Зачастую для визуализации и анализа распределения дискретных величин требуется особое разбиение на группы значений. Например, это может понадобится при оценке изменчивости фактора с течением времени (PSI тесты), измерения расстояния между распределениями Кульбака-Лейблера.
Почему просто не взять распределение по всем значениям? Хотя бы потому что отсутствие некого значения в новом распределении делает вероятность равной нулю и невозможным получить конечное число в формулах с таким знаменателем или вычислением логарифма.
Фактически нашей целью будет вычисление групп категорий с "немаленьким" представительством значений нашей случайной величины (зададим его сами). Для этого сгруппируем все значения по убыванию их относительной встречаемости в выборке и для каждого будем проверять соответствие заданному порогу, если меньше объединим с последующим и так до конца. Если на последнем шаге останется группа с относительной долей встречаемости меньше порога, то добавим ее в предыдущую.
Зададим произвольный набор значений:
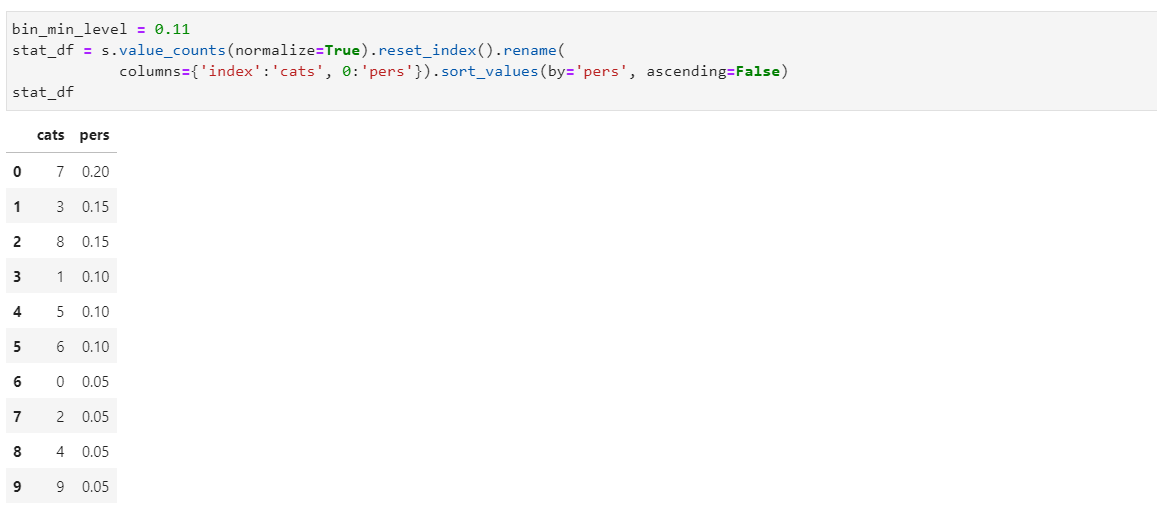
Установим минимальный порог и выведем частоту встречаемости значений с использованием метода value_counts с параметром normalize=True:
Объединение в группы можно реализовать, например, так:
Но с учетом того, что мы работаем с объектами из библиотеки Pandas удобнее могло быть использование немного другого способа, заключающегося не в создании списка списков, а разметки групп значений в новой столбце:
Теперь, если нам потребуется сравнить распределение нашей случайной величины с другой, принимающей значения из того же множества, можно отобразить ее на новые группы и, возможно, опять скорректировать их в соответствии с указанным алгоритмом:
Распределение не удовлетворяет нашему критерию в не менее 11% значений в каждой группе:
Повторяем манипуляции и получаем новые группы:
Теперь объединим новое разбиение со старым:
На эту таблицу теперь можно опираться, чтобы трансформировать распределения наших случайных величин. Для этого потребуется объединить каждую из них с датафреймом по столбцу "first" и выбрать "third". Так как операцию merge можно производить только с именованными сериями (а мы имя первой не дали, более того потом ее затерли) продемонстрируем результаты для второй:
Теперь приведем в порядок код, а повторы объединим в функцию. Также зададим имя для первой серии:
Теперь p и q можно использовать для подсчета расстояния Кульбака-Лейблера:



















