В этом блоге рассматривается процесс экспериментирования с гиперпараметрами, алгоритмами машинного обучения и другими параметрами графовых нейронных сетей. В этом посте мы рассказываем о первых двух этапах нашей цепочки экспериментов. Наборы данных графов, на основе которых мы делаем выводы, взяты из Open Graph Benchmark (OGB). Возможно вам это будет полезно, мы предоставили краткий обзор GNNs и краткий обзор OGB.
Цели экспериментов и типы моделей
Мы оптимизировали два популярных варианта GNN, чтобы:
- Улучшить производительность в задачах предсказания лидеров OGB.
- Минимизировать затраты на обучения (время и количество эпох)
- Проанализировать поведение мини-графа в сравнении с обучением полного графа в течение итераций модели.
- Продемонстрировать общий процесс итеративного эксперимента над гиперпараметрами.
Мы разработали собственные варианты реализации OGB для двух популярных GNN-фреймворков: GraphSAGE и Relational Graph Convolutional Network (RGCN). Затем мы разработали и применили итерационный экспериментальный подход для настройки гиперпараметров, в котором мы стремимся получить качественную модель, требующую минимального времени на обучение.
Выборка является важным аспектом обучения GNN, и процесс настройки гиперпараметров отличается от обучения других типов нейронных сетей. В частности, применения пакетной нормализация могут привести к экспоненциальному росту количества данных, которые сеть должна обработать за итерацию.
Чтобы узнать больше о важности стратегий работы с выборкой для GNN, ознакомьтесь с некоторыми из этих ресурсов:
Теперь мы попытаемся построить наши модели в соответствии с целями экспериментов, описанными выше.
Итеративное экспериментирование
Наш процесс экспериментов HPO (гиперпараметрическая оптимизация) состоит из трех этапов для каждого типа модели как для мини-партии, так и для полной выборки графиков. Три фазы включают в себя:
- Производительность: Найти наилучшую производительность?
- Эффективность: Как быстро мы можем найти качественную модель?
- Доверие: Как мы выбираем самые качественные модели?
На первом этапе используется единая метрика SigOpt Experiment, которая оптимизирует потери при валидации как для мини-партийной, так и для полной графовой реализации. Эта фаза поиска наилучшей производительность путем настройки GraphSAGE и RCGN.
На втором этапе определяются две метрики для измерения того, насколько быстро мы завершаем обучение модели: (a) время, затраченное на обучение GNN, и (b) общее количество эпох для обучения GNN. Мы также используем наши знания, полученные на первом этапе, для разработки эксперимента по оптимизации с ограничениями. Мы минимизируем метрики при условии, что потери при валидации не превышают целевой показатель качества.
На третьем этапе мы выбираем качественные модели с умеренным расстоянием между ними в пространстве гиперпараметров. Мы проводим одно и то же обучение с 10 различными случайными выборками в соответствии с рекомендациями OGB. Мы также используем GNNExplainer для анализа закономерностей между моделями.
Как запустить код
Код находится в этом репозитории. Чтобы запустить код, вам нужно выполнить следующие действия:
- Клонировать репозиторий
- Создать виртуальное окружение и запустить его
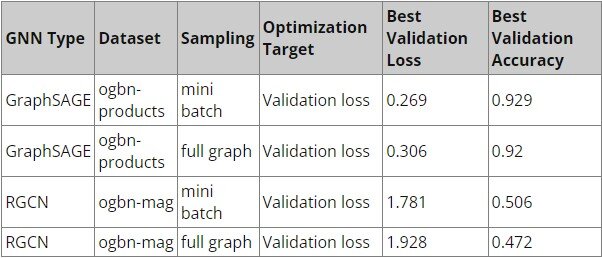
Результаты этапа 1: разработка экспериментов для максимальной точности
На первом этапе эксперимента настройка гиперпараметров проводилась на кластере Xeon с использованием Jenkins для тренировок модели на узлах. Для среды выполнения использовались контейнеры Docker. Всего было проведено четыре потока экспериментов, по одному для каждой строки в таблице.
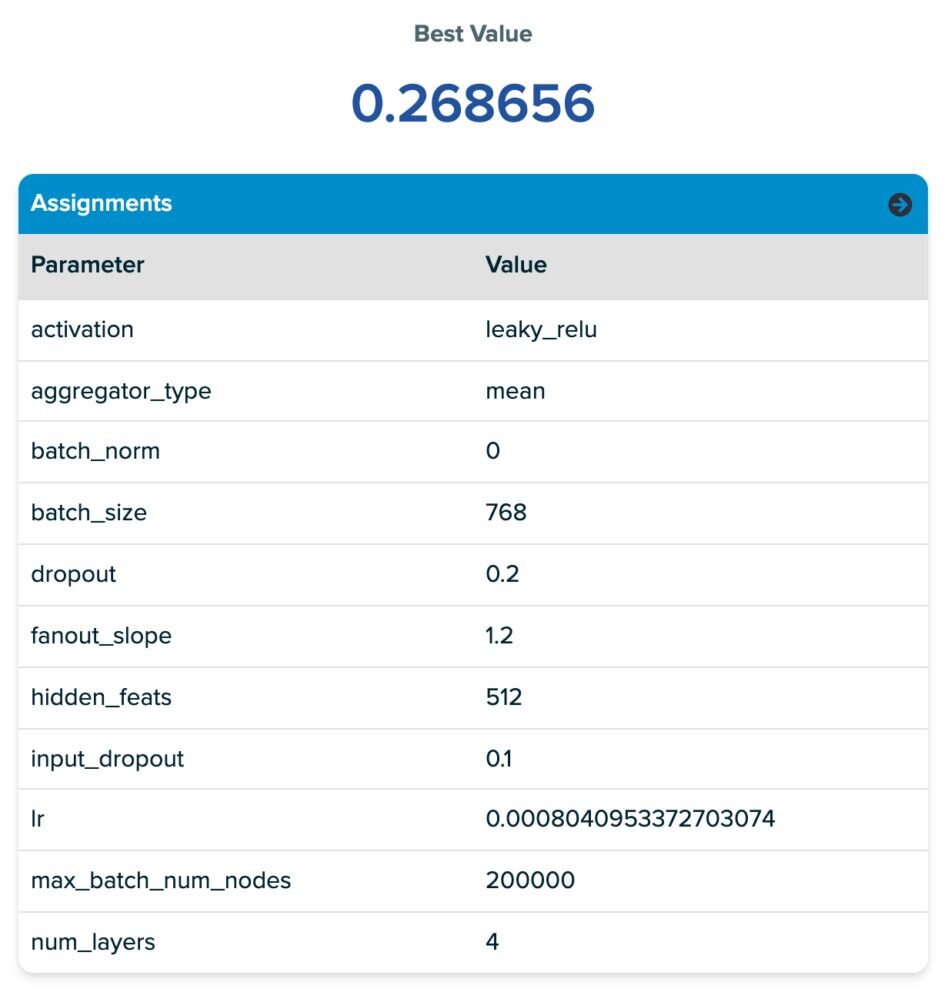
Значения параметров для первой строки таблицы приведены на скриншоте(справа под таблицей). Из скриншота параметров вы наверно заметили что наша настройка содержит множество обычных гиперпараметров нейронной сети. Вы также заметили несколько новых параметров, которые называются fanout slope и max_batch_num_nodes. Оба они относятся к параметрам библиотеки Deep Graph Library MultiLayerNeighborSampler под названием fanouts, который определяет, сколько соседних узлов учитывается при передаче сообщений. Мы вводим эти новые, чтобы побудить SigOpt выбирать «хорошие» пути в узлах из достаточно большого пространства узлов без прямой настройки количества fanouts, что, как мы обнаружили, часто приводило к чрезмерно высокому времени обучения.
Далее мы вводим следующие два параметра:
- Fanout Slope: Увеличение этого параметра действует как множитель fanout, количества узлов, сэмплируемых в каждом графе.
- Max Batch Num Nodes: порог для максимального количества узлов на батч.
Ниже мы видим конфигурации эксперимента RGCN для фазы 1. Для наших экспериментов GraphSAGE наблюдается аналогичное отклонение между мини-партией и реализацией полного графа.
Настраивая GraphSAGE мы обнаружили, что из введенных нами параметров fanout_slope был важен для прогнозирования оценок точности, а max_batch_num_nodes был относительно неважен. В частности, мы обнаружили, что достигнутое значение параметра max_batch_num_nodes, как правило, приводило к тому, что модель работала лучше.
Результаты для мини-пакета RGCN показали нечто похожее, хотя параметры max_batch_num_nodes были немного более значимыми. Оба результата показали хорошую производительность , лучше, чем их аналоги на полном графе. Все четыре настройки гиперпараметров были остановлены , если производительность сети не улучшалась после десяти эпох.
Эта процедура дала следующие распределения:
Далее мы используем результаты экспериментов для разработки плана эксперимента для дальнейшей работы, направленной на достижения высокого качества работы, как можно быстрее. .
Результаты этапа 2: разработка экспериментов для повышения эффективности
На втором этапе экспериментов мы искали модели, соответствующие выбранному уровню качества, и мы выбирали модели, которые обучались бы как можно быстрее. Мы обучали эти модели на процессорах Xeon на AWS m6.8xlarge. Наша задача оптимизации заключается в следующем:
- Минимизировать общее время работы
- При условии, что потери при валидации меньше или равны 1,05-кратному значению наилучшей оценки
- При условии точности валидации больше или равной 0,95 от наилучшего значения.
Такая постановка задач оптимизации позволила получить следующие результаты
Этот проект был направлен на демонстрацию итеративного процесса экспериментирования. На приведенном выше графике результаты работы моделей виден в прогонах RGCN, где мы видим значительное снижение дисперсии между прогонами после того, как мы значительно сократили доступную для поиска область гиперпараметров на основе анализа первой фазы экспериментов.
Обсуждение
Из результатов видно, что оптимизатор SigOpt обладает высокой производительностью ,уменьшая время на обучения. . В следующем посте мы рассмотрим третий этап этого процесса. Мы выберем несколько высококачественных конфигураций моделей с низким временем выполнения и увидим, как использование современных инструментов, таких как GNNExplainer, может облегчить дальнейшее понимание того, как выбрать правильные модели.



















