Название данной статьи отсылает к моей предыдущей статье о списках, поэтому я настоятельно рекомендую изучить её, прежде чем переходить к этой (ссылка на статью: https://clck.ru/rKVAA).
Это всё определённо неспроста. Всё дело в том, что строки — это не тип, а структура данных, некоторыми аспектами похожая на списки.
Напомню о том, что списки — это коллекция элементов разных типов. В отличие от списков, строки — это коллекция символов. Списки — это изменяемая коллекция, т.к. мы запросто можем переназначить любой его элемент на какой-либо другой. Посмотрим на пример:
s = [1,2,3,4,5]
s[0] = 6
print(s) # [6,2,3,4,5]
Со строками такой «фокус» не прокатит:
s = 'Hello World!'
s[0] = 'K'
Если мы выполним этот код, то увидим ошибку:
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
s[0] = 'K'
TypeError: 'str' object does not support item assignment
В данной ошибке говорится о том, что строка не поддерживает изменение. Из вышеописанного исходит вывод о том, что строки — это НЕИЗМЕНЯЕМЫЕ последовательности.
Индексы.
Строка, как и любая другая последовательность, поддерживает отрицательные и неотрицательные индексы.
s = 'Mama, just kill a man'
print(s[0]) # 'M'
print(s[6]) # 'j'
print(s[-1]) # 'n'
char = s[0]
print(char) # 'M'
Стоит заметить, что присваивание какой-то переменной значение по индексу или среза — нормальная практика для языка Python.
Срезы.
Если мы можем использовать индексы в строках, то закономерно можем использовать и срезы, что несомненно удобно, когда нам, например, нужно вырезать какое-то слово из строки.
Синтаксис среза строки — string[start:stop:step]
s = 'Mama, just kill a man'
mama = s[0:4]
print(mama) # 'Mama'
Сложение строк. Умножение строк на константу.
Строки могут складываться между собой, образуя новую строку. Такая операция называется конкатенацией.
s1 = 'Hello '
s2 = 'World!'
s3 = s1 + s2
print(s3) # 'Hello World!'
Помимо этого допускается умножение строки на константу:
s = 'Hello '
print(s*3) # 'Hello Hello Hello '
Строковые литералы.
Давайте рассмотрим какую-нибудь строку, в которой будем использовать обратный слеш (не будет вдаваться в нюансы, например, нам просто захотелось использовать обратный слеш в своей строке).
s = 'example str\ning' — например, вот такую строку
Давайте попробуем вывести такую строку на экран.
print(s)
И что же мы видим? Мы видим не то, что ожидали:
example str
ing
Мы видим, что строка после двух символов «\n» почему-то перенеслась.
Данный пример иллюстрирует использование так называемых строковых литералов на примере строки s = 'example str\ning', в которой строковый литерал \n переводит строку.
Существует много литералов, полная таблица перед вами:
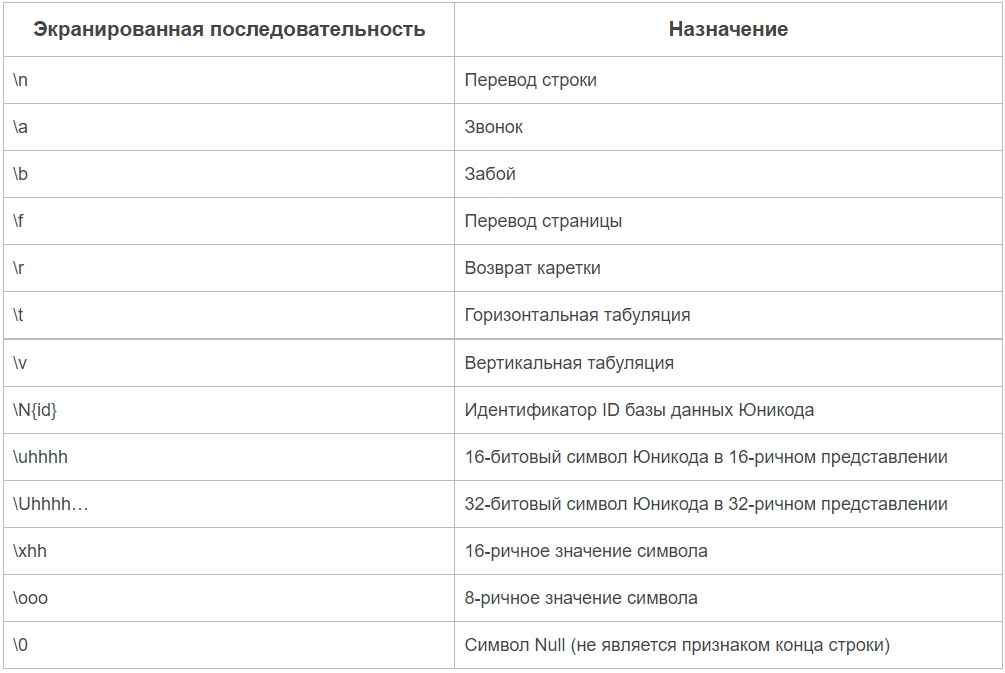
Кроме того, существуют так называемые строки в апострофах и кавычках. Как вам известно, мы можем записывать строки или в кавычках («string») или в апострофах ('string'). Зачем в Python существует 2 вида записи строк? Всё очень просто. Для того, чтобы можно было использовать кавычки и апострофы в самой строке. Давайте посмотрим на примере и тогда всё станет ясно.
s1 = 'Название статьи — «Строки (str)»'
print(s1) # 'Название статьи — «Строки (str)»' — кавычки сохраняются
s2 = «He's a good boy»
print(s1) # 'He's a good boy' — апостроф сохраняется
Мы рассмотрим 2 самых распространённых литерала \n и \t по той самой причине, что прочие будут использоваться вами довольно редко.
Строковый литерал \n используется для перевода строки, как в примере выше, а строковый литерал \t используется для табуляции, т.е. добавлении между символами или в начале строки 4-х пробелов.
s = '123\t45'
print(s) # 123(4 пробела)45
Попробуйте сами выполнить этот код и убедитесь в том, что \t добавляет 4 пробела.
Однако, если нам уж ооочень хочется использовать обратный слеш, с которого, к вашему сведению, не может заканчиваться никакая строка, то мы в праве отменить всякое экранирование (так называется процесс обработки строковых литералов при исполнении программы) следующим образом:
s = r'123\t45'
print(s) # '123\t45'
Такие строки называются «сырыми», поэтому, если вам для каких-то целей необходимо отменить экранирование, то в ваша воля на использование r в любом регистре перед вашей строкой.
Методы строк.
- len(s) — длина строки
s = '12345'
print(len(s)) # 5
2. s.find(str,start,end) — поиск подстроки str в строке s, возвращает индекс первого вхождения подстроки, иначе возвращает -1. start и end ограничивают диапазон поиска подстроки.
s = '12345'
print(s.find('3')) # 2
3. s.rfind(str,start,end) — поиск подстроки str в строке s, возвращает индекс последнего вхождения подстроки, иначе возвращает -1. start и end ограничивают диапазон поиска подстроки.
s = '123451'
print(s.rfind('1')) # 5
4. s.index(str, start,end) — возвращает индекс первого вхождения подстроки str в строку s, иначе вызывает ValueError
s = '12345'
print(s.index('3')) # 2
5. s.rindex(str, start,end) — возвращает индекс последнего вхождения подстроки str в строку s, иначе вызывает ValueError
s = '123451'
print(s.rindex('1')) # 5
6. s.replace(шаблон, замена, maxcount) — замена шаблона на замену в строке s, maxcount ограничивает число замен.
s = '123123123'
print(s.replace('123', '456')) # '456456456'
s = '123123123'
print(s.replace('123', '456',1)) # '456123123'
7. s.split(char) — разбиение строки s по символу char
s = 'sym sym sym'
l = s.split(' ') — разбиение по символу «пробел»
print(l) # ['sym', 'sym', 'sym']
8. s.isdigit() — проверяет состоит ли строка из цифр, возвращает значение True или False (тип boolean), то есть истина или ложь.
s = '123'
print(s.isdigit()) # True
s = '123a'
print(s.isdigit()) # False
9. s.isalpha() — проверяет состоит ли строка из букв. Служебные символы — не буквы
s = 'fdgh'
print(s.isalpha()) # True
s = '123ff'
print(s.isalpha()) # False
s = 'string!@#$%^'
print(s.isalpha()) # False
10. s.isalnum() — проверяет состоит ли строка из букв или цифр.
s = '123aaa'
print(s.alnum()) # True
s = '123'
print(s.alnum()) # True
s = 'aaa'
print(s.alnum()) # True
s = '123aaa!@#$%'
print(s.alnum()) # False
11. s.islower() — проверяет состоит ли строка из символов нижнего регистра.
s = 'hello world!'
print(s.islower()) # True
s = 'Hello World!'
print(s.islower()) # False
s = 'HELLO WORLD' #
print(s.islower()) # False
12. s.isupper() — проверяет состоит ли строка из символов верхнего регистра.
s = 'hello world!'
print(s.isupper()) # False
s = 'Hello World!'
print(s.islower()) # False
s = 'HELLO WORLD' #
print(s.islower()) # True
13. s.startswith(str) — проверяет начинается ли строка s с подстроки str
s = 'Hello'
print(s.startswith('He')) # True
14. s.istitle() — проверяет начинаются ли слова в строке с заглавной буквы.
s = 'Hi, My Name Is Gavriiil'
print(s.istitle()) # True
s = 'Hi, My Name is Gavriiil'
print(s.istitle()) # False
15. s.upper() — преобразует строку к верхнему регистру.
s = 'hello'
print(s.upper()) # HELLO
16. s.lower() — преобразует строку к верхнему регистру.
s = 'HELLO'
print(s.lower()) # hello
17. s.endswith(str) — проверяет оканчивается ли строка s с подстроки str.
s = 'My name is Max'
print(s.endswith('Max')) # True
18. s.join(l) — «собирает» строку s из списка l
l = [ 'h', 'e', 'l', 'l', 'o' ]
s = ''
print(s.join(l)) # 'hello'
19. s.capitalize() — переводит первый символ строки в верхний регистр, а остальные — в нижний.
s = 'hELLO WORLD'
print(s.capitalize()) # 'Hello world'
20. s.count(str, start, end) — возвращает количество полных вхождений подстроки str в строку s. start и end ограничивают диапазон поиска.
s = 'h3333h'
print(s.count('3')) # 4
21. s.swapcase() — переводит символы нижнего регистра в верхний, а верхнего — в нижний.
s = 'Hello World!'
print(s.swapcase()) # 'hELLO wORLD!'
22. s.title() — переводит первую букву каждого слова строки s в верхний регистр, остальные — в нижний
s = 'hI, mY nAME iS aBRACHAM'
print(s.title()) # 'Hi, My Name Is Abracham'