
Важность функции – техника присваивания очков полезности зависимым переменным – Предикторам (Predictor Variables) в зависимости от того, насколько они способны спрогнозировать Целевую переменную (Target Variable).
Оценка важности играеь важную роль в прогнозном моделировании, в том числе обеспечивает понимание данных, модели и создает предпосылки для Понижения размерности (Dimensionality Reduction) и выбора Признаков (Feature), которые могут повысить эффективность и действенность модели.
В этом руководстве вы узнаете о показателях важности функций для машинного обучения в Python.
Важности признаков могут быть рассчитаны для задач, связанных с прогнозированием числового значения, называемых Регрессией (Regression), и задач, связанных с прогнозированием метки класса – Классификацией (Classification).
Оценки полезны и могут использоваться в ряде ситуаций:
- Лучшее понимание данных: относительные оценки могут указать, какие функции могут быть наиболее релевантными для цели, и, наоборот, какие наименее релевантны. Это может быть интерпретировано экспертом в предметной области и использовано в качестве основы для сбора большего количества или других данных.
- Лучшее понимание модели: расчет коэффициентов важности дает представление о конкретной модели и о том, какие столбцы являются наиболее и наименее важными при прогнозировании.
- Уменьшение количества входных признаков: используя оценки важности, чтобы выбрать те функции, которые нужно удалить (обладатели самых низких оценок). Это может упростить моделирование, ускорить процесс и, в некоторых случаях, повысить производительность модели.
Классификация
Мы будем использовать функцию make_classification() для создания тестового набора данных Бинарной классификации (Binary Classification).
В Датасете (Dataset) будет 1000 примеров с 10 предикторами, пять из которых будут информативными, а остальные – избыточными. Мы внедрим элемент случайности, чтобы гарантировать получение одних и тех же результатов при каждом запуске кода.
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
from matplotlib import pyplot
Сгенерируем игрушечный набор данных, параметр n_informative как раз и определяет, какие признаки являются важными:
X, y = make_regression(n_samples = 1000, n_features = 10, n_informative = 5, random_state = 1)
Обучим модель и выведем коэффициенты важности:
model = LinearRegression()
model.fit(X, y)
importance = model.coef_
for i,v in enumerate(importance):
print('Feature: %0d, Score: %.5f' % (i,v))
Результат:
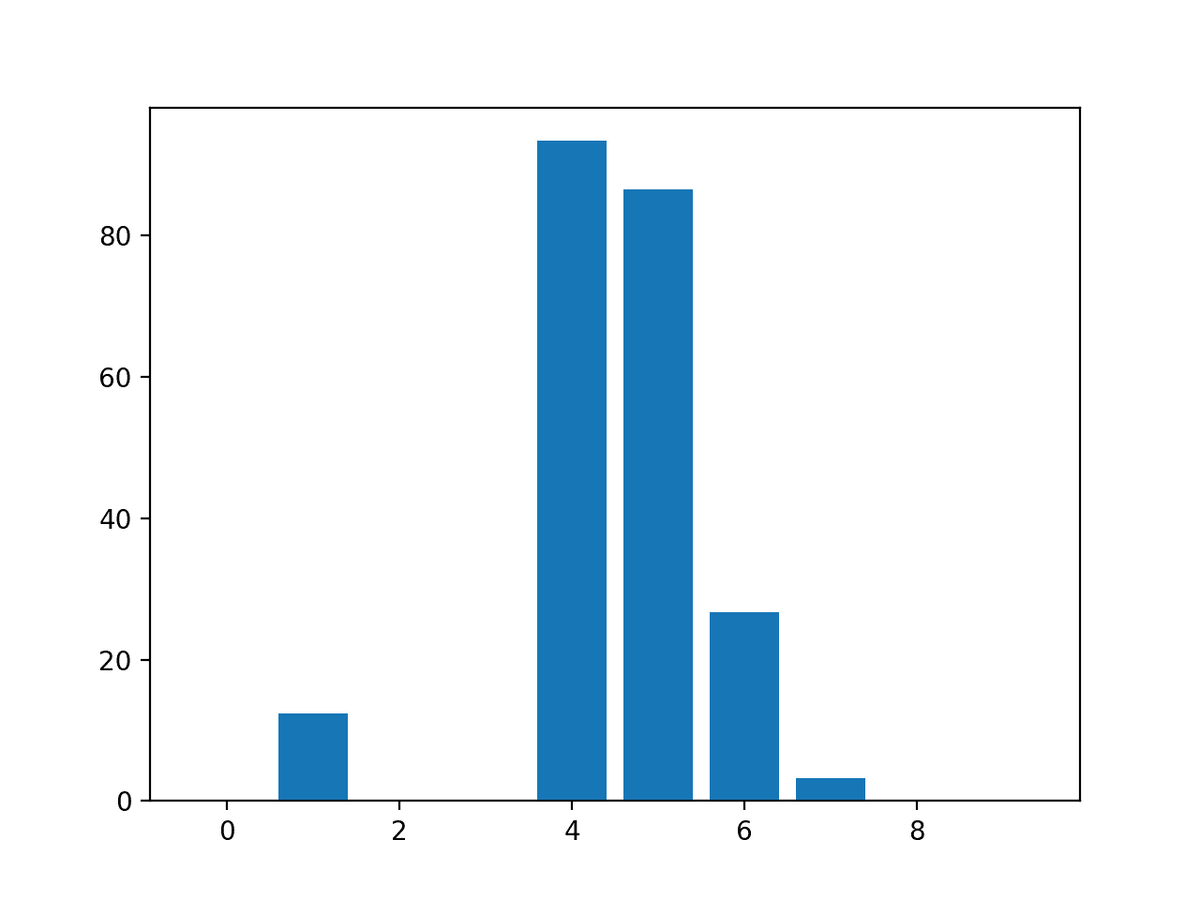
Feature: 0, Score: 0.00000
Feature: 1, Score: 12.44483
Feature: 2, Score: -0.00000
Feature: 3, Score: -0.00000
Feature: 4, Score: 93.32225
Feature: 5, Score: 86.50811
Feature: 6, Score: 26.74607
Feature: 7, Score: 3.28535
Feature: 8, Score: -0.00000
Feature: 9, Score: 0.00000
Отобразим результат с помощью столбчатой диаграммы:
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Автор оригинальной статьи: Jason Brownlee
Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал. И попробуйте курсы на Udemy.