Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, Hao Ma
Статья: https://arxiv.org/abs/2006.04768
Хочется написать про свежий Performer, но пожалуй стоит перед ним написать про Linformer.
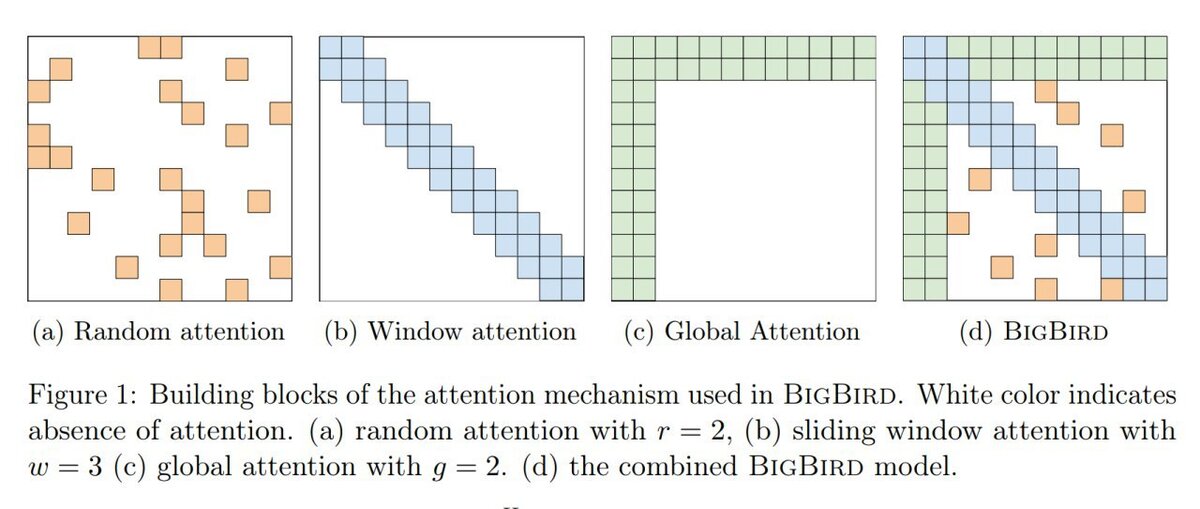
Это всё из серии про уменьшить квадратичную сложность полного механизма внимания в трансформере. Линформер, очевидно по названию, уменьшает сложность до линейной и по времени и по месту. За последние полгода таких работ уже несколько, недавний Big Bird (https://t.me/gonzo_ML/381) из свежего, или чуть более ранняя работа с многообещающим названием “Transformers are RNNs” (https://arxiv.org/abs/2006.16236).
Разберём Linformer.
Идея в общем проста — заменим полную матрицу внимания на низкоранговую аппроксимацию. Авторы исходят из наблюдения, что self-attention низкоранговый. Для этого они анализируют спектр матрицы и утверждают, что особенно в верхних слоях, больше информации сконцентрировано в наибольших сингулярных значениях. И грубо говоря, считаем SVD для матрицы внимания и оставляем только k сингулярных значений (например, 128).
SVD только дорого считать на каждый чих, поэтому делаем проще, вводим две линейные проекции для K и V (Q не трогаем) перед расчётом внимания, так что в итоге считать придётся меньше. Оригинальные размерности n*d матрицы ключей и значений конвертятся в k*d и дальше внимание уже скейлится линейно, получается матрица внимания n*k вместо n*n.
Для пущей оптимизации эти матрицы проекций (E и F) можно ещё и пошарить между головами или слоями.
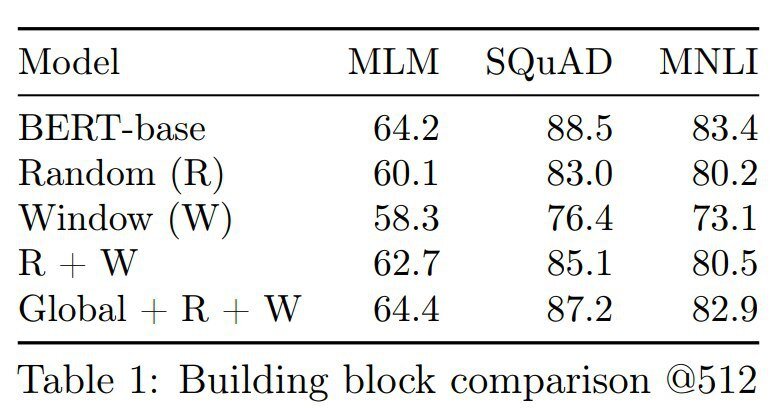
В экспериментах получают для k=128 качество как у трансформера с n=512, а для k=256 сравнимо с n=1024. И шаринг тоже работает, даже если шарить матрицы на все слои (то есть вообще одна матрица E на всю сеть).
Ну в общем работает вроде как, качество норм. Получают качество сравнимое с BERT’ом или RoBERTa, но при в 4 раза меньшем k. Плюс всё получается быстрее и памяти жрёт меньше.
См