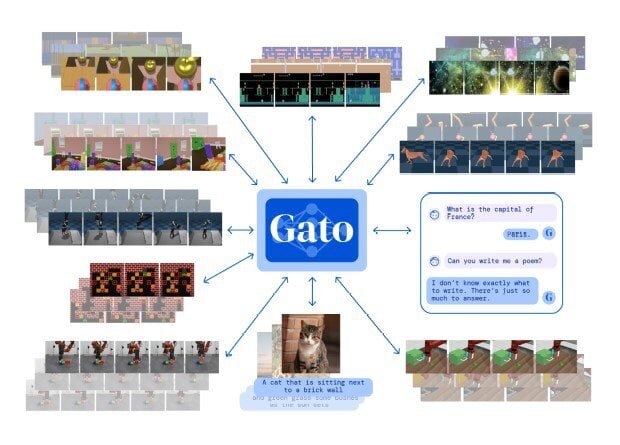
Исследователи из DeepMind разработали новую мультимодальную нейросеть Gato, использующую архитектуру Transformer для решения задач разного типа.
Поскольку Transformer разрабатывали для языковых задач, эта архитектура работает с текстовыми токенами. Соответственно, для работы с разными данными Gato превращает их (данные) в токены. Текст токенизируется стандартным способом, при котором в словах выделяются подслова и кодируются числом от 0 до 32 000. Изображения разбиваются на квадраты (16 на 16 квадратов), а пиксели в них кодируются от −1 до 1. Затем эти квадраты подаются в модель построчно. Дискретные значения превращаются в числа от 0 до 1024, а непрерывные дискретизируются и превращаются в число или набор чисел от 32 000 до 33 024. При необходимости токены также могут разбиваться разделительными токенами.
После токенизации входящих данных каждый токен превращается в эмбеддинг (по сути, сжатое векторное представление тех же данных) двумя способами: для изображений квадраты пропускаются через сверточную нейросеть типа ResNet, а для остальных данных они подбираются через выученную таблицу поиска (так как любой токен представляет собой целое число в ограниченном диапазоне).
Исследователи использовали 24 датасета с данными разных типов и с их помощью обучили модель выполнять 604 задачи. Фактически, DeepMind продемонстрировала подход, обратный принятому: вместо создания узкоспециализированной модели, решающей конкретную задачу или набор смежных задач лучше других, разработчики создали универсальную модель, которая решает самые сложные задачи, но не очень качественно.



















