Это вторая часть, если вы не видели первую, то настоятельно рекомендую прочитать — Веб-парсинг на Python. Часть 1, — а затем возвращаться сюда!

Автоматический парсинг таблиц
HTML-таблицы все еще широко применяются на сайтах. Мы можем воспользоваться этим, поскольку они обычно структурированы и хорошо отформатированы.
Используя в качестве примера список самых продаваемых альбомов из Википедии, мы извлечем все значения в датафрейм pandas. Это простой пример, но со всеми данными нужно обращаться так, как если бы они были получены из набора данных.
Мы начинаем с поиска таблицы и перебора всех строк tr. Для каждой из них мы ищем ячейки td или th. Дальше удаляем заметки и сворачиваемое содержимое из таблиц (необязательный шаг). Затем добавляем вырезанный текст ячейки в строку и строку — в окончательный вывод.
Другой способ – использовать pandas и напрямую импортировать HTML, как показано ниже. При таком подходе все будет сделано за нас: первая строка будет соответствовать заголовкам, а остальные будут вставлены как контент с правильным типом. read_html() возвращает массив, поэтому мы берем первый элемент, а затем удаляем столбец, у которого нет содержимого.
Попав в датафрейм, мы можем выполнить любую операцию. Например — упорядочить по продажам, поскольку pandas преобразовала некоторые столбцы в числа. Или вывести сумму продаж. Здесь это не очень полезно, но идея понятна.
Извлечение информации не из HTML, а из метаданных
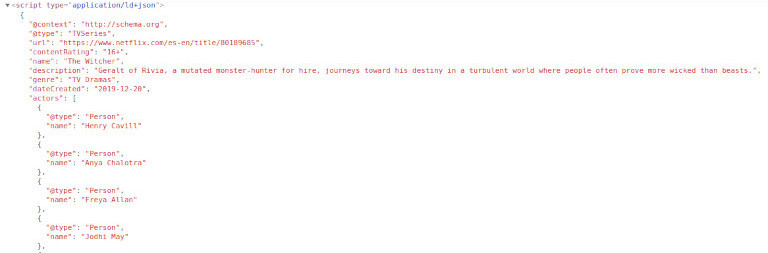
Как было замечено ранее, есть способы получить важные данные, не полагаясь на визуальный контент. Давайте рассмотрим пример с «Ведьмаком» от Netflix. Мы попробуем получить список актеров. Легко, правда?
Что, если бы мы сказали вам, что актеров и актрис четырнадцать? Вы попытаетесь получить все имена? Не прокручивайте дальше, если хотите попробовать самостоятельно.
Помните: актеров больше, чем кажется на первый взгляд. Вы знаете троих – поищите их в исходном HTML. Честно говоря, внизу есть еще одно место, где показан весь состав, но постарайтесь его избегать.
Netflix включает фрагмент Schema.org со списком актеров и актрис и многими другими данными. Как и в примере с YouTube, иногда удобнее использовать этот подход. Например, даты обычно отображаются в «машинном» формате, который более удобен при парсинге.
Разберем следующий пример, используя Instagram-профиль Билли Айлиш. После посещения нескольких страниц вы будете перенаправлены на страницу входа. Будьте осторожны при парсинге Instagram и используйте для тестирования локальный HTML-код.
Обычным подходом будет поиск класса, в нашем случае — Y8-fY. Мы не рекомендуем использовать эти классы, поскольку они, вероятно, изменятся. Судя по виду, они созданы автоматически. Многие современные веб-сайты используют подобный CSS, который генерируется при каждом изменении. Для нас это означает, что мы не можем полагаться на эти классы.
План Б: header ul > li, верно? Это сработает. Но для этого нам нужен рендеринг JavaScript, поскольку он отсутствует при первой загрузке. А как было сказано ранее, этого следует избегать.
Взгляните на исходный HTML. Заголовок и описание включают подписчиков, подписки и количество постов. Это может быть проблемой, поскольку они имеют строковый формат, но мы можем с этим справиться. Если мы хотим только эти данные, нам не понадобится headless-браузер. Отлично!
Скрытая информация о продукте в онлайн-магазине
Комбинируя некоторые из уже рассмотренных методов, мы хотим извлечь невидимую информацию о продукте. Наш первый пример — это eCommerce-магазин Shopify – Spigen.
Мы сможем извлечь требуемые данные наверняка: не из имени продукта и не из «хлебных крошек», поскольку мы не можем быть уверены в их надежности.
В данном случае они используют itemprop и включают Product и Offer со schema.org. Вероятно, мы могли бы определить, есть ли товар на складе, просмотрев форму или кнопку «Add to cart». Но в этом нет необходимости, мы можем доверять itemprop = "availability". Что касается бренда, то мы можем использовать тот же сниппет кода, что и для YouTube, но с изменением имени свойства на «brand».
Другой пример со Shopify: nomz. Мы хотим извлечь количество оценок и среднее значение, доступные в HTML. Однако средняя оценка скрыта от просмотра с помощью CSS.
Здесь есть тег, поставленный исключительно для скринридеров, рядом с которым расположены средняя оценка и счетчик. Последние включают текст, что не является проблемой. Но мы можем добиться большего.
Это несложно, если вы изучите исходный код. Схема продукта будет первым, что вы увидите. Применяя то, чему вы научились на примере с Netflix, получите первый блок «ld + json», проанализируйте JSON, и весь контент будет доступен!
И последнее. Мы воспользуемся атрибутами данных, которые также распространены в eCommerce. Просматривая страницу с бейсбольными битами онлайн-магазина Marucci Sports, мы видим, что у каждого продукта есть несколько полезных точек данных. Цена в числовом формате, идентификатор, название продукта и категория. У нас есть все данные, которые нам могут понадобиться.
Отлично! Мы получили все данные с этой страницы. Теперь нужно проделать это со второй, а затем с третьей. Действуя постепенно, мы с большей вероятностью не нарвемся на бан.
Не забудьте преобразовать эти данные и сохранить их в CSV-файлах или в базе данных. Вложенные поля непросто экспортировать ни в один из этих форматов.
Итоги
Сегодня мы поговорили о веб-парсинге на Python. Я бы хотел, чтобы вы усвоили три урока:
- Селекторы CSS хороши для парсинга, но есть и другие варианты.
- Часть контента может быть скрыта или отсутствовать, но при этом быть доступной через метаданные.
- Старайтесь избегать загрузки JavaScript, чтобы повысить производительность.
#веб-разработка #парсинг #технологии #python #программирование #интернет