Миллионы людей по всему миру взаимодействуют с бизнесом с помощью текстовых сообщений. Если их два-три в день, то разбить сообщения по категориям сможет обычный менеджер или секретарь. Но если обращений гораздо больше, могут возникнуть определенные трудности. Разберем способы автоматизации этой работы.

Существует множество каналов коммуникации: электронная почта, форма обратной связи и онлайн-чат на сайте, социальные сети, мессенджеры, форумы, а также общение по телефону с оператором, в результате которого будет оформлена запись в виде текста в системе учета клиентов (CRM).
Вне зависимости от источника и тематики текстовых сообщений, важно их своевременно категоризовать, т.е. разделить на категории и направить на рассмотрение в соответствующий отдел или подразделение. Большинство обращений можно отнести к следующим категориям:
- Жалобы. Не всегда удаётся понять истинные желания клиента и удовлетворить его потребности. Если не принять меры, это может привести к негативу, оттоку клиентов или к судебным разбирательствам.
- Обращения в службу поддержки. Пользователи того или иного продукта сталкиваются с различными проблемами. Клиентоориентированному бизнесу важно оперативно дать обратную связь и разрешить возникшую проблему.
- Отзывы. Это источник ценной информации для бизнеса, опираясь на которую можно значительно повысить эффективность работы.
- Предложения о сотрудничестве. Подобные сообщения во многих случаях содержат спам, который надо отделять от реальных выгодных предложений.
- Обзоры. Эксперты часто описывают опыт использования того или иного продукта. Это можно использовать для поиска «слабых» мест и исправления недостатков.
- Автоинформирование. Различные популярные сервисы (например, «Яндекс Директ», «Google Adwords», «2GIS») регулярно рассылают оповещения. Их необходимо перенаправлять в соответствующие службы.
С задачей категоризировать два-три обращения в день хорошо справится менеджер или секретарь. Но что делать, если текстовых обращений гораздо больше? На помощь приходит автоматизация процесса классификации по текстам сообщений на категории.
Способы категоризации текстовых данных
Разделить текст на категории можно разными способами. Чаще всего для этого задаются жесткие условия поиска по ключевым словам и фразам или используются алгоритмы машинного обучения, нейросети. У данных подходов есть свои достоинства и недостатки.
- Ставя жесткие условия для присвоения категорий, можно достаточно быстро реализовать логику решения. Основой для этого послужат регулярные выражения, позволяющие найти в тексте ключевые слова, благодаря которым сообщения с уверенностью можно отнести к той или иной категории. Например, для категории «Бухгалтерия» это может быть фраза «Акт сверки».Недостатки подобного подхода очевидны: нужно заранее задать названия категорий и предопределить строгие правила соответствия. К тому же, придётся постоянно актуализировать перечень ключевых слов для категоризации, прорабатывать синонимы и различные варианты написания. С ростом числа категорий и количества обращений точность будет стремительно снижаться. Дополнительной проблемой станут и нестандартные ситуации, когда слова-индикаторы косвенно используются в контексте другой категории обращения. Учитывая всё вышесказанное, данный метод может быть применим только при анализе небольших объемов данных.
- Категоризация текстовых сообщений с помощью алгоритмов машинного обучения или нейросети более гибкий и практичный подход по сравнению с использованием жестких условий отбора. В этом случае повышенные требования предъявляются к объему данных, используемых для тренировки. Выборки по каждой категории распределяются равномерно. Также желательно произвести предварительную очистку текстовых данных, отсеяв малозначимые слова.
Использование алгоритмов машинного обучения и нейросети связано с определенными сложностями. Например, чтобы решение выдавало высокую точность при делении на категории, выдвигаются определенные требования к навыкам и знаниям аналитика, осуществляющего отбор данных и тренировку (обучение) модели. При этом часто с уходом специалиста из компании алгоритм машинного обучения или нейросеть начинают «жить своей жизнью», а любое внесение изменений в работу решения чревато последствиями.
Алгоритмы машинного обучения и нейронные сети чувствительны к выбросам в данных. Поэтому отдельная проблема перед разработчиком заключается в обеспечении высокого качества данных. Это усложняет процесс предобработки и подготовки к анализу текстовых данных.
Проанализировав все возможные способы деления текстовых данных на категории, в компании Loginom разработали гибкое и простое решение, позволяющее реализовать подобную функцию без знания языков программирования, алгоритмов машинного обучения и нейронных сетей.
Ограничение использования
Чтобы решение по категоризации выдавало высокую точность необходимо иметь достаточный объем данных. Выборки по категориям должны быть сбалансированными. В отличие от алгоритмов машинного обучения и нейросетей, для того чтобы осуществить категоризацию текстовых сообщений достаточно иметь небольшой набор данных. В зависимости от специфики, иногда и 300 записей для каждой категории вполне достаточно для получения ощутимого результата (точность прогноза может достигать более 50%).
Тем не менее, чем больше текстовых данных будет использовано для анализа, тем выше будет точность категоризации. Так, имея в выборках более 10 000 записей для каждой категории, можно получить высокое качество прогноза, сопоставимое с упомянутыми ранее сложными алгоритмами. Если имеются отклонения между объемами данных в выборках можно произвести операцию сэмплинга.
Категоризация текста на основе статистики
За основу был взят частотный анализ слов по методу TF-IDF, используемый для оценки важности слова в контексте категории и всего объема текстовых данных в целом. Чем чаще слово употребляется в контексте одной категории, тем выше вероятность того, что текстовое сообщение должно быть приравнено к ней. Таким образом, в отличие от использования регулярных выражений для классификации сообщений, для оценки соответствия используются не отдельные слова, а весь текст в целом.
При этом следует также учитывать часто употребляемые слова, которые встречаются практически во всех категориях. По ним нельзя делать выводы при прогнозировании категории назначения. Влияние часто употребляемых слов должно быть минимизировано или они должны быть исключены вовсе.
Приведём пример. Всего во всей выборке содержится 2000 слов, 1000 слов в категории «Бухгалтерия», 500 слов в категории «Техническая документация», 500 слов в категории «Прочее». Среди них слово «акт» встречается 100 раз в категории «Бухгалтерия» и 20 раз в категории «Техническая документация». В «Прочих» данное слово не встречается. Для наглядности все дальнейшие расчёты указаны в таблице.
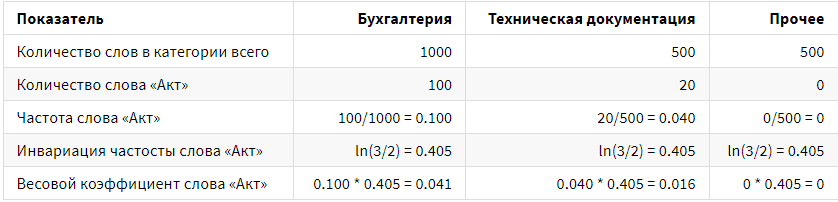
Таким образом, с помощью простых математических расчётов можно быстро определить «популярность» слов для категорий.
Каркас решения для категоризации текстовых сообщений в Loginom состоит из двух модулей:
- построение модели классификации (категоризации);
- прогон данных через построенную модель.
Построение модели классификации (категоризации)
Основное назначение модуля «Построение модели классификации (категоризации)» — анализ частоты употребления слов для категорий и определение весовых коэффициентов. На вход подаются данные, содержащие уникальные идентификаторы, исходные категории, тексты сообщений. Источником данных могут служить Excel-таблица, база данных, CRM-система. Важно, чтобы данные были корректными и правильно размеченными (соотнесены категории и тексты сообщений).
Рабочий процесс обработки данных включает в себя следующие стадии: Препроцессинг, Верификация, Исключение редких значений, Токенизация, Определение частоты слов для категорий, Построение модели.
Основное назначение подмоделей представлено в таблице ниже.
После построения модели категоризации текстовых данных, мы получаем сведения о популярности слов для каждой категории. Пример того, что получается на выходе представлен в виде таблицы и гистограммы. В качестве показателя используются весовые коэффициенты (TF-IDF).
Несложно заметить, слова «Накладная» и «Счёт» с высокой вероятностью указывают на категорию «Бухгалтерия», а «Отправить» и «Отгрузка» на «Продажи». При этом по одному слову нельзя однозначно делать выводы о принадлежности к категории.
Для реализации решения, выполняющего свою функцию с высоким качеством, важно произвести оценку всех слов, входящих в текст. В случае нашего примера с точки зрения частотного анализа токен «Счёт» помимо категории «Бухгалтерия» часто используется в «Сервисе». Чтобы не допустить ошибку реализуемый сценарий должен анализировать всю имеющуюся текстовую информацию и учитывать вес каждого слова.
Прогон данных через построенную модель
Предобработка и Токенизация включают в себя повторно используемые подмодели Препроцессинг, Верификация данных, Исключения редких значений, Токенизация из предыдущего модуля. Подобный подход позволяет обеспечить гибкость и упростить логику обработки.
Подмодель Тестовая категоризация прогнозирует категорию на основе текстового сообщения. На первый вход поступает информация о весах, рассчитанных на этапе «Построение модели классификации (категоризации)», на второй — информация в виде идентификатора и разбитого на отдельные слова текстового сообщения.
В ходе статистического анализа оценивается вероятность попадания текстового сообщения во все возможные категории, в качестве финального значения принимается максимальное. Мерой измерения является суммарный вес по одному ID. Чем он выше для определенной категории, тем наиболее вероятно его соответствие ей.
Подмодель Анализ результата позволяет измерить точность нашего предсказания при прогоне данных. На выход подаются непосредственно предсказанные категории для каждого текстового сообщения по ID, точность прогноза по каждой категории и общая точность в целом для модели.
Анализ результата
При проведении тестового прогона данных была получена точность прогноза категории 75%. При этом имеется возможность значительно улучшить результат за счёт:
- приведения синонимов к единому значению, что снижает разнообразие и повышает надежность использования частотного анализа;
- введения автоматической корректировки орфографии;
- детальной проработки файла с исключениями;
- использование мультиязычной обработки текста, индивидуальной для каждого языка;
- введения дополнительного столбца с указателем части речи (после проведения дополнительного анализа на значимость, можно ввести дополнительные повышающие или понижающие корректировки по данному признаку).
Практически все изменения можно делать на этапе токенизации при разбивке текстов сообщений на отдельные слова.
Как уже было сказано раннее, ключевая особенность данного решения — простота и гибкость. Взяв данное решение за основу, можно быстро реализовать желаемый функционал без сложной нагромождённой логики. Всё что для этого требуется — выборка из корректно размеченных исходных данных.
#анализ данных #текстовые задачи #сегментация