Сегодня я расскажу про язык R. С несколько нестандартной точки зрения. Мои рабочие инструменты — это Вим и Перл для текста; Фортран, R и Перл для расчетов, R и GrADS для рисования (пытаюсь освоить еще PyNGL, в девичестве NCL). Вот про R я сегодня и расскажу.
Это язык программирования, предназначенный прежде всего для статистики. Но не только для нее! Статистика нужна часто, так что удобные средства для нее пригождаются — но о них есть где прочитать. Мне R ценен прежде всего графическими возможностями. Хорош и и для работы с массивами, векторами и матрицами, а это часто бывает нужно.
Можно писать скрипты и потом выполнять командой source или из командной строки через Rscript. А можно запустить среду R и работать в режиме интерпретатора.
В заметке про орлянку я приводил графики. Давайте покажу, как один из расчетов был проведен. Алгоритм описан в заметке, речь идет о расчете среднего числа партий в орлянку до разорения одного из игроков или до исчерпания лимита партий M. При этом суммарный капитал двоих равен N, и нас интересует среднее число партий при различном начальном капитале одного игрока: от 1 ставки до N-1. Итак:
N=50
nn=seq(N-1)
j=(N-nn)*nn
A=matrix(0,ncol=N-1,nrow=N-1)
for(n in nn) for(k in nn) A[k,n]=sin(pi*k*n/N)
z=solve(A,j)
M=50
B=diag(cos(pi*nn/N)^M)
ABz=A %*% B %*% z
res = j - ABz
plot(res, col='red', xlab='Money', ylab='Games')
Пояснения.
- В R традиционно используют милые символы присваивания <- и ->, но я как-то всё использую обычный знак =.
- Функция seq создает массив от 1 до указанного числа.
- Векторные операции существуют и удобны: (N-nn)*nn выполняет все операции поэлементно, создавая массив (вектор).
- Матрицу можно создать из массива или даже числа, указав ее размеры. Если из массива, то можно один размер, второй получится сам.
- Циклы тоже есть, хотя их рекомендовано избегать. Все элементарные функции, разумеется, присутствуют.
- Решение системы линейных уравнений очень просто. И эффективно, можете мне поверить.
- Диагональную матрицу создать тоже несложно.
- Операция %*% означает умножение матриц.
- Функция plot рисует график. Можно добавлять на график линии посредством функции lines.
Сохранить рисунок в файл нельзя, но можно сразу рисовать в файл:
png('file.png')
...
dev.off()
Точка в R является допустимым символом в именах, так что в функциях они часто встречаются. После dev.off() файл закрывается и рисунок готов. Обычно я довожу рисунок до приемлемого качества в интерактивном режиме, а потом финальные команды повторяю между вызовами png и dev.off: вручную или скриптом.
А вот как я сделал симулятор для игры в орлянку:
Nex=1000
acc=seq(Nex)*0
for(i in seq(Nex)) {
n=0; S=1;
while((S>0) & (S<21)){
S = S + round(runif(1))*2 - 1
n=n+1
};
acc[i]=n
}
mean(acc)
hist(acc)
plot(acc)
Цикл for ставит эксперименты, в данном случае их тысяча. В каждом играется орлянка до конца игры (до разорения одного из игроков). Один ход состоит генерации случайного числа с равномерным распределением на [0,1] (runif); число округляется, давая нуль или единицу, равновероятно. Умножается на два и уменьшается на один, давая -1 или 1. Когда сумма достигнет нуля или установленного предела, записывается результат: число игр. Выводим среднее, рисуем гистограмму и график.
Помимо симуляций, часто надо считать данные из файла и анализировать их. Для этого есть очень удобная функция read.table, читающая таблицу с данными и создающая dataframe: особый тип данных, который и есть таблица. Там столбцы, которые имеют имена (по умолчанию V1, V2 и т.д., но можно и что-то осмысленное задать).
Например, пусть у нас файл file.dat с таким текстом:
0 0
1 1
2 4
Читаем: my.data = read.table('file.dat')
Получим переменную my.data со столбцами V1, V2, доступ к которым осуществляется так: my.data$V1. Например, plot(my.data$V1, my.data$V2)
Можно дать более осмысленные имена: names(my.data) = c('x', 'y')
Функция c() создает вектор/массив из перечисленных данных.
Можно и сразу считать имена столбцов из файла, если они там есть (в первой строке подписаны):
my.data = read.table('file.dat', header=TRUE)
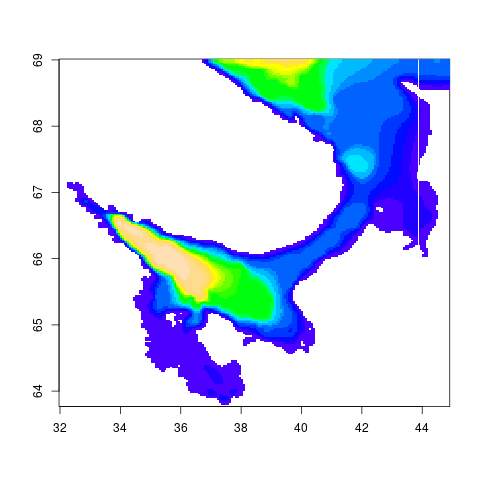
А вот как можно рисовать море. Есть текстовая карта, в которой каждая точка задана двузначным числом, обозначающим глубину: числа разделены пробелами. Сливаем все строчки в один длинный столбец, поставив конец строки вместо каждого пробела. Это я делаю в Вим.
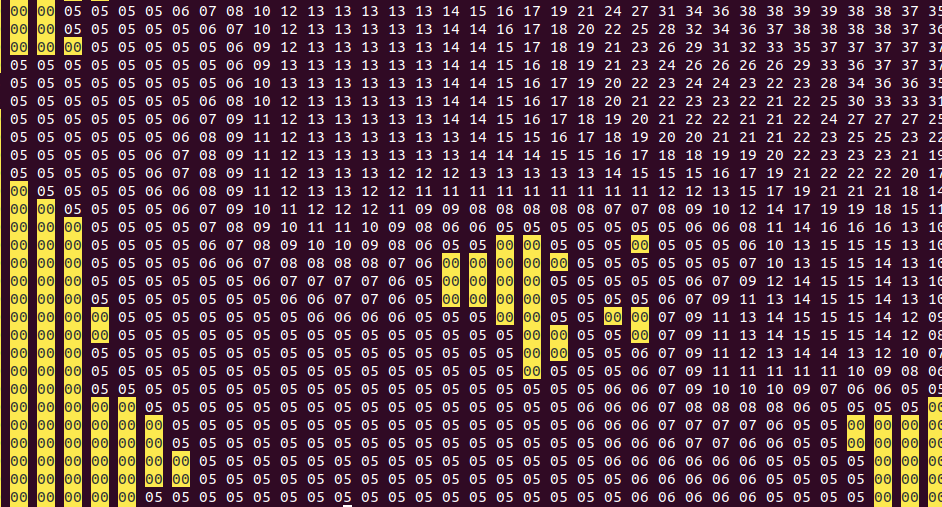
Считываем карту:
km=read.table('sea.map.1line')
Весь наш длинный столбец теперь в km.V1. Сворачиваем в матрицу:
wsmap=matrix(km$V1,ncol=200,nrow=200)
Заменяем нули (сушу) на значение NA (not available, это для отсутствующих данных):
is.na(wsmap)=wsmap==0
Теперь можно и нарисовать:
image(wsmap[,seq(200,1,-1)],
col=topo.colors(20),
x=seq(32, 44.88, len = 200),
y=seq(63.78,69,len=200),
xlab='',
ylab=''
)
Синтаксис wsmap[, ...] означает "все строки, указанные столбцы". Функция seq генерирует последовательность чисел, seq(200,1,-1) создает числа от 200 до 1 с шагом -1. То есть просто убывающие от 200 до 1. Таким образом, мы поменяли местами столбцы матрицы.
Функция image рисует матрицу по столбцам, то есть транспонирует и рисует снизу вверх. В итоге столбцы получаются строками на рисунке, и первый внизу. Поэтому мы поменяли местами столбцы: они станут строками, и "север", который был сверху, должен и быть сверху.
Выбираем цвета: параметр col. Можно по-всякому это делать, мы просто выбрали готовую палитру topo.colors из 20 цветов.
Чтобы оси координат были не от 0 до 1, а как надо, мы задаем регулярные отсчеты долгот и широт, по 200 точек, от указанного значения до указанного.
А меток не надо, и мы их отключили. Могли бы задать какой-то текст.
Давайте еще поиграем со статистикой. Создадим нормально распределенную выборку:
s1=rnorm(100)
Линейно преобразуем ее:
s2 = 42*s1+666
Сгенерируем равномерный шум:
err = 1+(runif(100)*2-1)*0.01
"Испортим" "измерения":
s2 = s2*err
Нарисуем гистограммы и график.
Теперь проведем анализ. Корреляцию найдет cor(s1,s2), и она равна 0.995. Но это только начало. Есть cor.test(s1,s2), которая сделает куда больше:
> cor.test(s1, s2)
Pearson's product-moment correlation
data: s1 and s2
t = 99.308, df = 98, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.9926661 0.9966848
sample estimates:
cor
0.9950682
Можно провести регрессионный анализ, выявив линейную связь между переменными. Сначала построим модель:
model.s = lm(s2~s1)
В переменной model.s хранится линейная модель. Можно ее даде посмотреть:
Call:
lm(formula = s2 ~ s1)
Coefficients:
(Intercept) s1
665.49 42.55
Мы видим, что коэффициенты не идеально исходные, но близки. Можно узнать больше, запросив сводку: summary(model.s). Получим
> summary(ss)
Call:
lm(formula = s2 ~ s1)
Residuals:
Min 1Q Median 3Q Max
-7.3466 -3.0761 -0.5631 3.3377 6.8814
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 665.4919 0.4027 1652.7 <2e-16 ***
s1 42.5520 0.4219 100.9 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4.005 on 98 degrees of freedom
Multiple R-squared: 0.9905, Adjusted R-squared: 0.9904
F-statistic: 1.017e+04 on 1 and 98 DF, p-value: < 2.2e-16
Мы получаем погрешности, то есть отличие измеренной s2 от предсказанной по линейной модели по значениям s1: наименьшее отклонение -7.3, наибольшее 6.88, медианное -0.5.
Получаем коэффициенты, с оценкой значимости. Звездочки показывают, ннасколько надежна статистическая оценка. Есть и другие показатели, вроде R-квадрат (очень высок).
Как видим, статистики очень много и делается она очень легко, но надо знать, где что лежит. Но материалов в Сети полным-полно, так что проблем быть не должно.
Мне понравилась обстоятельная книга Р.И. Кабакова "R в действии. Анализ и визуализация данных на языке R"
Удачи, коллеги.
Отличные каналы коллег, которые сердечно рекомендую.
А вот подборка только научно-популярных каналов.
Оглавление этой рубрики и Путеводитель по моему каналу