Наша способность решать задачи NLP с помощью алгоритмов ИИ значительно продвинулась вперед, но наше понимание человеческого языка еще очень мало. Это связано с тем, что большинство алгоритмов ИИ работают как черный ящик, и хотя мы знаем архитектуру модели и значения всех параметров, понять основные функции, которые эти алгоритмы используют для задачи NLP, очень сложно. Но для многих практических приложений необходимо, чтобы ИИ был понятен, без чего эти причудливые алгоритмы просто остаются академическим наборами формул.
В 2020 году мы нашли очень простой алгоритм классификации текстов, который может помочь определить, относится ли данный фрагмент текста к художественному или документальному жанру. Мы назвали его Fictometer! Поэтому, если вы возьмете отрывок из своего любимого романа или любимой исследовательской работы, Fictometer сможет определить разницу между ними. И он работает с поразительно высокой точностью (~96%)!
Полная статья с описанием работы алгоритма здесь.
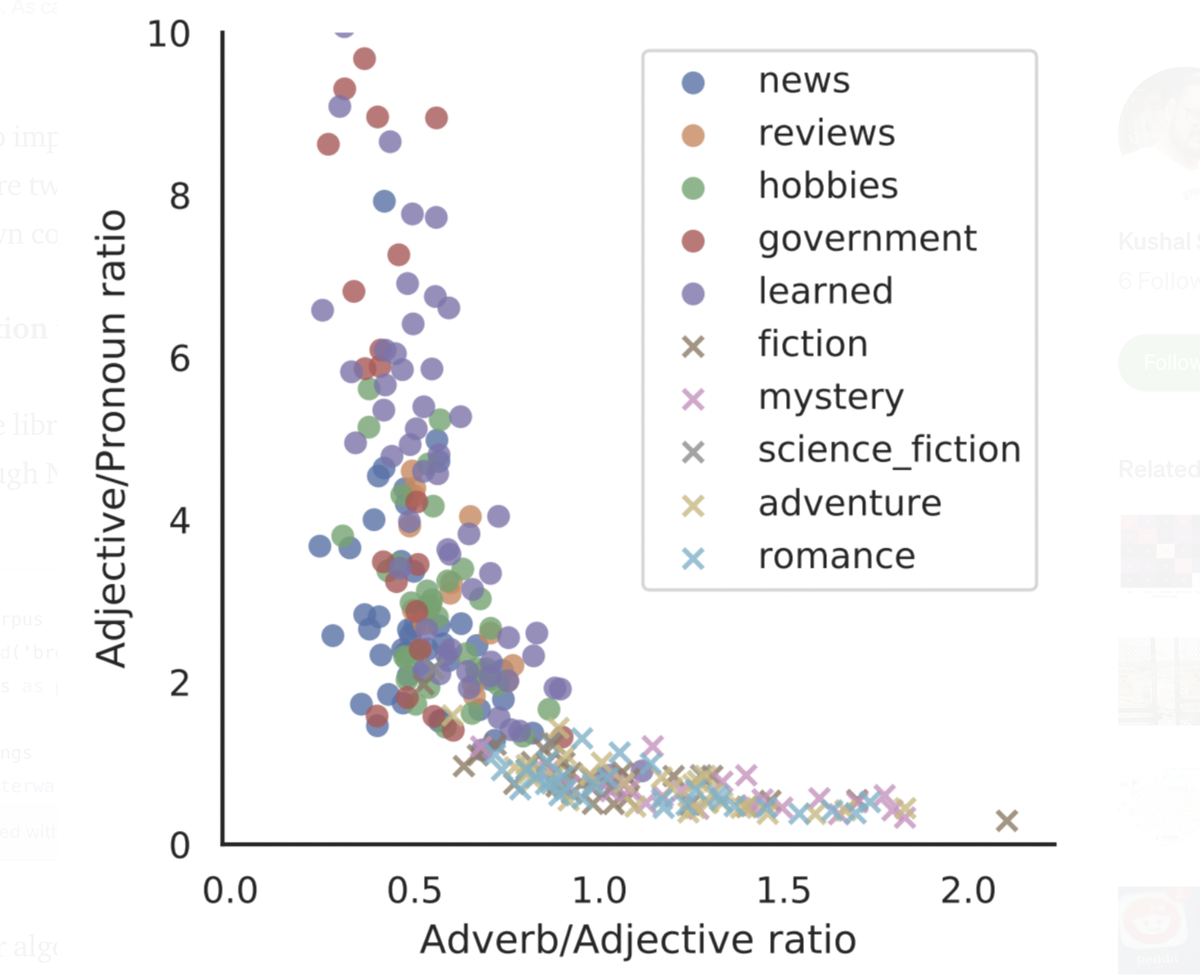
Давайте посмотрим, как реализовать этот алгоритм, используя данные корпуса Брауна из NLTK. Код состоит из двух частей. Первая часть это подготовка данных с использованием корпуса NLTK Brown, а вторая часть — применению логистической регрессии.
Подготовка данных с использованием NLTK Brown Corpus
Сначала импортируем библиотеки, которые нам нужны для работы с данными.
import nltk
from nltk.corpus import brown
nltk.download('brown')
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
Алгоритм Fictometer основан на Частеречная разметка Parts-Of-Speech (POS), которая является фундаментальным аспектом НЛП. Частеречная разметка (автоматическая морфологическая разметка, POS tagging, part-of-speech tagging) — этап автоматической обработки текста, задачей которого является определение части речи и грамматических характеристик слов в тексте (корпусе) с приписыванием им соответствующих тегов. POS tagging является одним из первых этапов компьютерного анализа текста.
Алгоритмы POS tagging делятся на две группы: основанные на правилах и вероятностные.
Существуют различные способы разметки POS-тегов для данного текста, но в целом мы можем использовать либо универсальные POS-теги (существительное, прилагательное, наречие, местоимение и т. д.), либо более тонкие теги, которые различают различные типы существительных, прилагательных, и т. д. Для нашей задачи теги UPOS достаточно хороши, поэтому далее мы пишем функцию для подсчета количества различных тегов UPOS в заданном тексте.
def n_adj(text):
adj=0
for i in text:
if i[0] == 'J':
adj=adj+1
return adj
def n_noun(text):
noun=0
for i in text:
if ((i[0] == 'N') and (i[1] != 'C')):
noun=noun+1
return noun
def n_verb(text):
verb=0
for i in text:
if i[0] == 'V':
verb=verb+1
return verb
def n_pronoun(text):
pronoun=0
for i in text:
if (i[0] == 'P') or (i[:3] in ['WP$','WPO','WPS']):
pronoun=pronoun+1
return pronoun
def n_adv(text):
adv=0
for i in text:
if (i[0] == 'R') or (i[:3] in ['WRB']):
adv=adv+1
return adv
def func_utag(tag):
if tag[0] == 'J' or tag == 'ADJ':
utag='ADJ'
elif ((tag[0] == 'N') and (tag[1] != 'C')) or tag == 'NOUN':
utag='NOUN'
elif tag[0] == 'V' or tag == 'VERB':
utag='VERB'
elif (tag[0] == 'P') or (tag[:3] in ['WP$','WPO','WPS']) or tag == 'PRON':
utag='PRON'
elif (tag[0] == 'R') or (tag[:3] in ['WRB']) or tag == 'ADV':
utag='ADV'
else:
utag='unknown'
return utag
def func_is5tag(tag):
if tag in ['ADJ','ADV','NOUN','PRON','VERB']:
is5tag=True
else:
is5tag=False
return is5tag
код: https://gist.github.com/atmabodha/c6ddea356d15431e5e02eea83abca038#file-fictometer2-py
Сначала создаем DataFrame, который содержит информацию о количестве различных POS-тегов для каждого текста в корпусе.
brownpostable=pd.DataFrame(columns=['category','filename','ADJ','ADV','NOUN','VERB','PRON','RADJPRON','RADVADJ'])
for i in brown.categories():
for j in brown.fileids(categories=i):
taggedwords=brown.tagged_words(j)
taglist=[]
for k in taggedwords:
taglist.append(k[1])
adj=n_adj(taglist)
adv=n_adv(taglist)
noun=n_noun(taglist)
verb=n_verb(taglist)
pronoun=n_pronoun(taglist)
brownpostable=brownpostable.append({'category' : i,'filename' : j, 'ADJ' : int(adj), 'ADV' : int(adv), 'NOUN' : int(noun), 'VERB' : int(verb), 'PRON' : int(pronoun)},ignore_index=True)
код: https://gist.github.com/atmabodha/27a323cd86b84e9123c86e2a25ec10b3#file-fictometer3-py
Как только у нас будет вся информация тега UPOS в нашем DataFrame, нам нужно рассчитать два соотношения, которые являются функциями нашей модели: прилагательное/местоимение и наречие/прилагательное.
for i in range(len(brownpostable)):
adj=brownpostable.ADJ.iloc[i]
adv=brownpostable.ADV.iloc[i]
pronoun=brownpostable.PRON.iloc[i]
brownpostable.RADJPRON.iloc[i]=adj/pronoun
brownpostable.RADVADJ.iloc[i]=adv/adj
В корпусе Брауна есть несколько подкатегорий текста, поэтому нам нужно определить каждую из них как «художественную» или «нехудожественную» в зависимости от ее содержания.
brown2=brownpostable.copy()
for i in ['news','reviews','government','learned','hobbies']:
brown2=brown2.replace(to_replace=i,value='nonfiction')
for i in ['fiction','mystery','science_fiction','adventure','romance']:
brown2=brown2.replace(to_replace=i,value='fiction')
index_names=brown2[(brown2['category'] != 'fiction') & (brown2['category'] != 'nonfiction')].index
brown2.drop(index_names,inplace=True)
brown3=brown2.replace(to_replace='nonfiction',value='0')
brown3=brown3.replace(to_replace='fiction',value='1')
код: https://gist.github.com/atmabodha/4ee85ae48a6257638c674d8e0e02e16d.js
Обучение и тестирование модели с использованием логистической регрессии
Здорово! Итак, наши данные готовы к обучению и тестированию с использованием любого алгоритма машинного обучения. Мы выбираем логистическую регрессию из-за ее относительной простоты. И это работает удивительно хорошо!
from sklearn import preprocessing
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
Затем мы удаляем все ненужные столбцы из нашего DataFrame, извлекаем входные и выходные значения, разбиваем их на набор для обучения и тестирования и подгоняем модель логистической регрессии, используя обучающие данные.
x=brown3.drop(columns=['category','filename','PRON','ADJ','ADV','NOUN','VERB'])
y=brown3.category
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
logreg = LogisticRegression(solver='lbfgs')
logreg.fit(x,y)
Наконец пришло время увидеть результаты нашей тяжелой работы!
y_pred=logreg.predict(x_train)
accuracy = metrics.accuracy_score(y_train,y_pred)
print("Training Accuracy : ",accuracy)
y_pred=logreg.predict(x_test)
accuracy = metrics.accuracy_score(y_test,y_pred)
print("Testing Accuracy : ", accuracy)
print("Confusion Matrix : \n",confusion_matrix(y_test,y_pred))
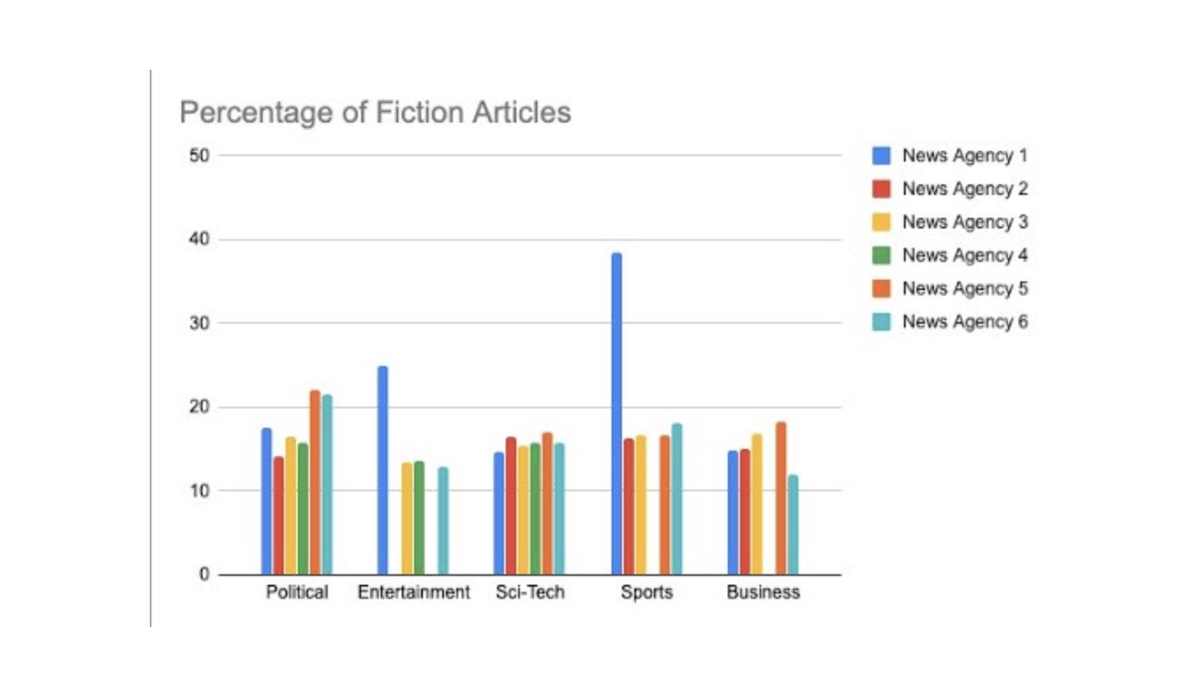
У алгоритма Fictometer может быть много практических применений, но я считаю, что наиболее важное из них — в средствах массовой информации, чтобы помочь в обнаружении манипулятивных новостных статей, которые используют определенный язык и терминологию, а не прямолинейные фразы и слова основанные на фактах. Согласно краткому исследованию, которое мы провели с использованием новостных статей из известных источников новостей, около 15% опубликованных статей относятся к этой категории эмоционально манипулятивных.
Мы также разработали сервис, с помощью которого вы можете опробовать алгоритм на любом тексте: https://fictometer.herokuapp.com/
Github: https://github.com/atmabodha/Fictometer/blob/main/brown_fictometer-github.ipynb
Telegram: https://t.me/ai_machinelearning_big_data