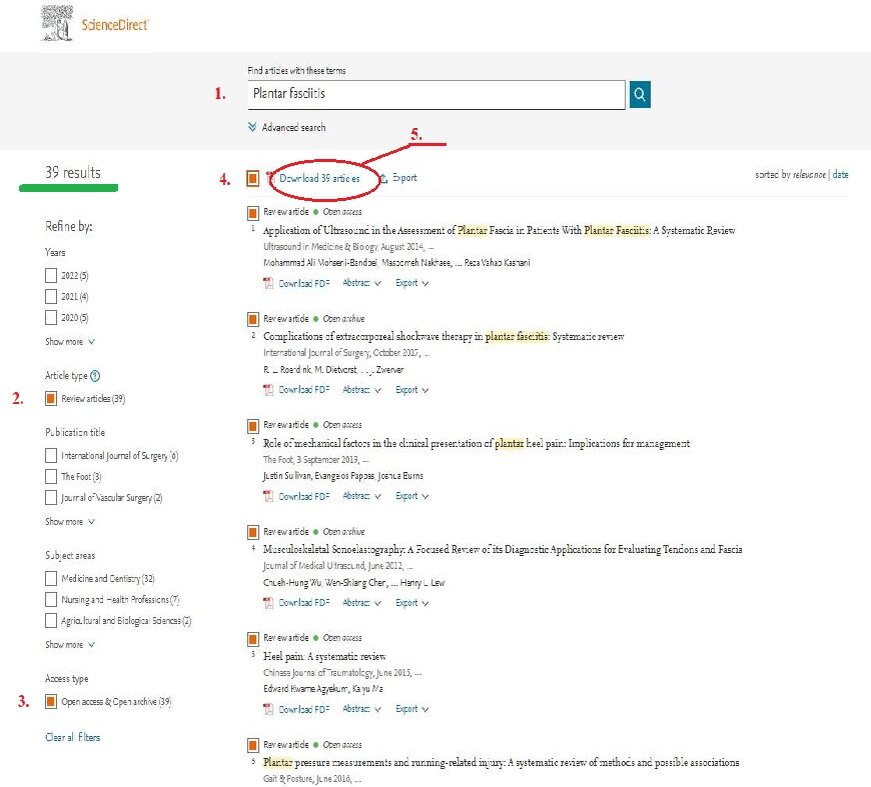
Поскольку наша цель – это получить максимум новой информации в конспективном виде и изучить текущий дискурс по предмету исследования, то мы ограничиваем вывод результатов (2.) обзорными статьями с доступом к (3.) полному тексту публикации. В результате найдено 39 источников, соответствующих нашим условиям.
Затем выбираем (4.) все записи, отображенные на странице, и экспортируем их (5.) в виде архива в локальную папку для загрузки.
3. После предварительной распаковки архива, скаченного из базы данных Science Direct, добавляем файлы в Mendeley, в папку “Plantar fasciitis”.
4. По окончании импорта обязательно проверяем соответствие названия и содержания рефератов статей теме вашей работы. Иногда случаются ошибки машинного поиска, которые приводят к попаданию в анализируемый пул ненужных файлов. Также настоятельно рекомендуем проверить полноту информации в библиографических данных источника.
5. Закончив валидацию подборки публикаций, выделяем все записи в папке “Plantar fasciitis” и активируем строчку Export, находящуюся во вкладке File. Далее выполняем экспорт статей из Mendeley в файл My Collection ris. Для удобства дальнейшего поиска и использования название файла лучше изменить на Plantar fasciitis.
6. После формирования файла запускаем MAXQDA и создаем проект «Plantar fasciitis». Далее во вкладке Импорт нажимаем на иконку Библиографические данные. Следуя инструкции в появившимся контекстом меню, выбираем из папки загрузки Plantar fasciitis.ris и отмечаем все предлагаемые опции. Более подробно этот процесс, в том числе и для других программ, таких как Citavi, Endnote и Zotero, описан в соответствующем разделе онлайн руководства MAXQDA.
7. Результат импорта библиографических данных в проект MAXQDA изображен на рисунке. Мы видим в окне «Список документов» две группы документов «Библиографические данные» и «Библиографические данные - приложения». При раскрытии первой группы мы увидим списка рефератов статей, расположенных в алфавитном порядке. Во второй группе находятся соответствующие им PDF файлы с полным текстом статей.
В окне «Список кодов» в системе кодов сгенерирован раздел «Библиографические данные» с двумя подкодами «RIS» и «Ключевые слова». Субкод «RIS» содержит все теги RIS, используемые в файле импорта в качестве подкодов, например «Title» или «Abstract». Субкод «Ключевые слова» в качестве подкодов содержит все ключевые слова, указанные авторами в литературных ссылках.
Хотелось бы обратить ваше внимание на то, что браузере документа (смотри дополнительное окно в зеленой рамке) видно, что авторские ключевые слова связаны только с файлом, при этом, в его структуре нет ни одного автоматически закодированного сегмента. Это причина того, что количественный и качественный анализ возможен только на основании частот встречаемости кода в выборке документов. Оценить близость, содержание и пересечение кодов в статьях и их библиографических данных невозможно. К сожалению, в MAXQDA нет (или я его не нашел) собственного инструмента для автокодирования сегментов текста ключевыми словами, которые были предложены авторами публикации.
8. Для скринингового количественного и качественного анализ содержимого множества PDF файлов в группе документов «Библиографические данные - приложения» одновременно, а также визуализация результатов этого процесса требуется создание словаря на основе авторских ключевых слов. Эта задача может быть решена в несколько этапов.
На первом этапе необходимо выполнить следующую последовательность действий:
1. В окне «Список кодов» активировать код «Ключевые слова» с субкодами
2. Во вкладке MAXDictio нажать левой кнопкой мыши на иконку «Словарь»
3. В открывшемся окне создать новый словарь и переименовать его в «Ключевые слова»
4. Нажав специальную иконку вставить коды из окна «Список кодов»,
В результате будет создан словарь с категориями названными ключевыми авторскими словами. На рисунке видно, что область «Условия поиска» не содержит терминов, референтных выбранной категории «Biomechanics», что и не позволяет осуществить поиск и кодирование по ключевым словам.
9. Вторым этапом создания словаря для автокодирования сегментов текста авторскими ключевыми словами выполняем в программе Microsoft Excel. Для продолжения работы экспортируем словарь «Ключевые слова», нажав одновременно Ctrl-E. Ниже на рисунке представлен полученный Excel файл «Ключевые слова», на котором мы видим, что в столбце «Категория» имеется длинная строка, отражающая последовательные записи в древовидной структуре категорий созданного словаря.
В столбце «Ключевое слово» отсутствуют элементы для поиска сегментов текста, относящихся к соответствующей категории словаря. Столбцы «Целое слово», «Различать между заглавными/строчными буквами», «Начало слова», «Категория активирована» и «Ключевое слово активировано» можно использовать для включения и выключения доступных параметров поиска с помощью созданного нами словаря, где “1” означает “да”, а “0” - “нет”.
Корректно работающий словарь требует гармонизации порядка и формы записей в таблице с форматом, принятым для MAXDictio. Для этого необходимо выполнить следующие шаги:
• Удалить из каждой строчки в столбце «Категория» следующую запись – «БИБЛИОГРАФИЧЕСКИЕ ДАННЫЕ\КЛЮЧЕВЫЕ СЛОВА\». Для автоматизации этого действия можно воспользоваться сервисом Excel «Найти и заменить». Обратите внимание, что строка «Заменить на…» не заполняется.
• Выполнить коррекцию ошибочных записей. Например, в строке 28 из-за пропуска пробела после запятой пять абсолютно различных терминов были записаны как целое слово. Мы разделили эту запись на 5 независимых строк.
• Скопировать все записи со второй ячейки и до последней включительно в буфер обмена и вставить их соседние, находящиеся в столбце «Ключевое слово».
• В столбцах «Целое слово», «Различать между заглавными/строчными буквами», «Начало слова» определить значение ячеек равным 0 по умолчанию, а в столбцах «Категория активирована» и «Ключевое слово активировано» - равным 1. Важно: формат ячеек должен быть определен как числовой без десятичных знаков.
В результате получилась следующая таблица.
В дальнейшем, если захотите повысить точность и адекватность автокодирования со словарем, вы можете потратить время и изменить данные в столбце «Ключевое слово» сократив словосочетания до одного слова или общеизвестного буквенного сокращения.
10. На завершающем этапе в окне «Словарь» импортируем файл «Ключевые слова» как новый словарь проекта «Plantar fasciitis». На рисунке мы видим, что в области «Условия поиска» появился элемент «Biomechanics», параметры обнаружения которого не активированы.
Теперь можно достаточно просто изменить уровень и активность категорий, ввести дополнительные элементы поиска или модифицировать его параметры. Для более точного кодирования сегментов, имеющих отношение к определенной категории, рекомендуется сократить поисковый элемент до корня и активировать параметр «Начало слова». Это также отсечет участки текста, где поисковый элемент является частью корня, а также слова с префиксом, иногда резко меняющего их изначальный смысл.
11. Теперь приступаем к стандартному автокодированию текстов так замечательно описанному в онлайн руководстве MAXQDA. В этой статье хотелось бы только продемонстрировать результаты автокодирования документов с применением созданного нами на основе авторских ключевых слов словаря «Ключевые слова». На нижерасположенном рисунке вы можете заметить, что в участке текста, закодированном как «AB_Abstract» при импорте файла Plantar fasciitis.ris в MAXQDA, появился сегмент, закодированный как «Biomechanics».
При просмотре текста PDF файла в браузере документа можно обнаружить сегменты, автоматически закодированные авторскими словами.
Надеюсь, что этот «лайфхак» упростит и ускорит применение всех инструментов, разработанных талантливыми сотрудниками VERBI GmbH, для анализа больших данных в медицине.