В комментариях к статье "Цикл (операция) Чтение-Модификация-Запись. Как это работает", в очередной раз, была затронута тема использования стандартных средств компилятора для работы с внешними данными, включая аппаратные ресурсы. Причем проводилась, в некоторой степени, параллель между данными разделяемыми разными потоками или приложениями и данными аппаратными.
Об этом написано многое и многими. В том числе, есть статьи и на моем канале. Но тема действительно сложная и вызывает множество дискуссий и вопросов. Поэтому я решил предпринять еще одну попытку рассказать, как это работает, и почему все так не просто. И почему неверно проводить параллели между работой с разделяемыми данными и аппаратными ресурсами.
Другими словами, статья будет о программировании не прикладном, и даже не совсем системном. Она будет о той тонкой грани, которая связывает работу аппаратуры и программы. Безусловно, это затрагивает далеко не не всех. Можно было бы сказать, что это и интересно то очень мало кому. Но сегодня, когда все больше используются микроконтроллеры, круг тех, кого это касается, стал шире.
И это будет скорее обзорная статья. И несколько сумбурная, скорее всего. Для тех, кто никогда раньше с такими вопросами не сталкивался.
Ссылки на статьи:
Цикл (операция) Чтение-Модификация-Запись. Как это работает
Модификатор volatile в языке С. Об "изменчивости" в реальном мире и "серебрянных пулях".
Процессоры, ядра, машины, комплексы
В сегодняшней статье будет постоянно употребляться термин машина. Безусловно, в общем случае речь идет именно о вычислительной машине. Но почему не просто ЭВМ? В чем то, это дело многолетней привычки привычки. Но не то только. Дело в том, что ЭВМ это именно вычислительная машина, которая когда то занимала целые залы, но постепенно уменьшилась до блока в стойке или даже одной печатной платы в крейте.
ЭВМ может быть управляющей. Но такие машины все равно оставались именно вычислительными машинами. Но со временем появились и встраиваемые ЭВМ. И такая машина уже далеко не всегда использовалась именно для вычислений. Персональные ЭВМ, те самые ПК, всех сортов и мастей. Но и однокристальные ЭВМ, именно так изначально называли микроконтроллеры. Смартфоны, которые уже трудно назвать ЭВМ.
Термин машина является обобщающим. Он включает в себя и аналоговые, и аналогово-цифровые (были и такие), и классические цифровые (ЦВМ), и управляющие, и встраиваемые ЭВМ. И микроконтроллеры, и смартфоны. И даже релейные автоматы.
Конечно, АВМ, АЦВМ и релейные автоматы сегодня рассматриваться не будут. Кстати, термин ЭВМ тоже обобщающий. Он включает в себя АВМ, АЦВМ, ЭЦВМ (именно их обычно имеют ввиду, когда говорят ЭВМ).
Но все это означает, что машины могут быть очень разные. Давайте кратко рассмотрим основные варианты, которые сегодня использоваться в статье. Разумеется, все они будут цифровыми.
Классическая ЭЦВМ, она же ЦВМ, она же ЭВМ
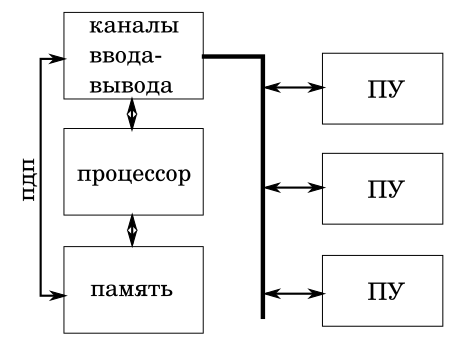
ПУ это периферийные устройства. И, по большому счету, они являются внешними по отношению к собственно ЭВМ. А вот каналообразующее оборудование (контроллеры, канальные процессоры, и т.д.) входит в состав ЭВМ. И все вместе это машина.
ПДП это канал прямого доступа к памяти. Он позволяет внешним устройствам обмениваться с ЭВМ данными не занимая процессор. И, как мы скоро увидим, это тоже может стать источником проблем.
Многопроцессорная ЭЦВМ
Просто так добавить процессоры не получится. Их работу нужно синхронизировать, что бы не возникало конфликтов. В частности, конфликтов при доступе к памяти. Подробности построения многопроцессорных машин нам сегодня не важны. Поэтому просто будем считать, синхронизация обеспечивается специальным устройством синхронизации.
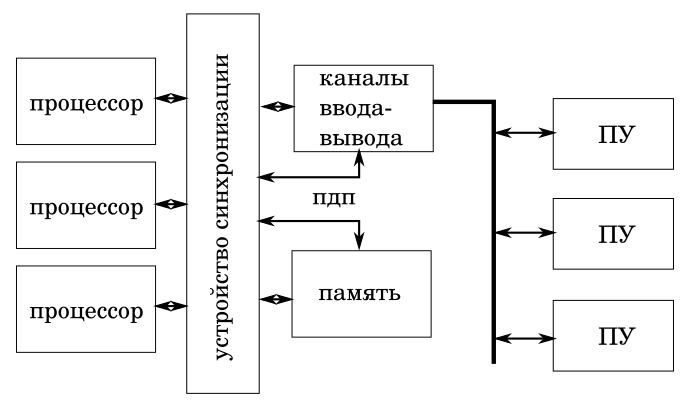
В такой конфигурации память является критическим ресурсом, так как быстродействие машины в основном определяется быстродействием памяти. Ведь все процессоры выполняют программы хранящиеся в памяти. И данные хранятся там же.
Однако, и коды программ, и данные, обрабатываемые разными процессорами, обычно располагаются в разных областях памяти. А значит, мы можем избежать, по крайней мере, части, конфликтов разбив память на отдельные блоки. А устройство синхронизации будет отслеживать запросы доступа разрешая одновременный доступ разных процессоров к ячейкам памяти в разных блоках.
Такая организация доступа к общей памяти называется многопортовой памятью. Она не позволяет полностью избежать конфликтов, но значительно повышает общее быстродействие машины снижая влияние быстродействия памяти.
Другим способом повышения быстродействия машины является введение дополнительных блоков памяти небольшого объема для каждого отдельного процессора. Такую память обычно называют кэш памятью. В кэш память позволяет обращаться к основной памяти для обмена целыми блоками, а не отдельными байтами (словами).
Кэш подключается к процессору через специальный контроллер. Я не буду отдельно иллюстрировать эту конфигурацию.
Обратите внимание, что в многопроцессорной машине каналы ПДП не работают с памятью напрямую. Любой доступ к памяти должен осуществляться только через устройство синхронизации. На самом деле, синхронизация требуется в однопроцессорных машинах.
Многоядерные процессоры
Если объединить несколько процессоров, вместе с кэш памятью и устройством синхронизации, в единое целое, то мы получим многоядерный процессор.
Конфигурация многоядерных процессоров может быть различной, очень различной. Обычно, ядра размещают на одном кристалле, или в одном корпусе. Что позволяет значительно уменьшить размер машины. Кроме того, многоядерный процессор часто строится по более простой схеме, чем многопроцессорная машина.
Для нас детали сегодня не важны. Мы можем считать, что многопроцессорная машина и машина с многоядерным процессором практически одинаковы. Разумеется, машина может содержать и несколько многоядерных процессоров.
Однако, одно небольшое отличие, важное для нас сегодня, все таки есть. Многопроцессорная машина может работать под управлением нескольких ОС (операционных систем) одновременно. Это далеко не самый распространенный случай, но такое бывает. Машины с многоядерными процессорами обычно работают под управлением одной ОС. Не смотря на то, что теоретически разные ядра могут выполнять разные ОС, такое практически не встречается. из-за архитектурных особенностей многоядерных процессоров.
Запуск разных ОС на разных ядрах возможен под управлением гипервизора. Но в этих случаях говорят о виртуальных машинах. Этот вопрос выходит за рамки сегодняшней статьи.
Многомашинный комплекс
Несколько машин, причем разных, могут быть объединены в единый комплекс. Это можно сделать различными способами. Причем далеко не только с использованием сетей, как сегодня думают очень многие.
Классический многомашинный комплекс использует специальные каналы связи, которые ближе системным шинам. И такие каналы связи могут иметь и собственную общую память, и собственные общие периферийные устройства
Чем нам сегодня интересен многомашинный комплекс? В первую очередь, именно этим общим, межмашинным, блоком памяти. Причем эта память может просто отображаться на часть адресного пространства каждой машины. То есть, с точки зрения прикладной программы, эта память будет неотличима от памяти машины. Все дополнительные заботы возьмет на себя аппаратура межмашинного интерфейса.
Операционные системы, многозадачность, многопоточность
Операционная система является связующим звеном между оборудованием машины и прикладной программой (задачей). Точнее, таким связующим звеном являются драйверы оборудования, входящие в состав ОС.
Но драйверы это лишь малая часть ОС. Значительную часть составляют механизмы управления задачами (переключение, синхронизация, и т.д.), механизмы безопасности и доступа, высокоуровневые сервисы (например, сетевой стек). Подробности архитектуры ОС нас сегодня не интересуют, но некоторые моменты кратко рассмотрим.
Кстати, ОС без драйверов тоже существует. В своем простейшем варианте такой ОС можно считать программы-мониторы, которые использовались в первых ПК вроде "Радио-86РК", "Микро-80", и им подобных, включая зарубежные.
BIOS в IBM/PC наоборот, можно считать лишь набором простейших драйверов, без системного сервиса. Не смотря на то, что BIOS обеспечивает и интерфейс с пользователем, и загрузку ОС, сам его ОС считать нельзя.
Однозадачная ОС
Простейший вариант ОС, который сегодня можно встретить очень редко. По сути, это программа-монитор с небольшим набором драйверов. Она позволяет запускать только одну задачу, но предоставляет ей небольшой системный сервис. При этом есть возможность загрузки дополнительных драйверов внешних устройств.
Но для нас самым важным является именно однозадачность. На первый взгляд, это полностью избавляет от проблем совместного доступа к разделяемым ресурсам. Но все не так просто!
Да, в данном случае программа (задача) работает только со своими собственными данными, другой, параллельной, задачи просто не может быть. Или может? А ведь действительно может! Сама ОС это именно параллельная задача. Как и любой драйвер, который работает по прерываниям.
Проблем не возникнет, если прикладная задача получает доступ к ресурсам ОС только через специально предусмотренные запросы к ОС. Такими ресурсами являются, например, текущие дата и время, файловые буферы, системные таблицы. Любая попытка прямого доступа, игнорируя ОС, может привести к ошибке.
Вспомните MS-DOS, сколько программ работало с ее внутренними областями памяти напрямую... При соблюдении строгих правил это было, пусть и условно, безопасно. Запрет прерываний не единственное условие, и сама ОС должна при этом быть в устойчивом состоянии. Это требовало дополнительных проверок.
Вся забота о синхронизации в таких системах лежит на программисте, если он решает игнорировать механизмы ОС. На программисте же лежит обеспечение бесконфликтного доступа к разделяемым сетевым ресурсам. Но эти случаи нам сегодня не интересны.
Но нам интересна работа с аппаратными ресурсами. Пока предположим, что прикладная программа не работает непосредственно с оборудованием. Но это не избавляет от некоторых нюансов...
Например, программа создала буфер для работы с диском, зарезервировала для него место в памяти. Работа с диском выполняется через ОС, что безопасно (на первый взгляд). Но при обращении к ОС для чтения/записи буфера программа может запросить асинхронное выполнение запроса. Или такое поведение подразумевается ОС по умолчанию. И мы получим параллельное выполнение прикладной программы и ОС (драйвера).
Вы наверняка скажете, что программист (прикладной!) должен знать об особенностях ОС и самостоятельно отслуживать необходимы флаги и статусы. И будете правы. Только вот универсальный язык высокого уровня, и его компилятор, не окажут программисту никакой поддержки. Никакие std::atomic (С++) или _Atomic (С) не помогут.
Немного изменим наш пример. Пусть программа работает с контроллером диска напрямую. Теперь у нас исключено влияние ОС и драйвера. Но ведь диск может работать, например, только с использованием ПДП. И мы опять получаем конкурентный доступ к буферу в памяти! Только теперь не две программы выполняются параллельно (псевдопараллельно, процессор то один), программа работает параллельно каналу ПДП, аппаратному средству.
И мы опять должны, вручную, отслеживать флаги, только теперь оборудования. И опять ЯВУ нам никакой поддержки не окажет. Да, обычный прикладной программист вряд ли будет работать с диском минуя ОС (хотя чудеса иногда случаются), но это не отменяет того, что программист будет бороться с оборудованием "в рукопашную".
Многозадачная ОС, один процессор
Многозадачная ОС не всегда будет и многопользовательской. Но многопользовательская всегда будет многозадачной. Мы не будем погружаться в подробности терминологии, как и в подробности собственно многозадачности. Нас будет интересовать синхронизация доступа.
Поскольку процессор всего один, настоящего параллельного выполнения задач не будет. Но ОС создаст иллюзию параллелизма выполняя переключение задач. И к описанным ранее ситуациям добавится возможность нескольким задачам работать с одной и той же областью памяти, с разделяемыми данными.
То, что задачи не выполняются действительно параллельно, ничего не меняет. Сама прикладная программа не может влиять на моменты переключения задач ОС. Исключения есть, например, запрос ввода-вывода может перевести задачу в состояние ожидания до окончания ввода-вывода. Но прямого управления переключением, в современных ОС, нет.
Для синхронизации доступа используются различные способы. Они достаточно широко и подробно описаны во множестве книг и учебников. Поэтому вряд ли имеет смысл уделять дополнительное внимание. Тем не менее, давайте кратко коснемся посмотрим на один метод, который является специфическим для многозадачных ОС на однопроцессорных машинах.
Ранее я говорил, что прикладная задача не имеет возможности влиять на переключение задач. И это действительно так. Но в некоторых ОС может быть возможность временной блокировки переключения. Именно временной, так как иначе злонамеренная задача просто превратит ОС в однозадачную для собственного выполнения.
И мы можем представить примерно такой способ обеспечения безопасного доступа к разделяемым данным
Здесь внешний массив data соответствует разделяемым данным. Он изменяется где то в другом месте, в другой задаче или потоке. И мы просто вычисляем сумму элементов массива.
Кажется, что это решает все проблемы. Однако, это не совсем так так. Да, это исключает изменение обрабатываемого массива в процессе обработки. При условии, что все задачи использую такой механизм временной блокировки переключения. А это, безусловно, уже требует непосредственного участия прикладного программиста.
Но блокировка переключения задач не влияет на возможность параллельной работы самой ОС и драйверов. А значит, если массив data является буфером диска, как в наших примерах ранее, блокировка переключения задач не решит проблему. И это нужно учитывать.
Различные механизмы и примитивы синхронизации рассчитаны на параллельно выполняющиеся прикладные задачи. Точно так же, как блокировка переключения задач в нашем последнем примере. Просто они более универсальные, работающие на многопроцессорных машинах, и даже на многомашинных комплексах.
Но они не рассчитаны на работу с аппаратными или системными ресурсами, даже если не очевидно, что ресурс аппаратный. Буфер диска, который мы рассматривали ранее, является как раз таким не очевидным разделяемым системным или аппаратным ресурсом. Точнее, он становится таковым в момент запроса у ОС операции с диском, или при старте операции ввода-вывода при прямой работе с диском.
При этом примитивы синхронизации все таки могут использоваться для доступа к разделяемым системным (но не аппаратным!) ресурсам. Но это должно быть явно описано в документации на систему.
И именно для взаимодействия прикладных задач и потоков в многозадачных системах предназначаются средства вроде std::atomic и _Atomic, на которые некоторые ссылаются как на универсальное средство. Они вовсе не столь универсальны.
Многозадачная ОС, многоядерный процессор или многоцпроцессорная машина
На первый взгляд, ситуация ничем не отличается от однопроцессорной машины и многозадачной системы. Но на самом деле, наличие нескольких процессоров приводит к появлению довольно интересных нюансов.
Эти нюансы большей частью связаны с операционной системой. Однако, они еще и делают непригодными часть использовавшихся ранее способов получения монопольного доступа и синхронизации. В частности, блокировка переключения задач теперь бесполезна. Почему?
Дело в том, блокировка переключения задач не влияет на задачи выполняющиеся на других ядрах или процессорах. А если количество задач в системе меньше количества доступных ядер/процессоров, то переключение вообще не потребуется, но все задачи будут выполняться параллельно.
Все прочие примитивы синхронизации, равно как и std::atomic, остаются рабочими. Если конечно они реализуются ОС, не важно, на уровне ядра, или на ином. Реализация даже простейшего бинарного семафора, мы чуть позже это рассмотрим, далеко не столь простая задача.
Важно понимать, что реализация примитивов синхронизации и доступа к разделяемым данным сама требует использования разделяемых данных! Но об этом позже.
Кроме того, если многоядерный процессор или многопроцессорная машина используют кэш память и для кэширования данных (да, такое тоже бывает), то области разделяемой памяти должны быть исключены из списка кэшируемых областей. И средства ЯВУ здесь не помогут. Модификатор volatile не подразумевает отключения кэширования переменной, если кэширование данных используется процессором.
ОС для многомашинных комплексов
Общая область памяти межмашинного интерфейса отображается на адресное пространство отдельных машин без кэширования. Во всяком случае, в большинстве случаев. Многомашинные ОС усчитывают наличие такой памяти и автоматически используют синхронизацию доступа к ней.
Поэтому можно считать, что для нашей статьи многомашинный комплекс почти аналогичен многопроцессорной машине. Просто добавился еще один уровень абстракции. Данные могут быть разделяемыми между задачами в рамках одной машины, тут все совсем аналогично ранее рассмотренному. И могут быть разделяемыми между задачами на разных машинах. В этом случае ОС будет работать похожим образом, но потребуется поддержка от межмашинного интерфейса, аппаратная.
Но нужно понимать, что в многомашинном комплексе задачи в основном взаимодействуют внутри машины, а не с другими машинами. Поэтому интенсивность использования памяти межмашинного интерфейса, обычно, значительно ниже.
Переносимость и системная независимость
В наше время это довольно важные вопросы. Причем бывает, что им в жертву приносятся и вопросы быстродействия. Поэтому не удивительно, что многозадачность встраивается в языки программирования высокого уровня. Например, она есть в ADA. Появилась многопоточность и в C++.
Мы не будем сегодня глубоко погружаться в поддержку многопоточности в C++, но немного коснуться ее придется. Начиная с C++11 появился класс thread, входящий в состав std::thread. Этот класс соответствует одному потоку выполнения.
Таким образом, появилась возможность писать многопоточные приложения используя только средства языка, без погружения в тонкости многозадачности и многопоточности ОС. Жизнь прикладных программистов стала немного легче. Правда это не отменило необходимости знать общие правила построения параллельно выполняющихся процессов.
И тут возникло небольшое затруднение. Дело в том, что нужно было обеспечить и средства работы с разделяемыми объектами, и синхронизацию. Начиная с C++11 появилась std::atomic, которая была расширена в C++20. Вместе с std::memory_order это позволяет организовать контролируемый доступ к разделяемым переменным. В языке C (начиная с C11) появилось ключевое слово _Atomic.
На самом деле, существовало и предложение нагрузить дополнительным смыслом модификатор volatile. Однако, от этой идеи отказались. Поскольку смысл volatile заключается в "изменяется независимо", что совсем не одно и тоже, что "изменяется целостно".
Однако, повторюсь, эти нововведения в C/C++ относятся к многопоточным приложениям и совместному доступу к данным в таких приложениях. В работе с аппаратными ресурсами они не помогают. Равно как и в работе с системными ресурсами.
Для обеспечения атомарности нужна атомарность
Давайте посмотрим на простейший пример реализации бинарного семафора (mutex). Предположим, что захват семафора осуществляет функция LockSema(). Если семафор был свободен и успешно захвачен, то работа функции завершается и программа продолжит работу. Если семафор занят, то программа будет переведена в состояние ожидания до освобождения семафора. После возобновления программы семафор будет захвачен и работа продолжится.
Состояние семафора хранит переменная целого типа. Свободному семафору соответствует равенство переменной 0, а занятому 1. Освобождение семафора осуществляет функция FreeSema(), которая просто присваивает значение 0 переменной семафора. Возобновление ожидающих семафор задач рассматривать не будем. А значит, FreeSema() будет очень простой и нам не интересной.
Давайте посмотрим на простейшую реализацию, что называется "в лоб". Причем нам придется погрузиться и в машинные команды. Я использую абстрактный процессор, который однако достаточно близок к реально существующим
В правой части иллюстрации я привел сформированный компилятором машинный код.
Сначала проверяем состояние семафора, если он занят, что запрашиваем ОС о приостановке задачи (_wait_). Если семафор свободен, сразу или после ожидания, мы его захватываем. Все кажется простым и логичным. Что может пойти не так?
Действительно, если функция LockSema расположена в ядре ОС проблем возникнуть не должно. Или могут? На самом деле, наша LockSema после компиляции превратится в множество машинных команд. Причем между командой считывания семафора и командой установки (захвата) семофора будет выполнено несколько команд, даже если семафор свободен.
И тут мы должны вспомнить про прерывания. Хоть мы и в ядре ОС, прерывания не запрещены по умолчанию. Выполнение машинной команды, обычно, прервано быть не может. Но между выполнением отдельных команд может произойти переход к обработчику прерывания. И у нас таких критичных точек оказывается много.
Если процессор один, то прерывание, скорее всего (специфические случаи не будем рассматривать) ничего не испортит. По той причине, что ядро ОС прервано быть может, но не прикладной задачей.
А если ядер или процессоров несколько? Возникновение прерывания будет безопасным и в том случае. Но опасность подкрадывается с другой стороны. Ядро ОС выполняется одним из ядер или процессоров, но другие ядра или процессоры не останавливаются при выполнении кода ядра. А значит, мы должны учитывать уже циклы системной шины, и шины памяти.
Команда tst (проверка) сформирует цикл чтения памяти и освободит шину. Захват семафора выполняет команда mov, но до ее выполнения еще далеко. И на шине могут быть сформированы циклы другими ядрами, в том числе, обращающиеся к нашей переменной sema для записи, изменения состояния семафора.
Между проверкой и захватом семафора. То есть, нельзя исключить ситуации, что семафор был свободен на момент проверки, но на момент захвата оказался уже занятым процессом другого ядра. И мы об этом узнать просто не сможем. А это не просто ошибка, это большая проблема.
Помните, я говорил, что примитивы синхронизации доступа к разделяемым данным сами требуют использования разделяемых данных для своей реализации. И теперь это хорошо видно. Переменная хранящая состояние семафора является разделяемыми данными. И у нас нет способа синхронизации доступа к ней.
Но ведь семафоры работают, и работают успешно! Значит какое то решение есть. Действительно есть, и довольно простое. Но для этого нужно знать, в том числе, то, что я описывал в статье про циклы чтение-модификация запись. И некоторые особенности архитектуры процессоров.
Давайте сделаем небольшое изменение в работе нашего семафора. Пусть занятости семафора соответствует любое отличное от нуля значение sema. Свободному семафору, как и раньше, будет соответствовать ноль. Мелочи? Нет. И сейчас вы это увидите. Но мы сделаем еще одно, кажущееся безумным, на первый взгляд, изменение в алгоритме работы LockSema(). Мы будем захватывать семафор до проверки!
Операции sema++ соответствует машинная команда inc (инкремент). Эта команда формирует на шине цикл чтение-модификация-запись. Однако, поскольку это одна команда, ее выполнение не может быть прервано. Как не может быть прерван и сформированный ей цикл шины, даже в многопроцессорной конфигурации, даже в многомашинном комплексе (при обращении к общей памяти в межмашинном интерфейсе). Эта операция атомарна, что нам и нужно.
Мы увеличиваем на 1 значение переменной-семафора. Если семафор свободен это соответствует его захвату. Если он уже занят, это просто ничего не изменит, так как занятому состоянию соответствует любое отличное от нуля значение переменной. Переполнение переменной оставим в стороне, у нас же просто пример.
Вот теперь, мы уже можем спокойно делать все остальное, самую главную операцию, причем именно атомарно, мы уже выполнили. Если у нас sema стала равена 1, то мы выполнили захват свободного семафора и все в порядке. Если sema не 1, то мы попытались захватить уже занятый семафор, а значит, переходим к ожиданию.
Мы смогли реализовать атомарную функцию захвата семафора без использования примитивов синхронизации. Правда для этого пришлось узнать немного больше, выйти за рамки просто программирования.
Но всегда ли это решение будет верным? Почти. Во первых, очень важным является то, что sema ячейка памяти. А значит, она не может быть изменена какими либо аппаратными событиями, кроме явной операции записи. Во вторых, область памяти sema не должна кэшироваться, если процессор использует кэширование данных.
Но это пример важен и с несколько иной стороны. Сегодня есть концепция микроядра. И работа с семафорами, тем более, пользовательскими, к функциям ядра не относится. Она должна выполняться на пользовательском уровне. И вот такая реализация позволяет это сделать. Более того, мы можем разместить работу с семафорами в общесистемной пользовательской бибилиотеке, которая будет отображаться в адресное пространство каждой прикладной задачи. И будет выполняться не просто на уровне пользователя, но и в его адресном пространстве.
Обратите внимание, что здесь нам нисколько не поможет atomic!
Когда volatile не работает
Давайте рассмотрим простой пример, я его приводил не раз. Но поскольку он нагляден, а не только прост, кратко расскажу еще раз.
Предположим, что у нас есть аппаратный таймер. У этого таймера есть регистр-счетчик, который увеличивает (уменьшает, не суть важно) свое значение при поступлении тактовых импульсов от аппаратного же генератора. Пусть этому регистру-счетчику соответствует переменная
extern int volatile timer;
Так же предположим, что нам необходимо увеличить содержимое этого регистра ровно на единицу. Учитывая все, что мы сегодня уже узнали, смело пишем
timer++;
Все? Уверены? Никаких проблем? Действительно, после компилятора получим одну команду, которая, как мы помним, обеспечит атомарность. И цикл шины тоже будет атомарный. В чем же подвох? Можете даже запретить прерывания, это ничего не изменит.
Дело в том, что наш таймер является независимым аппаратным устройством. И его регистр-счетчик может совершенно не зависеть от циклов шины. volatile запрещает оптимизацию доступа к timer, поэтому будет обращение именно к регистру. Но инкремент будет выполнен внутри АЛУ. То есть, содержимое регистра будет прочитано во внутренний рабочий регистр АЛУ, содержимое регистра АЛУ будет увеличено, после чего произойдет запись в регистр-счетчик.
Но тактовый импульс может поступить на таймер в любой момент. И возможна ситуация, когда он поступит между чтением и записью. А значит, содержимое регистра будет увеличено не на 1, а на 2. И атомарность цикла шины тут совершенно не поможет. Мелочь, но иногда может оказаться критичным. Вероятность зависит от многих фаторов. И по закону подлости такое произойдет именно в самый ответственный момент, при сдаче объекта заказчику...
Может показаться, что ситуацию исправит аппаратный учет цикла чтение-модификация-запись и временная блокировка приращения счетчика от тактовых импульсов на время цикла шины. Однако, это всего лишь немного сдвинет во времени проявление ошибки.
И volatile есть, и операция атомарная, а результат может быть неверным. Причем здесь нет ошибки или небрежности программиста. Это особенность работы таймера, только и всего.
Кстати, ничего не изменит и увеличение/уменьшение на другое число. То есть
timer += 10;
тоже является атомарной операцией, правда не во всех процессорах. Так как команды add #imm,mem (атомарной) нет в процессорах с аккумуляторной архитектурой. Но возникновения ошибки не исключает.
Другой пример это тот самый буфер для работы с диском. Использование модификатора volatile для его описания решает проблему с оптимизатором, но не решает проблемы аппаратного изменения содержимого буфера циклами ПДП. Не нравится ПДП? Буфер может быть областью памяти для считывания результатов асинхронного измерения чего-либо внешним устройством, работающем в реальном времени.
Причем здесь не поможет не только volatile, но и любые (почти) ухищрения со стороны программиста. Спасет только аппаратная реализация синхронизации. Помните HSYNC и VSYNC для CGA мониторов? Это как раз один из методов аппаратной синхронизации.
Заключение
Мы сегодня коснулись лишь малой части вопросов и проблем, возникающих на стыке аппаратного и программного. Да и то вскользь. На самом деле, это очень большая и интересная тема.