Сегодня в статье мы разберем методы рендеринга, которые помогут справиться с сложностями в обработке сайтов на JS.
Перед прочтением рекомендуем ознакомиться с нашим прошлым материалом: "Продвижение SPA сайтов. Возможна ли дружба между JavaScript и ПС?".

Основные сложности в обработке сайтов на JS
- Процесс сканирования и переобхода страниц.
- Построение графа внутренних ссылок. Граф ссылок может использоваться для определение важных и неважных страниц, а так же каноникализации — определение оригинальных и дублированных страниц
Решение
Так как Яндекс не умеет рендерить, необходимо это делать за него.
Методы рендеринга JS:
- Рендеринг на аутсорсе.
- Рендеринг на своих серверах.
- Рендеринг на стороне ПС.
Рендеринг на аутсорсе
Можно отдать эту задачу стороннему серверу типа prerender.io.
Минусы:
- зависимость от внешних ресурсов (неизвестно, насколько корректно сделает);
- дороговизна при больших объёмах (за каждую страницу свыше 200 бесплатных – нужно платить деньги).
Рендеринг на своих серверах
- С помощью Headless браузера.PhantomJS , HTML Unit
- Фраймворк с пререндерингом.React, Angular
Минусы:
- высокая нагрузка на сервер — обработка как всех посетителей, заходящих на сайт, так и роботов: нужно держать вторую версию сайта в HTML формате. Из-за этого возникает большая нагрузка, а чем её больше, тем больше платим;
- постоянный мониторинг за кодом ответа сервера, если сервер перегрузится, начнёт выдавать 500 ошибку, страница начнёт вылетать с индекса, следовательно, пользователи перестанут заходить на сайт. Тестирование при всех доработках (на 2 версиях сайта: JS и HTML).
Рендеринг на стороне поисковой системы
Минусы:
- Умеет только Google, но если Яндекс не важен, то можно отдать на откуп ПС (подходит для Буржунета).
- Возможна некорректная обработка, нужен мониторинг за рендерингом и обработкой (просмотр страниц в качестве GoogleBot).
- Сложности при сканировании SEO сканерами (умеет NetPeak Spider).
Выводы по методам рендеринга JS
- Если у вас небольшой сайт используйте аутсорс (до 200 страниц).
- Если не нужен Яндекс и небольшой сайт – отдайте на откуп Google.
- Если большой сайт — используйте свои серверы.
Как передавать HTML код роботу, чтобы поиск о нём узнал?
Существует 3 метода передачи HTML кода.
- Escape fragment.
- Определение поискового робота по user-agent.
Не передаем(не рассматриваем, так как Яндекс в России нужен).
1 метод. Использование — Escape fragment
- # => #! => ?_escaped_fragment_=Есть домен: http://www.example.com/#blog
Мы переводим такие URL’ы в: http://www.example.com/#!blog
Поисковой робот начинает «видеть» такие URL’ы и будет переходить по ним в: http://www.example.com/?_escaped_fragment_=blog
По данному адресу у нас должна располагаться полностью отрендеренная HTML страничка.
Как альтернативное решение используется:
<meta name=»fragment» content=»!»>
Минус – данная технология является устаревшей по мнению Google, так как он научился рендерить с помощью технологии WRS и браузера. Однако для Яндекса технология продолжает оставаться актуальной.
2 метод. Определение по User-agents
- Определяем, что к нам пришёл GoogleBot / YandexBot
- Смотрим IP, который они отдают
- Определяем домен с помощью reverse DNS lookup.
Нужно опознать, действительно ли зашёл робот ПС, или это сканер шифруется под него и хочет нагрузить наши сервера.
По ссылке вы можете найти информацию о том, как это можно сделать: https://yandex.ru/support/webmaster/robot-workings/check-yandex-robots.xml
- Отдаём HTML версию
Что делать, если зайдёт робот «с усами»?
«Робота с усами» мы называет поискового робота, который проверяет сайт на клоакинг.
Клоакинг – это когда поисковой системе отдаётся один контент, а живому пользователю – другой, то есть производится подмена контента. Это «черная» технология продвижения и поиск борется с этим.
Наша задача, определить по User-agent поискового робота и отдать ему HTML формат, а пользователям – JS, в случае если контент идентичный, Яндекс/Google не будет иметь претензий, так как клоакинга нет.
Как учитываются поисковые факторы?
В Яндексе они наиболее актуальны, чем в Google. Однако на этот вопрос нет однозначного ответа, так как пользователи фактически изучает сайт на JS, а роботы – на HTML, соответственно они находятся на различных страницах.
Наше мнение, что основным поведенческим фактором является внешние поведенческие факторы в SERP.
Для сбора корректной статистики и учета всех возможных факторов, мы рекомендуем внести дополнительные настройки:
Что такое хорошее SEO?
SEO => упрощение работы поисковым системам.
Задача оптимизатора:
- Ускорить сканирование
- Упростить индексацию
- Усилить ранжированиеструктура сайта
состав страницы
доверие и авторитет
Технология SPA сайтов усложняет работу поисковых систем, так как «страдает» процесс индексирования, и приходится рендерить страницы, собирать отдельно статистику.
Пример реального продвижения SPA сайта
Кейс: сайт-агрегатор одежды.
На сайте более 3 млн. страниц, каталог имеет наполнение:
- 100 интернет-магазинов
- 20 000 брендов одежды
- 3 млн. товаров
Монетизация — заработок на комиссии с продаж по партнёрским программам интернет-магазинов.
Используемые технологии:
AngularJS и за счёт PhantomJS — передаётся JS и обрабатывается в HTML.
Передача HTML происходит с помощью рендеринга по User-agent.
Мы определяем, кто запрашивает страницу, если это GoogleBot или YandexBot, мы отдаем ему версию HTML.
У сайта изначально была плоская структура: главная страница и подразделы.
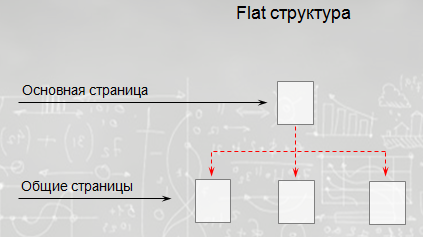
Структура не разветвлённая, созданы только общие разделы:
Основные этапы продвижения:
- Собрали объемную семантику;
- Спроектировали структуру на её основе;
- Провели технические работы по подготовке к сканированию и индексации;
- Размещение ссылок на сторонних ресурсах.
Технический аудит положил начало работе. В процессе найдено около 230 ошибок, в связи с чем программистам пришлось вносить множество доработок и приводить к стандартам требуемыми поисковыми системами.
Далее мы проанализировали спрос, разобрали пользовательские интересы, провели группировку запросов и построили новую структуру, состоящую из категорий, подкатегорий; признаков и свойств и конечных посадочных страниц.
Мы применили технологию оптимизации при помощи SEO фильтров.
Благодаря очень раздробленной структуре и проработке всех потребностей пользователя — получили максимальный охват аудитории.
Основная сложность проекта
Крайне сильно «страдала» индексация новых посадочных страниц.
В тематике одежды преимущественно категорийный спрос, то есть люди ищут, например, «кроссовки Adidas» и в меньшей степени конкретные артикулы.
В ходе продвижения мы настроили индексацию таким образом, чтобы специально исключить незапрашиваемые карточки товаров. Улучшили индексацию на категорийных страницах, и трафик начал расти.
Итог по этому кейсу: рост трафика в 7 раз за 4 месяца.
Вывод о сайтах на SPA:
SPA технология – отличный инструмент, который позволяет сделать много полезного для пользователей.
Её основное применение в основном для внутренних сервисов, где не потребуется индексирование страниц, но нужен интерактив для пользователей.
Мы уже убедились на практике, что применяя SPA можно создавать сайты для продвижения, но в этом случае возникают большие сложности поисковых алгоритмов.
Что вы думаете относительно этой темы? Давайте обсудим в комментариях!
Еще больше статей об интернет-маркетинге и увеличении онлайн-продаж здесь: https://www.trinet.ru/blog/.
Понравилась статья? Поставьте лайк 👍 , оставьте комментарий и подписывайтесь на наш канал.