Это история про то, что тестировать внутреннюю платформу для запуска и разработки приложений сложно, но если подойти к вопросу творчески, то можно и попробовать. В прошлой части мы уже разобрали, что такое PaaS, и теперь перейдем к подготовке и тестированию. Своим успешным опытом выполнения этой непростой задачи поделится QA-инженер Лариса Седнина.
PaaS (Platform as a Service) — внутренняя платформа для запуска и разработки приложений. Если коротко, то наш PaaS позволяет легко и, можно сказать, при нулевом знании внутренней кухни создать свой сервис и начать пилить продуктовые компоненты. Более длинное объяснение — в этом видео. Под катом небольшой рассказ о том, с какими проблемами пришлось столкнуться при первом приближении к тестированию продукта, как происходил сам процесс тестирования платформенных решений на примерах и какую пользу это принесло.
Меня зовут Лариса Седнина, я работаю QA-инженером в Авито в юните QA Center of Excellence. Наш юнит — это центр экспертизы по обеспечению качества, основная задача которого в распространении лучших практик тестирования, помощи в настройке процесса тестирования и разработке инструментов для тестирования.

Страница кронов
Предыстория у этой задачи интересная, я момент возникновения не застала, но старожилы рассказывали, что когда Авито разъезжалось в несколько ДЦ, то кроны сервиса могли независимо друг от друга запускаться в разных ДЦ, ничего не знать друг о друге, блокировать таблицы в БД, впадать в бесконечную рекурсию ожидания, когда один из двух кронов первым завершится, создавая этим трудности и пользователям, и разработчикам. Проблему эту пофиксили, но наблюдать за тем, какие задачи, сколько их, с каким статусом выполнялись в каждом из ДЦ всё равно надо.
По постановке задачи надо было вывести на дашборд список кронов/воркеров сервиса (есть сервисы на PHP, Go и Python), отобразив название, статус и историю запусков. Схематично и очень упрощенно это выглядело так:
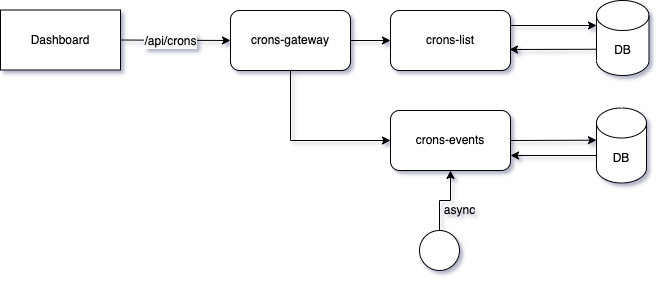
С фронта дашборда по условной ручке /api/crons идет обращение в сервис crons-gateway, который в свою очередь обращается за данными из сервиса crons-list и в crons-events. В сервис crons-events при этом асинхронно поступают события о статусах запуска (success/progress/error). Что же здесь можно протестировать?
На самом деле можно протестировать всё — от компонентов (crons-list, crons-events) до более высокоуровневого API, и, в том числе, конечное отображение данных на дашборде. Расскажу про несколько интересных багов, с которыми встретились и которые можно назвать показательными.
Пример 1: Не было сортировки истории запусков
Когда была готова ручка, при запросе данных с нее список с историей последних запусков приходил без сортировки. При опросе разработчиков оказалось, что должна быть обратная сортировка по дате, от самого раннего к самому старому. А в нашем случае брались два любых события и выводились в ответе.
Пример 2: Дублирование имени кронов
А этот баг забавный. Когда мы стали выводить на дашборд информацию о кронах, оказалось, что у нас были дублирующие записи по названиям кронов. Как они появились — история умалчивает, но неточность в данных быстро поправили.
Пример 3: Клик на любое имя крона разворачивал у всех кронов деревья с историей
Представим, что ситуацию из заголовка видно на скриншоте. Сначала это немного обескуражило, потому что ты кликаешь на второй элемент в списке, а разворачиваются все. А если у первого крона запусков не один, а тысячи? Пользователю будет неприятно увидеть это в production.
Но пришел на помощь фронтендер и помог с этим багом расправиться.
Результаты
Мы все это протестировали, посмотрели на задачу и сделали очередные выводы: меньше багов доехало до прода — счастливее пользователь, довольнее техлид.
Канареечный деплой
И тут мы подобрались к самому любимому нашему виду багов — это баги на проде. Но обо всём по порядку.
Последний, но не по значимости, кейс, про который мне хотелось бы рассказать связан с канареечным деплоем.
Справка: Canary deployment — это выкатка релиза на заданный процент продуктового трафика, метод снижения риска внедрения новой версии программного обеспечения в «производственную среду».
Один из примеров, когда канареечный деплой полезен, если при выкатке новой версии сервиса в продакшн необходимо аккуратно инвалидировать весь кэш, а прогрев кэша — операция дорогая, может занимать много времени, а сервис super-critical.
Или если вы сомневаетесь, что «бомба не рванет» на проде и хотите «пощупать» релиз и, в случае чего, быстро откатить назад, чтобы это не задело 100% пользователей.
И тут на продакшене происходит инцидент: сервис успешно задеплоился под каким-то процентом канарейки, но при особом стечении обстоятельств произошла паника в горутине, и поды канареечного релиза начали друг за другом падать со статусом CrashLoopBackOff. Это такой случай, когда pod-ы бесконечно пытаются подняться, крэшатся, и опять запускаются, и снова крэшатся, и снова пытаются подняться. И так без конца, никогда не пройдя readiness probe-ы. Из-за чего оставшиеся «здоровые» pod-ы сервиса со старой версией релиза перестали справляться с нагрузкой, так как на них полился весь имеющийся трафик, и сервис стал отдавать ошибки пользователям. Дополнительно к этому, вишенкой на торте, билд с отменой или изменением процента канарейки в пайплайне деплоя успешен, но readiness probe-ы у pod-ов нового релиза всё так же не проходят.
Первое, что хочется сделать в такой ситуации — это запаниковать. Но так как у нас уже есть паника в горутине, то мы для начала устраним инцидент и его последствия, а потом попробуем воспроизвести этот инцидент в лабораторных условиях.
27-28 июня в Москве впервые пройдет TestDriven Conf 2022 — профессиональная конференция для senior тестировщиков и QA-инженеров. Она будет посвящена всем вопросам автоматизации в тестировании и рядом. Расписание и тезисы докладов уже на сайте. И можно забронировать билеты по выгодной цене — чем ближе к конференции, тем будет дороже.