Китайский стартап Enflame выпустил уже второе поколение ИИ-чипов Deep Thinking Unit (DTU 2.0), предназначенных для обработки больших объёмов данных в задачах машинного обучения. Реализованные в DTU подходы востребованы в облачных центрах обработки данных, предоставляющих услуги по глубокому обучению нейронных сетей. Деньги на разработку вложили правительство и отраслевые инвесторы, крупнейшим из которых стал интернет-гигант Tencent.
Несмотря на то, что чип DTU 2.0 был анонсирован только в июле, на сайте Enflame уже представлены изделия на его основе, позволяющие эффективно снизить затраты на ускорение ИИ-приложений, обеспечивая при этом лучшую производительность чем решения построенные на GPU. Впрочем, в случае Китая важна ещё и независимость от западных игроков. Пекин стремится к 2030 году стать мировым лидером в области ИИ и, по прогнозам отраслевых аналитиков, вложит не меньше $30 млрд. в связанные с этим исследования и разработки.
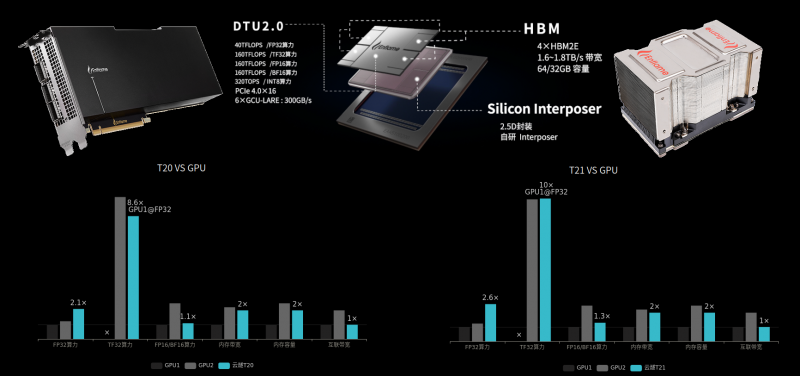
Ускоритель CloudBlazer T20, выполненный в виде PCIe-карты поддерживает работу с разнообразными моделями и сценариями обучения, а также обладает гибкими возможностями масштабирования и совместим с существующей экосистемой открытого ПО. Модуль CloudBlazer T21 обладает сходными функциональными возможностями, но выполнен в форм-факторе OAM. Согласно Enflame, в новом поколении чипов DTU 2.0 удалось заметно поднять производительность по сравнению с DTU 1.0, выпущенными пару лет назад. Также появилась и более скромная версия Cloudblazer i10 для задач инференса.
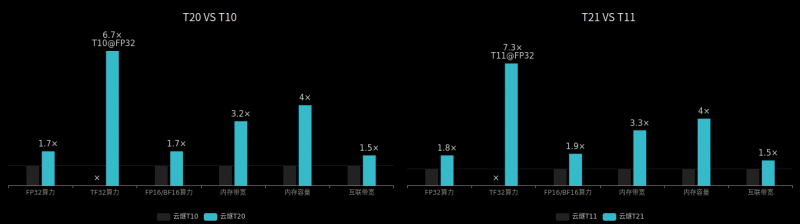
Если версия 1.0 обеспечивала до 20 Тфлопс FP32 и 80 Тфлопс FP16/BF16, то 2.0 предлагает уже до 40 Тфлопс FP32 и 160 Тфлопс FP16/BF16/TF32. Это соответствующим образом сказалось и на конечных изделиях, продемонстрировавших прирост скорости работы от 1,5 до 7,3 раз в различных вычислительных операциях. Производительность CloudBlazer T20 достигает 33 Тфлопс FP32 при энергопотреблении порядка 300 Вт, а CloudBlazer T21 демонстрирует 40 Тфлопс FP32 при потреблении в 400 Вт.
Увы, Enflame пока что не готова делиться подробностями о DTU 2.0. Компания сообщила лишь о том, что чипы получили память HBM2e, что дало трёхкратное увеличение пропускной способности и четырёхкратное увеличение ёмкости. Зато на Hot Chips 33 компания рассказала о DTU 1.0. Учитывая, что в новинке развиты идеи, заложенные в предыдущей версии, эта информация позволяет получить некоторое предварительное представление о ней.
DTU 1.0 — это система на кристалле (SoC), в состав которой входят 32 ИИ-ядра, собранных в четыре кластера, 40 движков передачи данных, четыре блока высокоскоростного интерконнекта, двухканальный контроллер памяти HBM2 с пропускной способностью до 512 Гбайт/c, а также интерфейс PCIe 4.0 x16. 1,25-ГГц чип, изготовленный по 12-нм нормам FinFET, содержит порядка 14,1 млрд. транзисторов и имеет TDP от 225 (PCIe) до 300 (OAM) Вт.
Каждое ядро (GCU-CARE 1.0) включает L1-кеш объёмом 64 Кбайт для инструкций и 256 Кбайт для данных, DMA-движок, общий ALU-блок, три регистровых файла и 256 тензорных блоков шириной 1024 бит. Оно способно одновременно выполнять четыре 16- или 8-бит MAC-операции или же одну 32-бит. Возможна и работа с FP64, но ценой существенного снижения производительности.
32 из 256 блоков могут выполнять общие скалярные и векторные операции, а 32, 64 или 128 можно задействовать для векторных MAC-операций. Но предполагается, что основными всё же будут тензорные и матричные операции, преимущественно свёртки. Особенность архитектуры в том, что, во-первых, в пределах ядра можно произвольно преобразовывать тензоры, а также выбирать их размерности, а, во-вторых, возможны параллельные вычисления над различными форматами данных.
Сами ядра имеют архитектуру VLIW, но компания не уточнят её особенности. Говорится лишь о том, что, в частности, ядро способно самостоятельно находить ненужные инструкции (например, при отличии в формате данных) и пропускать их. Для такой массивно-параллельной архитектуры реализован собственный движок (GCU-DARE 1.0) для асинхронного обмена данными и их преобразования из одного формата в другой на лету.
Масштабирование реализовано с помощью проприетарного интерконнекта GCU-LARE 1.0. Без кеш-когерентности, зато работающего на скорости 200 Гбайт/с в дуплексе — у каждого чипа есть по четыре 25-Гбайт/с LARE-линии. Внутри одного узла можно бесшовно объединить 8 или 16 ускорителей (мостиками и кабелями), получив задержку менее 1 мкс.
В одну стойку можно уместить до 64 ускорителей, а несколько стоек объединить в 2D-тор. Enflame утверждает, что даже при использовании 160 ускорителей в 20 шасси масштабирование производительности получается достаточно линейным и составляет в среднем около 85% от теоретического максимума. Это весьма важно для обучения массивных языковых моделей, которыми и занимаются ключевые заказчики Enflame.