Данная статья завершает цикл моих переводов статей Jakob Jenkov об оптимизации Java приложений.
Микропакетная обработка - это метод, при котором входящие задачи, подлежащие выполнению, группируются в небольшие пакеты для достижения некоторого преимущества пакетной обработки в производительности, не слишком увеличивая задержку для завершения каждой задачи. Микропакетирование обычно применяется в системах, где количество входящих задач является переменным. Система будет захватывать все поступающие задачи, которые были получены, и выполнять их в пакетном режиме. Этот процесс выполняется многократно.

Таким образом, размер пакета может варьироваться от 1 до максимального верхнего предела, установленного системой, например 64, 128, 1024 или любого другого максимального размера пакета, подходящего для системы. Обычно максимальный размер партии невелик по причинам, которые я объясню ниже, отсюда и термин "микропакетирование".
Компромисс между задержкой и пропускной способностью
Сервис-ориентированные системы часто нуждаются как в низкой задержке, так и в высокой пропускной способности. Однако это не всегда возможно. Некоторые методы уменьшения задержки также снижают пропускную способность, а некоторые методы увеличения пропускной способности также увеличивают задержку. В следующих разделах я объясню это более подробно.
Задержка
Задержка - это мера временной задержки в системе. В системе клиент-сервер задержка может означать несколько вещей. Задержка в сети - это время, необходимое для сообщения, отправленного клиентом, пока оно не достигнет сервера. Задержка сервера - это время, необходимое серверу для обработки запроса и генерации ответа. Оба типа задержек проиллюстрированы ниже:
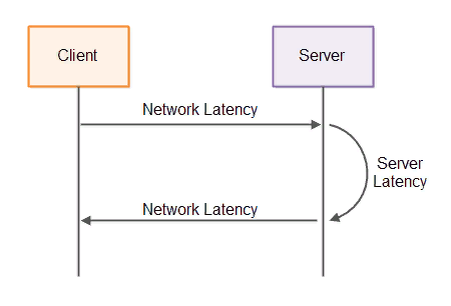
Полное время прохождения одного запроса в оба конца до тех пор, пока клиент не получит ответ, составит
network latency + server latency + network latency =
2 * network latency + server latency
Сначала запрос должен быть отправлен на сервер, затем сервер должен обработать запрос и сгенерировать ответ, а затем ответ должен быть отправлен обратно по сети клиенту.
Чтобы система имела быстрое время отклика, как задержка в сети, так и задержка на сервере должны быть низкими. Точно такое же "быстрое" и "медленное" время отклика или "высокие" и "низкие" задержки зависят от конкретной системы. Для некоторых систем время отклика менее 1 секунды - это хорошо. И для некоторых систем это должно быть менее 10 миллисекунд, чтобы быть хорошим.
Пропускная способность
Пропускная способность - это показатель того, сколько работы система может выполнить за данный интервал времени. В случае клиент-серверной системы пропускная способность сервера измеряет, сколько запросов за интервал времени (обычно в секунду) сервер может обработать. Это число означает общее количество запросов в секунду, которые сервер может обрабатывать от всех подключенных клиентов, а не только от одного клиента.
Пропускная способность, видимая клиентом, означает, сколько запросов за интервал времени этот конкретный клиент может отправлять и получать ответы. Оба типа пропускной способности проиллюстрированы ниже:
Пакетная обработка
Пакетирование - это метод увеличения пропускной способности системы. Вместо того, чтобы выполнять каждую задачу отдельно, задачи группируются в большие пакеты и выполняются все вместе.
Пакетное выполнение имеет смысл в ситуациях, когда накладные расходы, связанные с выполнением каждой задачи, высоки - если эти накладные расходы можно уменьшить за счет пакетного выполнения. Чтобы понять, как это сделать, давайте посмотрим на пример:
Представьте, что у клиента есть 10 запросов, которые он должен отправить на сервер. Клиент может отправлять по 1 запросу за раз, получать ответ, а затем отправлять следующий запрос. Общее время, необходимое для обработки этих сообщений, составит:
10 * (network latency + server latency + network latency) =
20 * network latency + 10 * server latency
Если вместо этого клиент отправляет все 10 запросов в одном сообщении на сервер, а сервер обрабатывает их все последовательно и отправляет обратно 10 ответов, общее время, необходимое для обработки этих запросов, составит:
network latency + 10 * server latency + network latency =
2 * network latency + 10 * server latency
Как вы можете видеть, пакетирование значительно сократило сетевую задержку, связанную с обработкой 10 запросов - с 20 * сетевой задержки до всего 2 * сетевой задержки. Это означает, что общая пропускная способность клиент-серверной системы, видимая клиентом, увеличилась.
Недостатком пакетной обработки является время, необходимое для сбора задач для пакетной обработки. Если клиенту требуется 2 часа, чтобы собрать эти 10 задач, то задержка системы в целом стала довольно высокой. Первая задача должна подождать 2 часа, прежде чем наберется достаточно задач для отправки пакета, что означает, что с момента сбора первых задач до получения клиентом ответа на нее пройдет 2 часа.
Аналогично, как только пакет отправляется, для обработки пакета требуется задержка сервера 10 *. Это еще больше увеличивает задержку первого запроса, поскольку ему приходится ждать обработки всех 10 запросов, прежде чем будет получен ответ на первый запрос.
Как вы можете видеть, пакетирование - это метод, который увеличивает пропускную способность, но также увеличивает задержку.
Микропакетирование
Микропакетирование - это вариант пакетирования, который пытается найти лучший компромисс между задержкой и пропускной способностью, чем пакетирование. Способ, которым микро-пакетирование делает это, заключается в ожидании коротких временных интервалов для пакетной обработки задач перед их обработкой. Я называю этот интервал пакетным циклом. Этот принцип короткого периодического цикла проиллюстрирован здесь:
Продолжительность пакетного цикла должна зависеть от системы. Для некоторых систем может быть достаточно 1 секунды. Для других систем может быть достаточно 50-100 миллисекунд. А для других систем еще меньше.
При высокой нагрузке на систему она будет получать больше задач, готовых к обработке в рамках каждого пакетного цикла. Таким образом, по мере увеличения нагрузки на систему увеличивается размер пакета и увеличивается пропускная способность. Цена с точки зрения более высокой задержки при увеличении размера пакета минимальна.
Пакетные циклы переменной продолжительности
Для систем, требующих малого времени отклика, продолжительность пакетного цикла даже в 50 миллисекунд может быть слишком большой. Вместо этого таким системам может потребоваться использовать переменную продолжительность пакетного цикла.
Чтобы снизить задержку, но при этом обеспечить возможность микропакетной обработки, вы можете перебирать входные каналы (входящие сетевые подключения, каталоги и т.д.) И проверять их все на наличие входящих задач (запросов, сообщений и т.д.). Какие бы задачи вы ни обнаружили, вы выполняете в микропакете. Каждая итерация в этом цикле становится одним пакетным циклом.
Как только микропакет будет выполнен, вы немедленно повторите цикл. Это означает, что время между каждым пакетным циклом полностью зависит от количества входящих задач. При низкой нагрузке размер партии будет небольшим, и, следовательно, цикл партии будет короче. При высокой нагрузке размер пакета будет увеличиваться, и, следовательно, продолжительность цикла пакета будет увеличиваться.
Пакетные циклы переменной продолжительности проиллюстрированы здесь:
Применение микропакетирования
Микропакетирование можно использовать во многих ситуациях, когда можно использовать пакетирование, но где требуется меньшее время отклика. Я расскажу о некоторых из этих вариантов использования в следующих разделах, но эти варианты использования не единственные. Из этих вариантов использования вы должны иметь возможность получить общую картину и быть в состоянии определить, когда микропакетирование может быть полезно в ваших собственных системах.
Сохраняемость файлов
Запись данных на диск обычно сопряжена со значительными накладными расходами. Если вашей системе необходимо записывать блок данных на диск для каждой выполняемой задачи, общие накладные расходы могут быть значительными.
Если вы выполняете групповую запись и, таким образом, записываете только объединенный блок данных на диск, накладные расходы, связанные с записью большего блока данных, обычно меньше, чем совокупные накладные расходы на выполнение записей по отдельности. В результате получается система, которая может обрабатывать большую пропускную способность (больше данных, записываемых за единицу времени).
Использование микропакетной обработки для сохранения файлов обычно требует, чтобы остальная часть системы также была предназначена для использования микропакетной обработки. Если блоки данных поступают по одному в компонент сохранения файлов, единственный способ сгруппировать их в пакеты - это подождать короткий промежуток времени, прежде чем записывать их на диск. Если блоки данных поступают микропакетами, потому что они являются результатом микропакетной обработки в другом месте, группировать их в микропакеты для записи на диск намного проще.
межпоточное взаимодействие
Когда потоки обмениваются данными, они обычно делают это с помощью параллельных структур данных. Часто используемой структурой для этой цели является параллельная очередь. Это проиллюстрировано здесь:
Чтение и запись элементов в очереди по одному элементу за раз часто связаны с более высокими накладными расходами на элемент, чем при чтении или записи пакетов элементов. Подробнее об этом вы можете прочитать в моем руководстве по кольцевому буферу Java. Кольцевые буферы также можно использовать в качестве очередей. Отправка пакетов сообщений через очереди проиллюстрирована здесь:
Межпроцессное взаимодействие
Межпроцессное взаимодействие во многом аналогично межпотоковому взаимодействию. Когда процессы обмениваются данными, часто возникают накладные расходы, связанные с отправкой данных за пределы процесса - например, на диск, сокеты unix или сетевые сокеты. Поэтому может быть полезно группировать данные, отправляемые вне процесса, чтобы минимизировать накладные расходы на каждый блок данных (например, на запрос, сообщение, задачу и т.д.).
Ранее в этом руководстве я уже объяснял, как пакетирование может помочь в сценарии клиент-сервер, который является обычным случаем взаимодействия между процессами.
В качестве дополнительного подтверждения этой истины пакетные обновления базы данных обычно выполняются намного быстрее, чем отправка каждого обновления в базу данных по отдельности. При пакетном обновлении больше обновлений отправляется по сети в пакетном режиме, и база данных также может иметь возможность записывать обновления на диск в виде пакетной операции.
Однопоточные серверы
Однопоточная серверная архитектура в наши дни вновь набирает популярность благодаря своей очень простой модели параллелизма (все выполняется в одном потоке) и, следовательно, ее способности во многих случаях лучше использовать кэш ЦП, чем многопоточные модели параллелизма. Это также упоминается в моем руководстве по моделям параллелизма.
Однопоточные серверы обычно опрашивают все открытые входящие соединения на предмет считывания данных. Если входящее соединение содержит входящие данные, оно считывается и обрабатывается.
Однопоточные серверы могут извлечь выгоду из микропакетной обработки. Вместо чтения и обработки одного сообщения из одного соединения за раз, однопоточный сервер считывает все полные сообщения из всех входящих подключений и обрабатывает их в пакетном режиме.
Использование схемы микропакетной обработки на однопоточном сервере упрощает использование обработки другими частями этой системы (работающими внутри того же сервера).
Обход больших структур данных
Некоторым приложениям может потребоваться просматривать большие структуры данных, хранящиеся в памяти или на диске. Например, таблица базы данных или древовидная структура. При обходе больших структур данных возникают определенные накладные расходы. Для структур данных на основе памяти данные должны быть перенесены в кэш CPU L1 из основной памяти, а для структур данных на основе диска данные должны быть перенесены в основную память с диска, а затем из основной памяти в кэш L1.
Вместо обхода всей структуры данных для обслуживания только одного "запроса" (задачи, сообщения и т.д.) вы можете объединить несколько запросов или задач. При обходе структуры данных каждая "запись" или "узел" в структуре данных могут быть проверены в соответствии с пакетом запросов, а не только с одним запросом.
В случае, если какой-либо из этих запросов вносит изменения в структуру данных, запросы должны получать доступ к структуре данных в том же порядке, в каком они были получены от клиента. Таким образом, запрос 2 будет видеть каждую запись / узел структуры данных в том виде, в каком запрос 1 оставил бы ее, даже если запрос 1 еще не полностью завершил обновление всей структуры данных.
#code #java #performance