DevOps, как и другие современные процессы, требует тщательной интеграции ключевых показателей эффективности (KPI). Правильные метрики могут гарантировать, что приложения работают с максимальной пользой.
Сегодня DevOps широко рассматривается как важный компонент процесса доставки и развертывания программных продуктов. Ключевые процессы DevOps участвуют во всем — от обеспечения безопасности до поддержки приложений.
Даже лучшие практики DevOps не гарантируют качество, а иногда могут даже вызвать больше проблем, если не интегрированы должным образом. Стремясь как можно быстрее доставить программное обеспечение на рынок, компании рискуют получить много ошибок, которые будут обнаружены конечными пользователями
DevOps, как и другие современные процессы, требует тщательной интеграции ключевых показателей эффективности (KPI). Правильные метрики могут гарантировать, что приложения работают с максимальной пользой.
Рассмотрим основные показатели KPI, которые используются на практике:
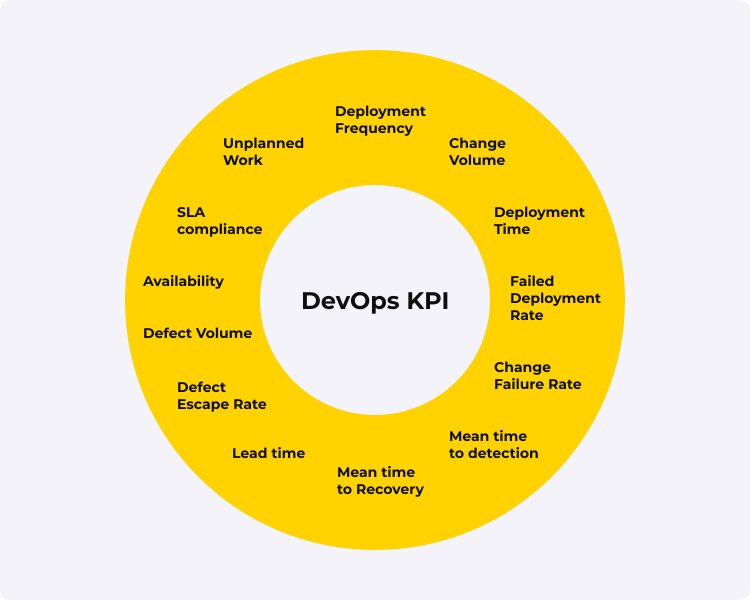
► Частота развертывания (Deployment Frequency)
Deployment Frequency обозначает частоту запуска новых функций или возможностей. Частота может быть измерена на ежедневной или еженедельной основе. Многие организации предпочитают ежедневно отслеживать развертывание, это довольно удобно с точки зрения повышения эффективности.
В идеале, показатели частоты либо будут оставаться стабильными во времени, либо будут наблюдаться небольшие и устойчивые увеличения. Любое внезапное снижение частоты развертывания может указывать на узкие места в существующем рабочем процессе.
Увеличение количество развертываний лучше, но только до определенного момента. Если высокая частота приводит к увеличению времени развертывания или более высокой частоте и количеству отказов, возможно, необходимо снизить частоту развертывания до тех пор, пока существующие проблемы не будут решены.
► Объем изменений (Change Volume)
Этот показатель тесно связан с частотой развертывания и определяет количество новых пользовательских историй или изменений кода, которые команда DevOps предоставляет с каждым выпуском или за определенный период времени. Этот KPI помогает измерить ценность развертывания для конечных пользователей, а также то, думает ли команда атомарно об изменениях или все еще думает о больших, сложных развертываниях, которые часто встречаются в разработке Waterfall.
Хотя большой объем изменений может быть признаком эффективного итеративного подхода к продукту, он также может быть индикатором слишком узкой нарезки проекта и изменений, происходящих исключительно ради изменений. Команды должны быть осторожны, чтобы не уделять слишком много времени частым изменениям кода, несущественным для их организации или конечных пользователей.
► Время развертывания (Deployment Time)
Значительное увеличение времени развертывания требует дальнейшего изучения, особенно если оно сопровождается уменьшением объема развертывания. Несмотря на то, что короткое время развертывания имеет важное значение, оно не должно идти за счет корректности релизов. Увеличение числа ошибок может указывать на то, что развертывания происходят слишком быстро.
► Частота неудачных развертываний (Failed Deployment Rate)
Этот показатель, иногда называемый средним временем до отказа, определяет, как часто развертывания вызывают сбои или другие проблемы.
Это число должно быть как можно ниже. На процент неудачных развертываний часто ссылаются наряду с объемом изменений. Низкий объем изменений наряду с увеличением частоты неудачных развертываний может указывать на проблему где-то в рабочем процессе.
► Частота отказов (Change Failure Rate)
Низкая частота отказов позволяет предположить, что развертывания происходят быстро и регулярно. И, наоборот, высокая частота отказов означает плохую стабильность приложений, что может привести к проблемам у конечных пользователей.
► Среднее время до обнаружения (Mean time to discovery)
Низкая частота отказов изменений не всегда означает, что с приложением все в порядке.
Хотя идеальное решение состоит в том, чтобы минимизировать или даже искоренить неудачные изменения, важно быстро обнаруживать сбои, если они происходят. Время на обнаружение может определить, адекватны ли текущие меры по реагированию. Длительное время обнаружения может привести к появлению узких мест, способных нарушить весь рабочий процесс.
► Среднее время между сбоями (Mean Time Between Failures)
Среднее время наработки на отказ (MTBF) является метрикой надежности и доступности. Она используется для измерения способности системы или компонента выполнять свои требуемые функции в установленных условиях в течение определенного периода времени. Кроме того, MTBF позволяет команде разработчиков DevOps измерить степень работоспособности системы или ее компонент.
Чтобы рассчитать MTBF, команде разработчиков DevOps необходимо посмотреть, сколько времени прошло между отказами системы во время повседневных операций. MTBF обычно измеряется в часах, и средняя MTBF для каждого оборудования может варьироваться.
Команда DevOps должна стремиться поддерживать как можно более высокий MTBF независимо от системы или компонента, которые измеряются. Имея данные MTBF, команда DevOps может точно предсказать уровни надежности и доступности сервиса.
► Среднее время восстановления (Mean Time to Recovery)
Среднее время восстановления (MTTR) — это важный показатель, который указывает на способность адекватно реагировать на выявленные проблемы. Быстрое обнаружение мало что значит, если за ним не следует столь же быстрое восстановление. MTTR является одним из наиболее известных и часто упоминаемых ключевых показателей эффективности DevOps.
► Скорость ухода от ошибок (Defect Escape Rate)
Каждое развертывание программного обеспечения сопряжено с риском появления новых ошибок. Они могут не быть обнаружены, пока тестирование не будет завершено. Хуже того, они могут быть найдены конечным пользователем.
Ошибки являются естественной частью процесса разработки и должны планироваться соответствующим образом. Данный показатель отражает эту реальность, признавая, что проблемы возникнут и что они должны быть обнаружены как можно раньше.
Этот параметр отслеживает, как часто ошибки обнаруживаются на этапе предварительного тестирования по сравнению с процессом производства. Эта цифра может служить ценным показателем общего качества выпусков программного обеспечения.
► Время выполнения (Lead Time)
Этот показатель может отслеживаться, начиная с инициации идеи и заканчивая развертыванием и внедрения в производство. Время выполнения отображает информацию об эффективности всего процесса разработки. Этот показатель также указывает на текущую способность удовлетворять растущие потребности
пользователей. Длительные сроки предполагают наличие узких мест, в то время как короткие сроки указывают на то, что обратная связь с пользователями происходит быстро.
Время выполнения начинает свой отсчет, когда от пользователя поступил запрос и заканчивается, когда запрос полностью выполнен. Частью Lead Time является Process Time — время за которое по факту выполнен пользовательский запрос. Отсчет начинается когда команда приступила к выполнению задачи до полного выполнения запроса.
► Объем ошибок (Defect Volume)
Эта метрика относится к показателю, указанном выше, но, вместо этого, фокусируется на фактическом объеме ошибок. Хотя некоторые проблемы следует ожидать, внезапное увеличение может говорить о возможных проблемах. Большой объем ошибок для конкретного приложения может указывать на проблемы с управлением данными разработки или тестирования.
► Доступность (Availability)
Доступность указывает степень простоя для данного приложения.
Это может измеряться как полной, так и частичной доступностью. При этом для планового технического обслуживания может потребоваться некоторое снижение доступности. Тщательно отслеживайте как запланированные простои, так и незапланированные отключения, помня о том, что 100-процентная доступность может оказаться невозможной.
► Соответствие SLA (SLA compliance)
Время безотказной работы приложений является важным показателем для каждой ИТ-организации. Соглашения об уровне обслуживания требуют, чтобы инфраструктура, службы и поддерживающие приложения соответствовали высокой цели доступности. Сервисы должны быть в максимально возможной степени подключены доступны пользователям, что позволяет достигать SLA 99,99%.
► Незапланированная работа (Unplanned Work)
Этот показатель помогает отслеживать как качество выпусков программного обеспечения, так и общую продуктивность команды DevOps. Определите объем работы для выпуска в начале цикла DevOps и сравните его с фактической работой, необходимой для завершения выпуска. Помните о незапланированной работе, которая будет завершена, а также о работе, которая началась, а затем была прекращена, и о процессах, которые еще не завершены.
Чем больше времени разработчики и администраторы тратят на незапланированную работу, такую как устранение ошибок в производственной среде, тем выше вероятность возникновения проблемы, присущей подходу DevOps. Возможно, существует недостаток тестирования или разрыв между средами разработки, тестирования и производства.
Когда команды проводят много времени в борьбе с непредвиденными «пожарами», общая производительность снижается, а риск выгорания ИТ возрастает.
Вывод
При отслеживании ключевых метрик DevOps необходимо сосредоточится не на плюсах или минусах, основанных на каком-либо одном показателе, а скорее на статистике, которую эти метрики показывают когда совместно анализируются. Результат, который кажется проблематичным сам по себе, может выглядеть совершенно иначе при анализе вместе с дополнительными данными.
Тщательное отслеживание ключевых показателей эффективности, о которых говорилось выше, может обеспечить не только повышение эффективности разработки и производства, но, что еще важнее, наилучшее взаимодействие с конечным пользователем.
Используя метрики DevOps вы сможете увидеть значительные улучшения в развертывании приложений и обратной связи с конечными пользователями.
Узнайте больше об аутсорсинге DevOps-услуг.
#devops #разработка приложений #development #приложения