«Все впечатляющие достижения глубокого обучения сводятся к подгонке оптимизации».
Жемчужина Иудеи
Машинное обучение в его наиболее упрощенной форме иногда называют прославленной подгонкой оптимизации. В некотором смысле это правда. Модели машинного обучения обычно основаны на принципах конвергенции; подгонка данных к модели. Приведет ли этот подход к ОИИ, все еще остается спорным вопросом. Однако на данный момент наилучшим решением являются глубокие нейронные сети, и они используют методы оптимизации для достижения цели.
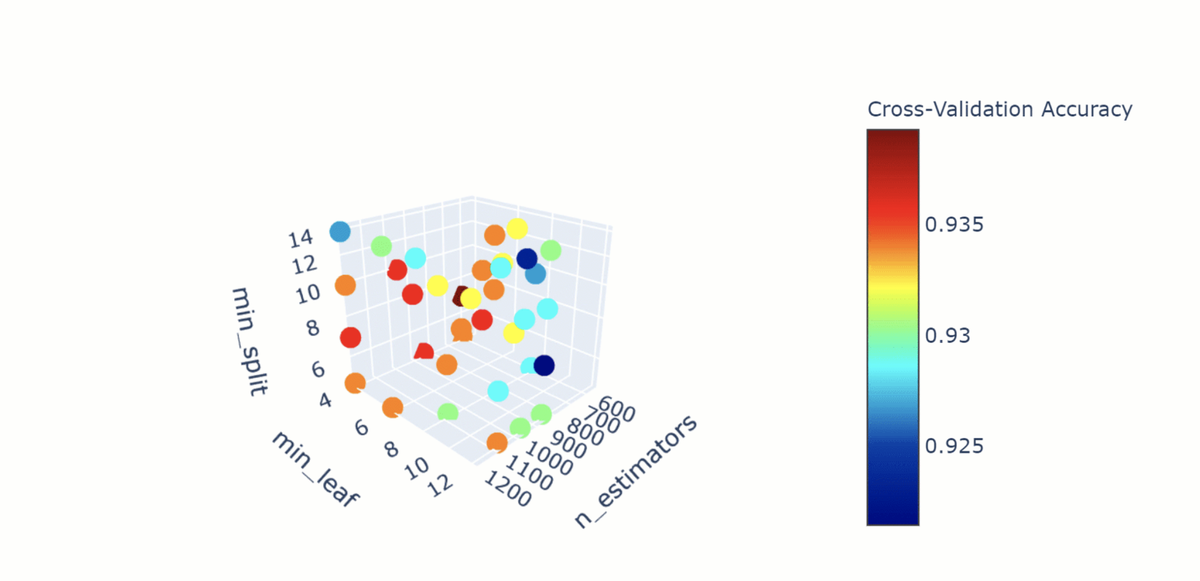
Фундаментальные методы оптимизации обычно делятся на методы оптимизации первого порядка, высокого порядка и методы оптимизации без производных. Обычно встречаются методы, относящиеся к категории оптимизации первого порядка, такие как градиентный спуск и его разновидности.
Согласно обширному обзору методов оптимизации, проведенному Shiliang et al., вот несколько лучших методов, с которыми можно часто сталкиваться в своем путешествии по машинному обучению:
Градиентный спуск
Метод градиентного спуска является наиболее популярным методом оптимизации. Идея этого метода заключается в итеративном обновлении переменных в (противоположном) направлении градиентов целевой функции. При каждом обновлении этот метод направляет модель на поиск цели и постепенно сходится к оптимальному значению целевой функции.
Стохастический градиентный спуск
Стохастический градиентный спуск (SGD) был предложен для решения вычислительной сложности, связанной с каждой итерацией для крупномасштабных данных. Уравнение задается как:
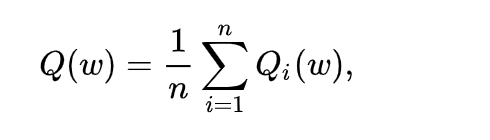
Получение значений и их итеративная корректировка на основе различных параметров для уменьшения функции потерь называется обратным распространением.
В этом методе одна выборка случайным образом используется для обновления градиента за итерацию вместо прямого вычисления точного значения градиента. Стохастический градиент является объективной оценкой реального градиента. Этот метод оптимизации сокращает время обновления при работе с большим количеством выборок и устраняет определенную вычислительную избыточность. Подробнее здесь.
Метод адаптивной скорости обучения
Скорость обучения является одним из ключевых гиперпараметров, которые подвергаются оптимизации. Скорость обучения определяет, будет ли модель пропускать определенные части данных. Если скорость обучения высока, модель может упустить более тонкие аспекты данных. Если он низкий, то он желателен для реальных приложений. Скорость обучения оказывает большое влияние на SGD. Установка правильного значения скорости обучения может быть сложной задачей. К этой настройке автоматически были предложены адаптивные методы.
Адаптивные варианты SGD широко используются в DNN. Такие методы, как AdaDelta, RMSProp, Adam, используют экспоненциальное усреднение для обеспечения эффективных обновлений и упрощения вычислений.
Adagrad: веса с высоким градиентом будут иметь низкую скорость обучения и наоборот
RMSprop: настраивает метод Adagrad таким образом, чтобы он уменьшал монотонно уменьшающуюся скорость обучения.
Adam почти похож на RMS Prop, но с импульсом
Метод множителей переменного направления (ADMM) является еще одной альтернативой стохастическому градиентному спуску (SGD).
Разница между методами градиентного спуска и AdaGrad заключается в том, что скорость обучения больше не является фиксированной. Он вычисляется с использованием всех исторических градиентов, накопленных до последней итерации. Подробнее здесь.
Метод сопряженных градиентов
Метод сопряженных градиентов (CG) используется для решения крупномасштабных линейных систем уравнений и задач нелинейной оптимизации. Методы первого порядка имеют медленную скорость сходимости. Принимая во внимание, что методы второго порядка являются ресурсоемкими. Оптимизация сопряженного градиента — это промежуточный алгоритм, который сочетает в себе преимущества информации первого порядка, обеспечивая скорость сходимости методов высокого порядка.
Узнайте больше о градиентных методах здесь.
Оптимизация без производных
Для некоторых задач оптимизации всегда можно подойти через градиент, потому что производная целевой функции может не существовать или ее нелегко вычислить. Вот где на сцену выходит оптимизация без производных. Он использует эвристический алгоритм, который выбирает методы, которые уже хорошо зарекомендовали себя, а не систематически выводит решения. Классическая арифметика симуляции отжига, генетические алгоритмы и оптимизация роя частиц - вот лишь несколько таких примеров.
Оптимизация нулевого порядка
Оптимизация нулевого порядка была введена недавно для устранения недостатков оптимизации без производных. Методы оптимизации без производных трудно масштабировать для задач большого размера и страдают от отсутствия анализа скорости сходимости.
Преимущества нулевого порядка :
Простота реализации с небольшой модификацией широко используемых алгоритмов на основе градиента
Вычислительно эффективные приближения к производным, когда их трудно вычислить
Сопоставимые скорости сходимости с алгоритмами первого порядка.
Мета-оптимизатор популярен в метаобучении. Цель метаобучения — добиться быстрого обучения, что, в свою очередь, делает градиентный спуск более точным при оптимизации. Сам процесс оптимизации можно рассматривать как проблему обучения для изучения прогнозируемого градиента, а не определенного алгоритма градиентного спуска. Из-за сходства между обновлением градиента при обратном распространении и обновлением состояния ячейки LSTM часто используется в качестве метаоптимизатора.
Принимая во внимание, что алгоритм метаобучения, не зависит от модели (MAML), является еще одним методом, который изучает параметры моделей, подвергнутых методам градиентного спуска, которые включают классификацию, регрессию и обучение с подкреплением. Основная идея модельно-независимого алгоритма состоит в том, чтобы начать несколько задач одновременно, а затем получить направление синтетического градиента разных задач, чтобы изучить общую базовую модель.
Это лишь немногие из часто используемых методов оптимизации. Помимо этих, есть и другие методы, которые можно найти в этом исследовании.
Тем не менее, проблема оптимизации для глубокого обучения на этом не заканчивается, потому что не все проблемы подпадают под выпуклую оптимизацию. Невыпуклая оптимизация является одной из трудностей в задаче оптимизации.
Один из подходов состоит в том, чтобы преобразовать невыпуклую оптимизацию в задачу выпуклой оптимизации, а затем использовать метод выпуклой оптимизации. Другой подход заключается в использовании какого-либо специального метода оптимизации, такого как проекционный градиентный спуск, попеременная минимизация, алгоритм максимизации ожидания, стохастическая оптимизация и ее варианты.
#machinelearning #artificialintelligence #ai #datascience #python #programming #technology #deeplearning #coding #bigdata