
Рассказываем, как мы строили наше S3-хранилище, как оно работает сейчас, и что мы из этого вынесли.
Как было устроено хранилище VK
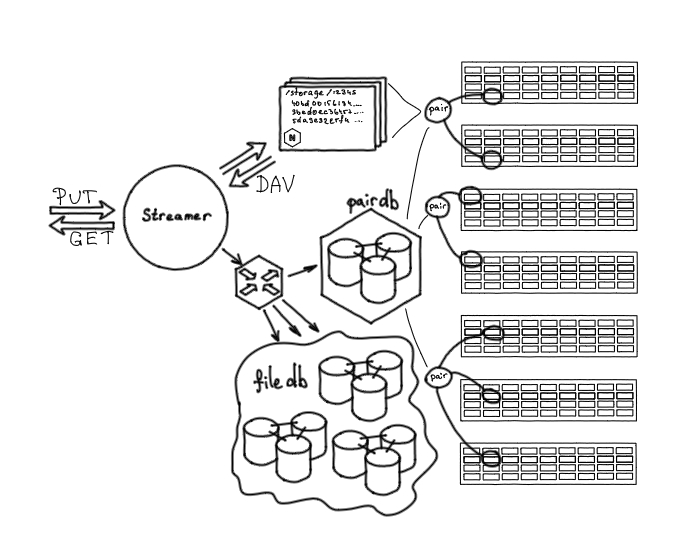
Хранилище облака VK стало основой для нашего S3-хранилища. Оно состоит из нескольких storage-серверов с дисками. Эти диски объединены в «пары» (pair), а все пары хранятся в PairDB — приложении на Tarantool, отвечающем за состояние всех дисков системы. База FileDB помогает узнать, на какой именно паре находится файл. А сервис Nylon отвечает за работу с базами данных. Последний сервис, Streamer, помогает помещать контент в хранилище.
Что нужно было добавить
Для реализации протокола S3 было необходимо:
- организовать хранение метаданных;
- обеспечить доступ к объектам через HTTP;
- сгруппировать объекты в коллекции — бакеты;
- реализовать HTTP-S3 Endpoint.
Также мы хотели предусмотреть возможность дальнейшего линейного роста сервиса.
Первые компоненты
Вначале мы добавили S3-демона — стандартный S3 API Amazon с поддержкой работы по XML для метаданных, необходимый для передачи контента.
Для терминации SSL, балансировки нагрузки и для логики на Lua перед сервисом мы разместили Nginx. А для хранения метаданных S3 мы использовали Tarantool.
Объектная модель хранения
Вспомним, как работает S3.
Пользователи создают бакеты — коллекции объектов. В рамках бакетов они могут создавать объекты, которые состоят из массива двоичных данных (blob). К атрибутам объектов относятся URL (имя), ACL (список управления доступом) и т.п.
Схема данных при этом может выглядеть так: есть проекты, им принадлежат бакеты, а им принадлежат объекты. Для загрузки составных объектов есть две вспомогательные таблицы: uploads и chunks. Также у проектов есть учетные данные для доступа и биллинг (его мы реализовали на Tarantool).
Доработки S3-хранилища для выхода в продакшн
Для выхода в прод не хватало нескольких моментов.
Во-первых, необходимо было организовать достаточно производительную систему рейт-лимитов, чтобы не перегружать какой-либо участок системы при пиковых нагрузках. Для этого мы снова использовали Tarantool.
Во-вторых, для работы под большими нагрузками необходим был кэш. S3 — горячее хранилище, поэтому важно было оптимизировать доступ к контенту при помощи локального кэша. В итоге мы реализовали многослойный кеш при помощи nginx, локальных, SSD и RAM-дисков без использования Tarantool.
Доработки в бою
Хранилище уже было в бою, но на старте мы упустили из виду фейловер и масштабирование.
Чтобы обеспечить активный фейловер, мы поставили Tarantool на место оригинальной базы. Он стал прокси-роутером запросов за метаданными.
После этого мы занялись разработкой кастомной функции шардирования, а также реализовали решардинг.
Работа с SSL-сертификатами
Другая часть системы — работа с SSL-сертификатами. За балансировку и терминацию SSL у нас отвечает не обычный Nginx, а а OpenResty, то есть Nginx с поддержкой LuaJIT.
Мы смогли научить наш Nginx отдавать произвольные сертификаты. Чтобы отдавать сертификаты динамически, мы воспользовались расширением ssl_certificate_by_lua. А как хранилище для сертификатов мы снова использовали Tarantool.
Наши выводы
По итогам работы над нашим S3-хранилищем, мы сделали несколько важных выводов:
- на реализацию шардинга стоит потратиться на старте;
- cо всеми базами лучше работать через балансировщики;
- лучше сразу установить все инструменты для автофейловера;
- биллинг удобнее реализовывать как отдельный сервис.



















