Данная публикация является второй по счету и логически продолжает первую, посвященную азам передачи информации. Автор доступным языком открывает читателю главный секрет информационных систем, их фундамент (основу). Если в первой работе на этот секрет лишь намеки, то здесь намек раскрывается, вероятно, полноценным цветком... Понимание данной основы откроет перспективы адекватного прочтения серьезных (научных) публикаций, откроет, так сказать, дорогу в научный мир!
Часть 1 Помехи отсутствуют
Бросаем кости, получаем информацию
Всем, думается, знаком шестигранный кубик с цифрами от 1 до 6. Подбрасывая кубик мы каждый раз независимо получаем случайное целое число в диапазоне [1, 6]. Данный процесс есть процесс получения информации, как бы банально это ни выглядело. Что означают эти числа - не так уж и важно, это чисто человеческий контекст. Например, числа могут указывать на человека (как на элемент некоторой группы), которому выпадает обязанность сходить сегодня в магазин, при этом если людей больше шести, то потребуется больше бросков.
Упражнение: сколько человек можно "обслужить" двумя бросками?
Какое число выпадет после броска, заранее сказать нельзя, поэтому говорят, что перед броском (перед опытом) существует неопределенность. После выпадения конкретного числа (после опыта) неопределенность снимается (в данном случае полностью). Говорят при этом, что получено количество информации, равное величине снятия неопределенности.
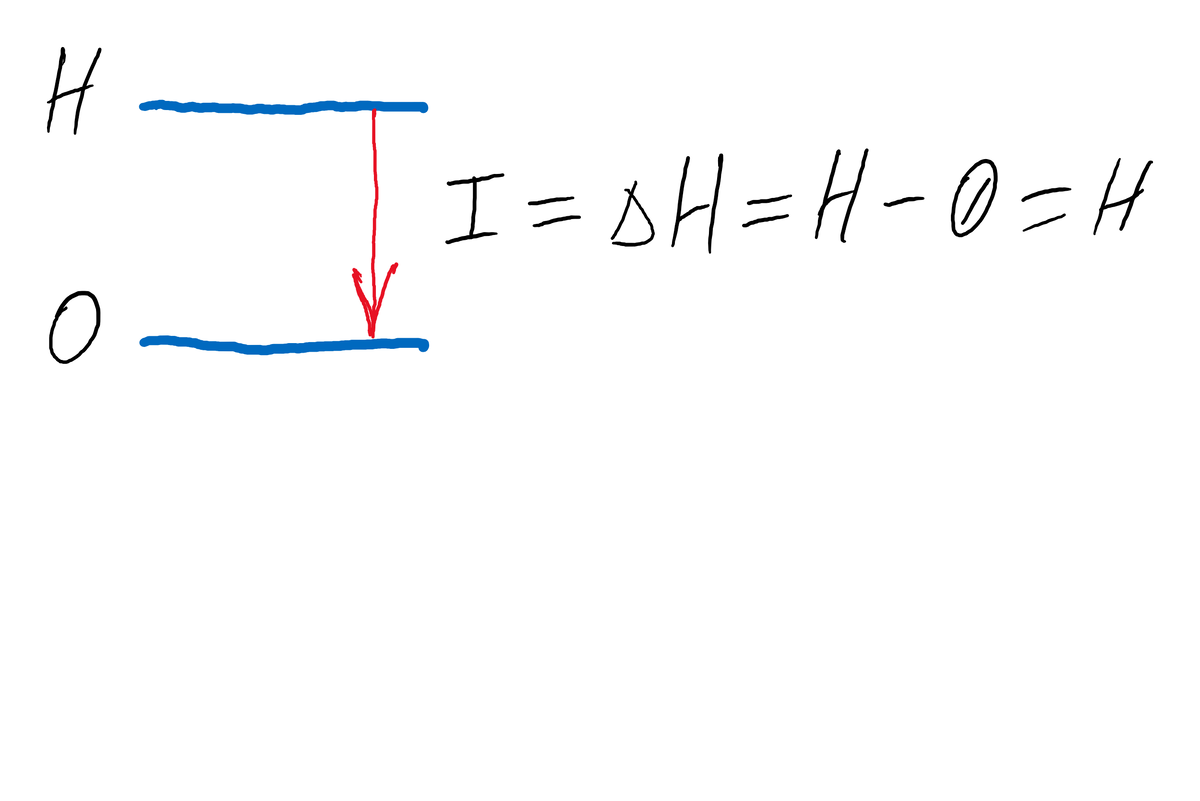
Каждая грань кубика одинаково возможна, при этом говорят, что наблюдаемые числа [1, 6] равновероятные. Их вероятность, как вы наверное догадались, равна 1:6, то есть один шанс из шести. Математически эту вероятность выражают в виде дроби 1/6 (это примерно 16%). Если просуммировать все вероятности, то сумма будет равна единице. Это фактически закон для полной группы - группы, в которой перечислены все возможные исходы.
Одинаковая вероятность всех событий, очевидно, дает минимальный шанс на правильное угадывание исхода (каждый бросок независим от других), значит неопределенность в данном случае максимально возможная.
Превращение вероятности в количество битов
Количество информации принято выражать в битах на одно событие (на один исход). В первой статье это количество очевидно (как длина равномерного двоичного кода), но в данном случае ситуация сложнее. Как превратить вероятность в длину кода? Это основной секрет теории информации.
Допустим, кубик состоит из 8 граней, тогда каждое число [1, 8] можно представить равномерным кодом длиной 3 бита: 1 = 000, ..., 8 = 111. Здесь, заметим, не важно математическое равенство, здесь важна взаимная однозначность соответствия (для математического равенства следует вычесть единицу). Рассмотрев 8-гранный кубик, убеждаемся, что вероятности 1/8 соответствует ровно 3 бита информации. Что же делать с другими вероятностями?
Конечно, всегда можно округлить, и для 6-гранного кубика использовать 3-х битовые кодовые векторы. Но теория на то и теория, что должна быть предельно точной (абстрактной), дабы делать далеко идущие выводы, ведь ситуация не ограничивается простым кубиком.
На помощь приходит комбинаторика. Как мы получили 3 бита/символ в предыдущем примере? Ответ знает каждый школьник: потому что 8 = 2**3, то есть N = m**n - число кодовых векторов равно основанию кода в степени длины кода.
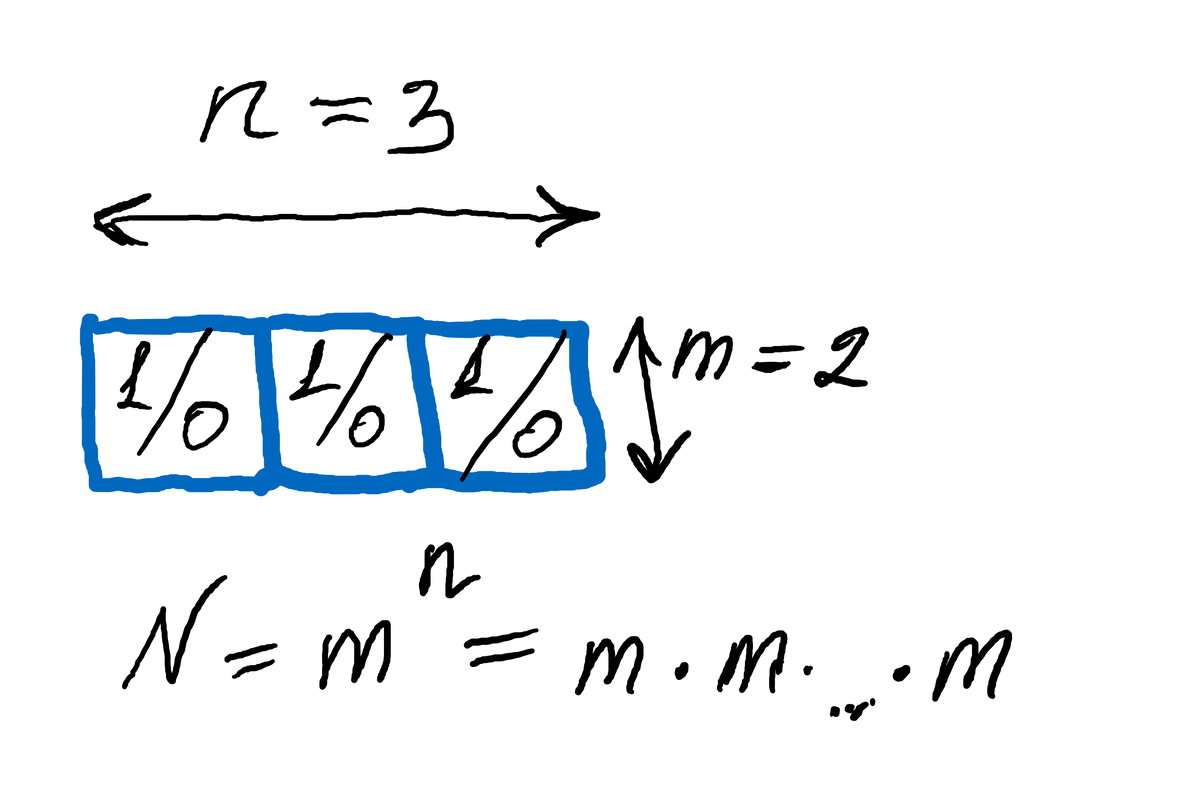
Очевидно, что число 6 нельзя представить как целую степень двойки. Но, опять-таки, ответ очевиден для школьника старших классов:
log(8) = 3 log(2) = 3,
значит log(6) = n = 2,585 бит (то есть 2 в степени 2.585 равно 6). Получается, для кодирования исходов 6-гранного кубика теоретически необходим код длиной несколько больше чем два с половиной бита - ответ дробный...
Упражнение: придумайте однозначно декодируемый код для кодирования 6-гранного кубика, но так, чтобы средняя длина кода была бы меньше 3. Подсказка: код должен быть неравномерный, например как {0, 10, 110}; лучший результат (при побуквенном кодировании) - 16/6 = 2.667 бит. Код должен декодироваться однозначно при отсутствии пробелов и других разделительных символов! Лучше придумать несколько кодов.
Делаем вывод: для кодирования N-гранного кубика требуется log(N) битов (логарифм по основанию 2).
Как же быть, если грани кубика выпадают с разной частотой, то есть имеют произвольные вероятности? Возникает соблазн закончить повествование и дать шанс читателю совершить "квантовый скачок", и заново открыть известные законы... но формат статьи предполагает некоторую концовку.
Так как вероятность выпадения грани p = 1/N, то число N - это обратная вероятность 1/p = N, значит комбинаторную формулу n = log(N) можно легко расширить (обобщить) до n = log(1 / p). А так как n - это по смыслу количество информации I, то
Свойства введенной величины "собственная информация":
- Если основание логарифма равно двум, то количество информации измеряется в битах - двоичных символах.
- Если вероятность равна единице, то событие одно и оно достоверное, а количество получаемой информации при наступлении этого события равно нулю (такое событие нет смысла кодировать).
- Чем менее вероятно некоторое событие, тем больше информации мы получаем при его наступлении, то есть тем более длинный кодовый вектор мы ожидаем получить.
Здесь необходимо четко отличать теорию от практики. Если I вычислять по формуле, то получается длина кодового вектора идеального кода; практический же код будет отличаться от идеального, но в редких случаях может совпадать (здесь важны длины кодовых векторов). Совпадение будет при условии, что все вероятности кратны отрицательным степеням двойки, например, в случае ансамбля {1/2, 1/4, 1/8, 1/8}. Более того, практический код вообще не обязан быть экономным! Экономным обязан быть лишь теоретический код.
Предел, к которому необходимо стремиться, если мы хотим сэкономить на среднем количестве затрачиваемых битов, это log(1/p), то есть длина l[i] кодового вектора c[i] для символа (или даже сообщения) x[i], возникающего с вероятностью p(х[i]) должна быть log(1 / p(x[i])).
Естественно, что для каждого i величина информации может быть разной, и чтобы охарактеризовать источник в целом, вычисляют среднее значение собственной информации:
Данную величину также называют энтропией H(X) источника X. Измеряют в бит/символ (логарифм двоичный). Максимум энтропии равен log(N), что соответствует случаю равных вероятностей символов: говорят, что неопределенность такого источника наибольшая.
Упражнение: в каком случае энтропия равна нулю?
Подводя итоги двух параграфов, скажем, что мы численно определили количество информации, получаемое при полном снятии неопределенности, т.е. в процессе идеального наблюдения источника.
Вопрос: что будет при неполном снятии неопределенности? Этому посвящена следующая заметно более сложная часть.
Часть 2 Нам мешают помехи
Канал с помехами
Информационный канал удобно представить как черный ящик с одним входом X и одним выходом Y. Величины X и Y - это ансамбли (наборы) возможных сообщений, x[i], y[j]. Но фактически это один и тот же ансамбль, потому что основная цель систем передачи информации - обеспечить максимальную достоверность передачи информации с заданной скоростью. Совпадение алфавитов позволяет утверждать, что если i = j, то произошел верный прием, то есть x[i] = y[i]; если же i не равно j, то произошла ошибка (произошел ошибочный переход). В канале без помех всегда i = j.
Естественно, что для оценки качества канала (то есть для оценки общей вероятности ошибки) должны быть определены вероятности всех ошибочных переходов p(y[j] / x[i]), i не равно j. Здесь после знака "косой черты" идет причина (передаваемый символ, вход канала), а перед знаком черты стоит следствие (принятый символ, выход канала). Такую вероятность называю условной вероятностью. В первой части рассматривались безусловные вероятности, p(x[i]), когда всегда i = j.
В канале с ошибками теоретически возможны любые сочетания пар (x[i], y[j]). На данную систему удобно смотреть как на некий автомат, меняющий свои состояния через определенный интервал времени T (говорят: частота следования символов равна 1/T). Если символы слева и справа совпадают, то ошибка отсутствует; если же символы различаются, то ошибка присутствует.
Левая часть канала характеризуется источником сообщений, определяемым вероятностями p(x[i]), которые естественно не зависят от свойств канала. Такие вероятности называют доопытными или априорными. Те вероятности p(y[j] / x[i]), которые получаются после опыта - приема символа из канала, - называются апостериорными (послеопытными, канальными).
Верно следующее:
- сумма всех p(x[i]) равна единице как отражение полноты источника X
- для любого фиксированного i сумма p(y[j] / x[i]) по всем j равна единице как отражение полноты условного источника Y (условием здесь выступает i = const)
В качестве примера канала с ошибками можно привести дорожную ситуацию. В распоряжении водителя есть три сигнала светофора: красный, желтый и зеленый, условно {0, 1, 2}. В результате опыта (наблюдения) водитель, ввиду усталости, может принять неправильное решение. В данном случае решение состоит из двух вариантов: остановиться или проехать, условно {0, 1}, поэтому здесь канал отображает три символа в два, то есть число входов не обязано быть равно числу выходов! Естественно, что 0 чаще переходит в 0, а 2 в 1; что же касается 1 (желтый), то здесь видимо вероятность равна 1/2 ("50 на 50").
Взаимная информация
Взаимность в данном случае понимается как отношение между входом канала и его выходом. Наблюдая выход Y, можем сделать некоторое предположение о входе X: если канал без ошибок, то наблюдение выхода y[i] однозначно дает информацию о входе, и в этом случае послеопытная вероятность x[i] равна единице, p(x[i] / y[i]) = 1; если канал с ошибками, то информацию мы получаем неполной, и p(x[i] / y[i]) < 1, то есть существует ненулевая вероятность того, что на входе не x[i], а x[j], p(x[j] / y[i]) > 0.
Имея две вероятности, некоторую послеопытную p(x[i] / y[j]) и доопытную p(x[i]), можем составить их отношение: если после опыта вероятность x[i] возросла, то опыт y[j] дал некоторое количество информации об x[i]; если вероятность уменьшилась, то опыт был дезинформирующим (отрицательная информация, канал склонен к инверсии); если же вероятность не изменилась, то опыт был бесполезным (нулевая информация). Так вот, логарифм отношения этих вероятностей и дает взаимную информацию:
Взаимная информация устроена так, что нет разницы который символ первый, а который второй - поэтому она так и названа.
Упражнение: на основании теоремы умножения теории вероятностей доказать взаимность взаимной информации, т.е. что I(x; y) = I(y; x).
Теорема умножения теории вероятностей: p(x, y) = p(x)p(y/x) = p(y)p(x/y).
Вопрос: если вероятности в числителе и знаменателе равны, то чему равна взаимная информация и каков смысл этого события?
Для конкретных сочетаний (i, j) могут получаться разные величины взаимной информации, поэтому чтобы охарактеризовать канал (с источником) в целом, вычисляют среднюю взаимную информацию:
Для канала без помех p(x[i] / y[j]) равно 1 для i = j, и равно 0 в противном случае, а p(x, y) = p(x) для i = j, поэтому взаимная информация переходит в величину энтропии H(X) - говорят, что потери отсутствуют.
Упражнение: в каком случае средняя взаимная информация равна нулю?
В канале же с помехами I < H, а величина потерь равна H - I. Естественно желание минимизировать потери, которые можно выразить через так называемую условную энтропию - ту неопределенность об источнике X, которая остается после наблюдения выхода Y:
Упражнение: убедиться, что определение условной энтропии через разность H - I дает выше приведенную формулу H(X/Y).
Конечно, чем лучше канал, тем меньше потери, но для фиксированного канала минимизации потерь можно добиться надлежащим формированием источника - соответствующим кодированием. Однако, это совершенно выходит за рамки статьи и требует основательного погружения в серьезную литературу.
Минимизации потерь соответствует максимизация взаимной информации: C = max I(X; Y), максимизация подбором источника X - согласование источника с фиксированным каналом. Величину C называют пропускной способностью канала. Часто пропускная способность достигается максимизацией энтропии источника, т.е. лучшим его сжатием - экономным кодированием (компрессией).
Подводя итог второй части, скажем, что процесс передачи информации характеризует взаимная информация, которую также называют скоростью передачи информации, максимум которой называют пропускной способностью канала.
Скорость передачи информации следует отличать от технической скорости - от количества физических битов в секунду, ведь техническая скорость определяет скорость на выходе системы передачи информации - на самом ее краю, что зачастую выше скорости на входе из-за частого перевеса избыточного кодирования по отношению к компрессии, а вход как раз-таки характеризует то, что передает потребитель (абонент).