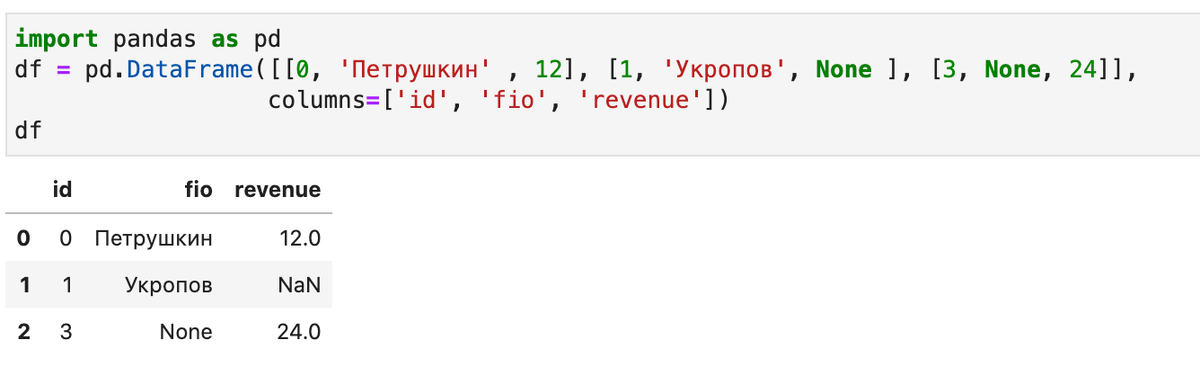
Ряд операций с датафреймами при наличии отсутствующих значений могут привести к ошибке, так как не знают, как их обрабатывать. В Pandas предусмотрены встроенные средства обхода таких ситуаций. В демонстрационных целях будем использовать следующую таблицу:
Если попытаться умножить значения последнего столбца на число, ошибки не будет, несмотря на NaN:

В то же время, если попытаться посчитать длину элементов второго столбца, то ошибка возникнет:
Для этого случая в методе map предусмотрен параметр na_action, который можно установить в 'ignore' для обхода ошибки:
Такой же параметр присутствует в методе applymap, который работает на уровне всего датафрейма, а не только одного столбца:
Без использования этого параметра мы бы столкнулись с ошибкой.
Следует отметить, что для некоторых операций, которые мы осуществляем через универсальный метод map, существуют специализированные аналоги среди векторизованных строковых методов (вызываются через str), которые умеют работать с пропусками, например, len:
Однако метод contains в их число не входит:
Спасает дело параметр na, который можно задать в False:
Таким образом, если получаете ошибку в результате обработки NaN значений, ищите спасительный параметр либо специализированные методы (как, например, векторизованные).



















