Монолитная компоновка для современных сложных чипов уже становится слишком неэффективной. Бороться с этим можно по-разному. Один из путей подразумевает интеграцию всё более сложных структур на уровне единой кремниевой подложки, а другой — использование мультичиповой (MCM) или, иначе говоря, чиплетной компоновки. К последнему варианту и склоняется NVIDIA, хотя причины несколько отличаются от тех, которыми руководствуются другие вендоры.
GPU и ускорители становятся сложнее гораздо быстрее CPU, и на текущий момент мощные вычислители для ЦОД подбираются к пределам возможностей основных контрактных производителей, таких как TSMC и Samsung. Но это только половина уравнения. Вторая заключается в том, что взрывная популярность систем и алгоритмов машинного интеллекта требует иных вычислительных возможностей, нежели более привычные HPC-задачи.
Как следствие, разработчикам приходится делать выбор, чему в большей мере отдать предпочтение в компоновке новых поколений ускорителей: FP32/64-движкам или блокам, оптимизированным для вычислений INT8, FP16 и прочих специфических форматов. И здесь использование MCM позволит скомпоновать конечный продукт более гибко и с учётом будущей сферы его применения.
Ещё в публикации NVIDIA от 2017 года было доказано, что компоновка с четырьмя чиплетами будет на 45,5% быстрее самого сложного на тот момент ускорителя. А в 2018-м компания рассказала о прототипе RC 18. В настоящее время известно, что технология, разрабатываемая NVIDIA, носит название Composable On Package GPU, но в отличие от прошлых исследований упор сделан на обкатке концепции различных составных ускорителей для сфер HPC и машинного обучения.
Симуляция гипотетического ускорителя GPU-N, созданного на основе 5-нм варианта дизайна GA100, показывает довольно скромные результаты в режиме FP64 (12 Тфлопс, ½ от FP32), но четыре таких чиплета дадут уже солидные 48 Тфлопс, сопоставимые с Intel Ponte Vecchio (45 Тфлопс) и AMD Aldebaran (47,9 Тфлопс). А вот упор на FP16 делает даже один чип опаснейшим соперником для Graphcore, Groq и Google TPU — 779 Тфлопс!
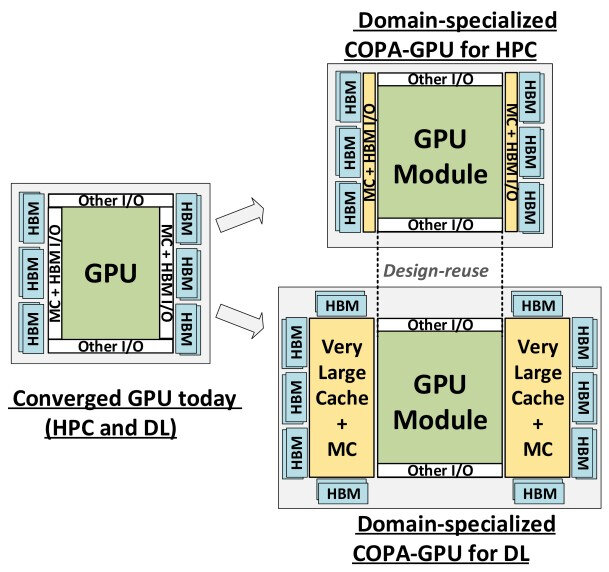
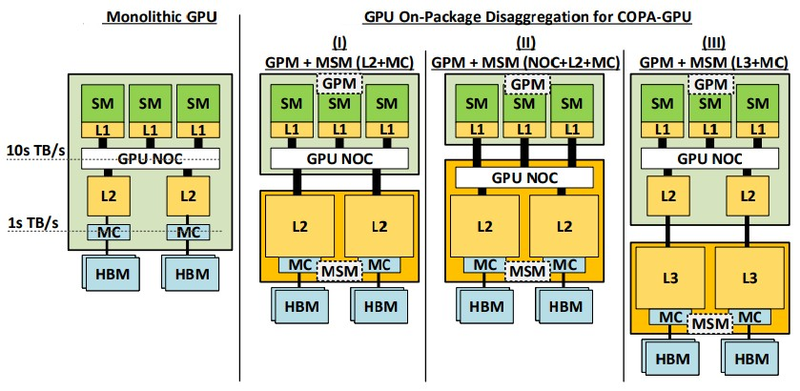
Но симуляции показывают также нехватку ПСП именно на ИИ-задачах, так что компания изучает возможность иной иерархии памяти, с 1-2 Гбайт L2-кеша в виде отдельных чиплетов в различных конфигурациях. Некоторые варианты предусматривают даже отдельный ёмкий кеш L3. Таким образом, будущие ускорители с чиплетной компоновкой обретут разные черты для HPC и ИИ.
В первом случае предпочтение будет отдано максимальной вычислительной производительности, а подсистема памяти останется классической. Как показывает симуляция, даже урезанная на 25% ПСП снижает производительность всего на 4%. Во втором же варианте, для ИИ-систем, упор будет сделан на чипы сверхъёмкого скоростного кеша и максимизацию совокупной пропускной способности памяти. Такая компоновка окажется дешевле, нежели применение двух одинаковых ускорителей.
Подробнее с исследованием NVIDIA можно ознакомиться в ACM Digital Library, но уже сейчас ясно, что в обозримом будущем конвергенция ускорителей перейдёт в дивергенцию, и каждая эволюционная ветвь, благодаря MCM, окажется эффективнее в своей задаче, нежели полностью унифицированный чип.



















