Почему эта тема актуальна?
В интернете часто обсуждают вопрос о том, можно ли подружить сайты созданные на JavaScript с поисковой системой. Существует много слухов о том, что JavaScript не индексируется поисковой системой, поэтому важно развеять или утвердить этот миф.
Из материала вы узнаете, как подружить сайт на JavaScript с поисковой системой, чтобы он индексировался и высоко ранжировался.
Кому будет полезна данная информация?
- владельцам бизнеса, маркетологам (экономия от 300-500 тысяч на разработку);
- SEO-специалистам (изучите опыт в продвижении данных ресурсов);
- программистам (поймете особенности как сделать сайт, чтобы он продвигался в поисковой системе).

Типы сайтов
Для удобства можно разделить сайты на:
- статический сайт – HTML;
- частично динамический – AJAX;
- динамический сайт – JS (SPA).
Классические HTML сайты
Классические сайты – те, с которыми чаще всего сталкивается любой пользователь в интернете. Браузер отправляет HTTP запрос на сервер и просит сервер «показать» ему HTML + CSS. Сервер отправляет данные, а браузер отрисовывает их.
Сайты, построенные на AJAX
Работают по тому же принципу, что и первая модель, но прибавляется JavaScript. С помощью него прогружаются интерактивные элементы внутри страницы. Например, в интернет-магазине можно прогрузить сортировку товаров или фильтры без перезагрузки страницы.
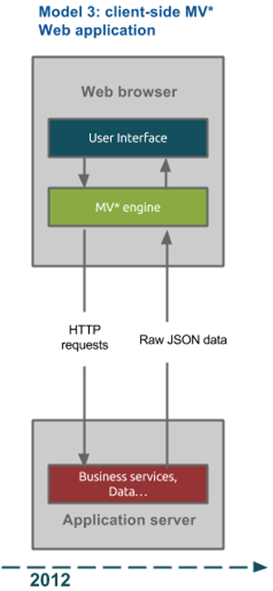
Сайты, построенные на SPA технологии
Полностью интерактивный сайт, построенный на JavaScript.
Далее рассмотрим детально нюансы каждого вида сайтов.
Статический сайт – HTML:
- Частая перезагрузка страниц — каждый раз, когда пользователь обращается к какой-либо странице, браузер отправляет запрос к серверу и она вынуждена перезагружаться.
- Скорость загрузки — в связи с постоянной перезагрузкой файлов, скорость загрузки ниже, по сравнению с другими методами).
- Ограниченная функциональность — нет интерактива, возможного при использовании JS.
Частично динамический сайт — AJAX
AJAX – использование технологий JS и XML.
- Частичная перезагрузка страницы — например, в интернет-магазине можно организовать сортировку товаров уже без перезагрузки страницы.
За счёт этого обеспечивается:
- Более быстрое взаимодействие с пользователем.
- Расширенная функциональность благодаря JavaScript.
Динамический сайт -> SPA
- Нет перезагрузки страниц — внутри сайта всё изменяется на JavaScript.
- Быстрое взаимодействие с пользователем — пользователь не ждёт перезагрузки страницы, контент обновляется динамический.
- Наиболее расширенная функциональность по сравнению с предыдущими видами.
Как организован SPA сайт?
Наш клиент (браузер) отправляет запрос серверу. Сервер первый раз отдаёт HTMLстраничку. Далее всё взаимодействие строится на JavaScript. Для удобства разработки существует JavaScript Framework’и. Фреймворк — ПО, облегчающее разработку сайта.
Наиболее популярные Фреймворки:
- Angular
- React
- Ember
- Polymer
- Meteor
- Backbone
- Vue
- Knockout
В чём основная сложность для поисковой системы в таких сайтах?
Поисковая система не умеет обрабатывать JavaScript сайты. Чтобы обработать JS, требуется JavaScript перевести в HTML, тогда ПС сумеет провести индексацию. Название этой процедуры – рендеринг. Рендеринг JavaScript – это отрисовка JavaScript в HTML формате.
Что говорят поисковые системы о сайтах на JS:
Яндекс утверждает, что умеет рендерить самостоятельно, но только в рамках теста, выборочно и только для некоторых сайтов. Большинства сайтов Яндекс рендерить не умеет! Поэтому, вам необходимо настроить внутренний рендеринг сайта, чтобы Яндекс начал «понимать» его.
Google умеет самостоятельно рендерить страницы, с помощью WRS. WRS – специальная технология рендиринга на основе браузера Google Chrome. При помощи Google Webmaster, вы можно проверить, как Googlebot отрисовывает ваш сайт.
Компания MOZ провела исследование и выясняла, умеют ли поисковые системы обрабатывать JS используемые в популярных Фреймворках и составила сводную таблицу. Выяснилось, что лишь Google и Ask (на основании технологии поиска Google) умеют, а остальные поисковики – нет.
Рассмотрим основные этапы работы поисковых систем, где могут возникнуть сложности с SPA.
- Сканирование.
- Индексирование.
- Ранжирование.
Этап 1. Сканирование
Есть поисковой робот (сканер), находит все страницы в интернете и «собирает» оттуда только URL’ы страниц.
Основные задачи:
Найти, сохранить и передать URL’ы. Всё, что находится в <a href=“…”>, он копирует себе в базу, упорядочивает и передаёт данные следующему роботу-индексатору.
- Определить приоритеты сканирования (на какие страницы нужно заходить чаще и проверять обновления, на какие реже).
Сканер не занимается рендерингом (т.е. не может разобрать контент с использованием SPA технологии).
Этап 2. Индексирование
Основные задачи:
- Обойти и обработать URL’ы, которые передал робот-сканер.
- Сохранить всё в индексную базу.
Данный робот занимается рендерингом и умеет это делать.
Пример работы сканера и индексатора
Взаимодействие на HTML сайтах:
Сканер выкачивает URL’ы, передаёт индексатору. Индексатор часть данных отдаёт обратно для приоритезации.
Сложность взаимодействия со SPA сайтами:
Сканер не может обрабатывать URL’ы, которые нашёл на страницах, так как не умеет рендерить. Индексатор берёт на себя ключевую роль сканера. Ему необходимо сначала страницу прогрузить, после узнать о ссылках, которые есть, и только потом он может переходить на следующую страницу. То есть процесс сканирования и индексирования сайта очень сильно замедляется.
Сложность: робот-сканер может обрабатывать только HTML страницы и находить URL’ы в них. Индексатор вынужден всё время рендерить страницы, чтобы получить новую порцию ссылок для робота сканера и передавать их.
Вывод
Основные сложности в обработке сайтов на JS возникают в 2 процессах:
- Процесс сканирования и переобхода страниц.
- Построение графа внутренних ссылок. Граф ссылок может использоваться для определение важных и неважных страниц, а так же каноникализации — определение оригинальных и дублированных страниц.
Например, у нас есть дублированные страницы. Робот прогрузил и видит rel=»canonical» на другую страницу, но на вторую страницу он не зашёл и не знает о информации размещенной на ней, так как не хватило лимита краулингового бюджета.
Краулинговый бюджет – каждому сайту выдаётся определённый лимит на индексацию. Условно – времени работы поисковых роботов, которые обходят сайт. Чем популярнее сайт, чем больше он имеет внешних ссылок, тем больше лимитов предоставляется от поисковой системы.
В SPA сайтах краулинговый бюджет «страдает», так как роботу приходиться прилагать «больше усилий», чтобы обработать сайт.
На следующей недели мы продолжим эту тему.
Еще больше статей об интернет-маркетинге и увеличении онлайн-продаж здесь: https://www.trinet.ru/blog/.
Понравилась статья? Поставьте лайк 👍 , оставьте комментарий и подписывайтесь на наш канал.