Пропуск это просто отсутствие значения. Это часто встречающееся явление в датасетах. Да, вещь не приятная и ухудшает данные. Но ничего с этим не поделать. Мы можем только с ними поработать и улучшить качество нашего датасета.
Есть такая замечательная библиотека в python как pandas. С её помощью мы и будем работать с пропусками. Так же нам понадобится библиотека numpy.
Загружаем библиотеки и создаем небольшой датасет с пропусками:
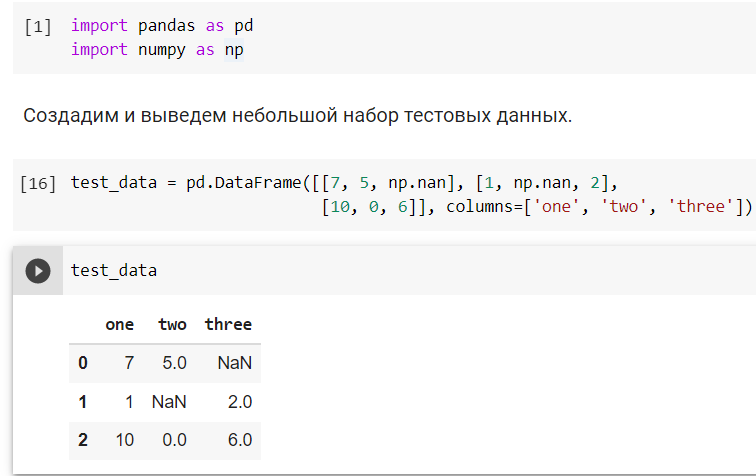
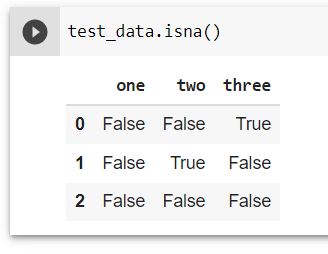
Теперь у нас есть настоящий датасет с пропусками. С ним то мы и поработаем. Для начала найдём эти самые пропуски. В этом нам поможет метод .isna(). Посмотрим как это будет выглядеть:
Удаление целых столбцов или строк довольно грубое решение. Но если в столбце или строке очень много пропусков, они становятся для нас бесполезными и их можно безболезненно удалить. Здесь поможет метод .dropna(). Так мы удалим все строки/столбцы с пропусками:
Есть способ удалить определенный столбец или строку. Для этого нужно передать список индексов (номеров строк или названий столбцов) столбцов (или строк) в параметр subset:
Чаще необходимо пустые значения заменить данным. Метод fillna() заменяет пропуски константным значением:
Так же можно заменять пустые данные статистическими данными. Для этого мы и взяли библиотеку numpy - с её помощью будет просто и быстро их вытащить:
- среднее значение np.mean();
- максимальное значение np.max();
- минимальное значение np.min();
- медиана np.median().
P.S. Если, нашли ошибки, недочёты или хотите дополнить сказанное, всегда рада конструктивному мнению специалистов.