На канале Математика не для всех появилась любопытная задачка:

Любопытной она мне показалась, во-первых, потому, что непонятно, откуда мог взяться такой вопрос, а во-вторых, что-то смутно знакомое в ней маячило: очереди, вероятности... В своё время я целую книжку про это написал, так что, понятно было, что "надо брать".
Попытки оценить ход решения в уме (во время прогулки) привели к соображению, что нужно знать распределение людей по высоте, ведь, если оно будет равномерным, то получится один ответ, а если, например, вырожденным (все люди в очереди одинакового роста), то другой, а именно единица. Нужно пробовать и экспериментировать. Так субботняя прогулка привела меня за компьютер и через часик была готова нехитрая программа, моделирующая людей в очереди, как набор чисел. Она честно перебирает все возможные варианты, коих в очереди из n человек будет kⁿ, если люди имеют k различных значений роста, вычисляет количество видимого народа, учитывает распределение людей по росту и ведёт статистику. Удалось просчитать разные варианты и они говорили о том, что, всё-таки, для ответа нам нужно знать то, каким именно будет распределение вероятности для высоты людей. То есть, ответ зависит от этого распределения и одним числом его не выразить. Я даже надыбал кое-какую статистику по длине нынешнего народонаселения, и подставил её в программу и с удивлением обнаружил, что от конкретного выбора распределения ответ меняется, но как-то неубедительно. Гораздо больше на него влияет количество разнообразных вариантов роста. Более того, по мере увеличения числа вариантов, среднее число видимых людей неспешно сходится к некоторому значению, фиксированному для длины очереди.
Размышления о распределениях завели меня несколько не туда куда нужно. А тем временем, Александр Кузнецов уже выдал ответ, причём, несколько неожиданный. Среднее количество видимых людей в очереди, по его версии, оказалось равно гармоническому числу H₈ = 1 + 1/2 + 1/3 + 1/4 + ... + 1/8. Как выяснилось, этот результат был тоже получен с помощью компьютера. Сравнение этого решение с моим показало, что оно верно описывает то самое предельное значение, которое получается в случае непрерывной функции распределения роста людей.
Гармонические числа не так уж часто встречаются в теории вероятностей и в комбинаторике, и я, по-киношному прищурившись сказал: "Мне кажется я знаю этого парня..." Похоже, мы имеем дело с распределением, которое можно считать довольно редким и далёким от популярности, в отличие от нормального, экспоненциального, гамма-распределения и прочей попсы. Но с которым меня связывает давняя история.
С этим распределением я встречался до этого лишь раз, при работе над книжкой Вероятности и неприятности, когда исследовал, почему нам никогда не хватает времени на подготовку отчёта и львиную часть работы приходится впопыхах делать в последний день, а, вернее, в ночь перед сдачей. Тогда мне удалось показать, что количество выполнимых перед дедлайном дел при следовании безалаберной, но весьма естественной стратегии, описывается распределением, имеющим следующий вид:
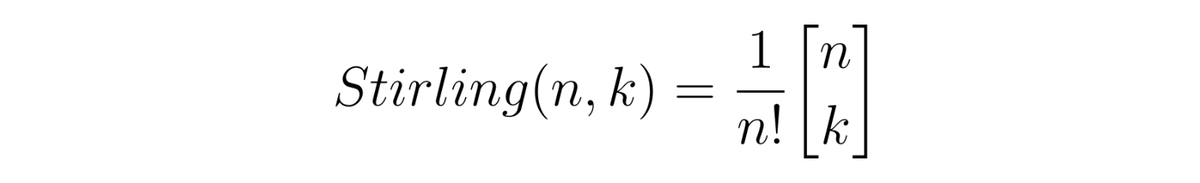
Я даже дал ему имя: распределение Стирлинга, поскольку двухэтажное выражение в квадратных скобках, это известные в теории групп и в алгебре числа Стирлинга первого рода. Позже, научный редактор моей книги, профессор Санкт-Петербургского государственного университета Валерий Борисович Невзоров подсказал мне, что это распределение встречается в описании статистик для рекордных случайных величин.
Рекордной случайной величиной (или просто рекордом) в последовательности случайных величин называется величина, которая превосходит все предыдущие. Вероятность того, что среди n непрерывных случайных величин будет зарегистрировано k рекордов, описывается точно таким же выражением. А ведь это же именно наш случай! Каждый загораживающий впереди стоящих верзила, это очередной рекорд по высоте.
Вот в чём состояла разница между моим подходом и подходом Александра. Я рассматривал варианты всех возможных очередей с людьми, рост которых округлен до некоторых дискретных значений, скажем, с точностью до 5 или 10 см. При этом, в очереди могли оказываться люди с одинаковым (с точностью до округления) ростом. Если мы примем, что рост не округлён и мы имеем дело с непрерывным распределением, то такое совпадение имеет вероятность эффективно равную нулю, а значит, в очереди все люди будут иметь различный рост. В таком случае, уже не важно, как именно он распределён: мы всегда можем ранжировать их по росту и поставить каждому в соответствие натуральное число, сохраняющее отношение порядка.
Таким образом, мы можем забыть о конкретном распределении, лишь бы оно было непрерывным, и свести задачу от перебора kⁿ вариантов, к перебору перестановок из n различимых элементов, которых, как известно, n! штук.
Пусть R(n, k) это количество перестановок из n различных величин таких, чтобы количество рекордов было равно k. Выясним, чему будет равно R(n + 1, k), то есть, сколько будет способов получить k рекордов, если мы добавим ещё одно число, отличающееся от всех остальных. Если его величина превышает все уже задействованные числа, то мы можем поставить его в конце последовательности и количество способов получить k рекордов будет равно R(n, k – 1), k-тым рекордом будет этот последний элемент. Если же его величина оказывается где-то посередине, то существует ровно n способов его поставить так, чтобы в любом из уже рассмотренных R(n, k) вариантов он оказался за каким-нибудь рекордом и не нарушил числа k. Таким образом, получается, что
Если в последовательности один элемент, то R(1, 1) = 1. Кроме того, R(n, 1)=(n – 1)! — столько способов получить ровно один рекорд (самый большой элемент впереди, а за ним все возможные перестановки остальных элементов).
Итак, мы получили рекуррентное соотношение, в точности совпадающее с определением для беззнаковых чисел Стирлинга первого рода! В сумме по k эти числа дают n!, то есть мы рассмотрели все возможные варианты, а значит эти количества можно превратить в вероятности. Выходит, распределение из задачки описывается именно тем самым выражением, что я когда-то вывел для своей книжки! Какая приятная встреча!
Можно показать (индукцией по n), что среднее (первый момент) для этого распределения равен гармоническому числу:
что экспериментально и получил Александр.
Вот ещё что интересно отметить. Числа Стирлинга фигурируют в теории перестановок, а именно отражают количество перестановок, имеющих ровно k циклов. Возникает ощущение, что число циклы и рекорды должны быть как-то связаны. Но если мы посмотрим на то как выглядят перестановки с циклами и рекордами для небольших n, то увидим, что их количества, действительно согласуются, а сами перестановки — нет.
Не знаю откуда взял эту задачку автор канала, но встреча с ней украсила мои выходные!